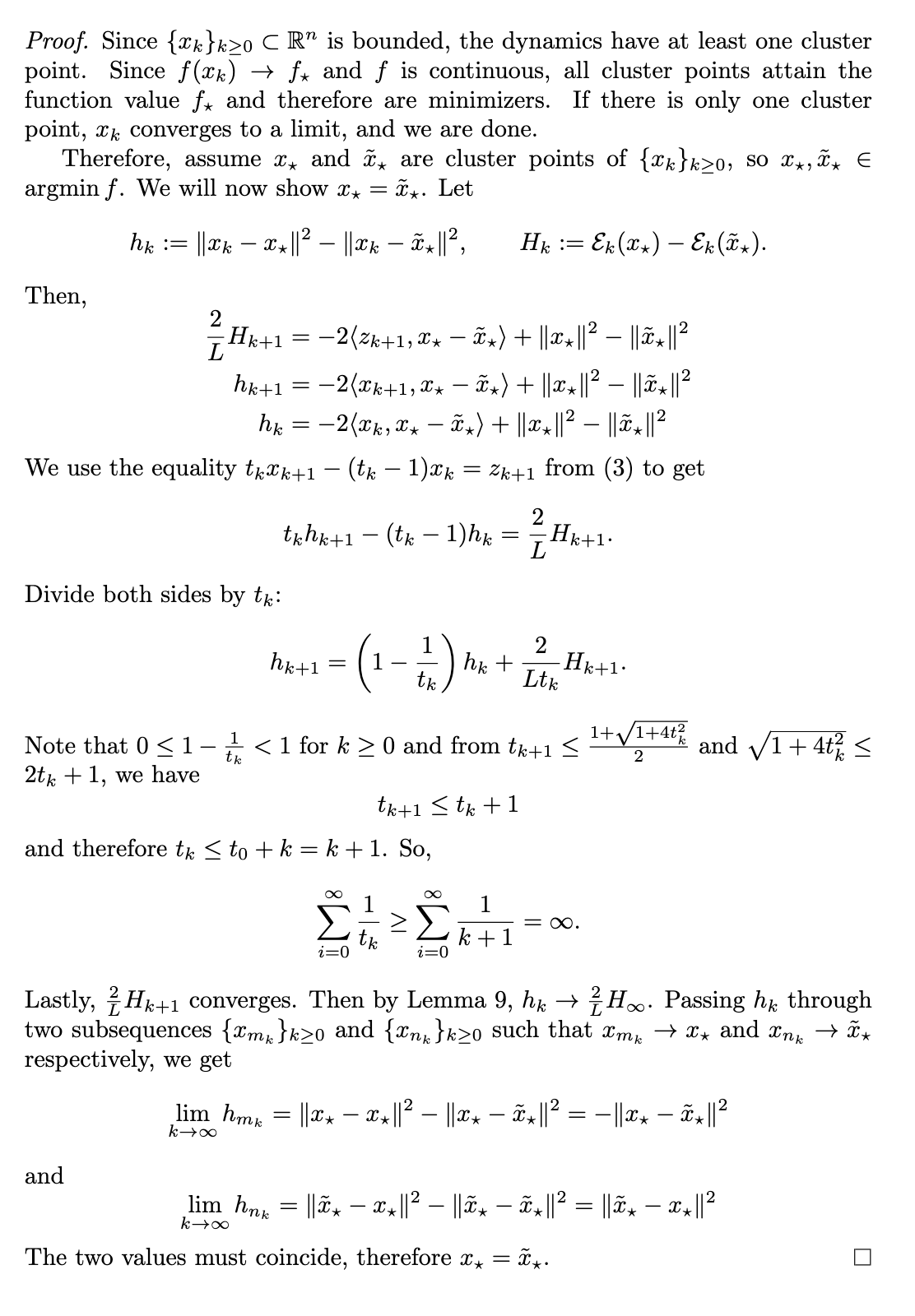Professor of Mathematics at UCLA. Interested in deep learning and optimization.
Los Angeles, CA
Joined March 2019
- Tweets 486
- Following 364
- Followers 8,884
- Likes 313

Ernest Ryu retweeted

I crossed an interesting threshold yesterday, which I think many other mathematicians have been crossing recently as well. In the middle of trying to prove a result, I identified a statement that looked true and that would, if true, be useful to me. 1/3
Another AI-assisted proof. This time in optimal transport / convex analysis by @AdilSlm
This report details the interactions with the LLM and is a very informative case study on how to work together with ChatGPT.

100% agree on the productivity boost. One just needs patience to correct mistakes, which are more subtle than before imo.
I had a nice interaction with GPT-5-pro while proving a convex analysis lemma: arxiv.org/abs/2510.26647
The model didn’t write the full proof, but the interaction was interesting enough for me to write a short report about it. The report illustrates both the productivity gain and the need for careful proof-checking. The model’s contributions are in blue, and the full chat is in the Appendix. You will see my prompts and how I think, so, no judgement please :)
The problem itself has an history in optimal transport (see intro) and comes from a question I was discussing with some UCLA math professors last summer. Simpler than @ErnestRyu's recent result imo, but still very useful in optimal transport!

I don’t know what the endgame will look like. Whether an LLM will one day autonomously prove a major unsolved math problem remains to be seen, but I am certain that LLMs will greatly accelerate progress in mathematics. (4/4)
This will also happen in mathematics. One by one, different fields will begin to pick the low-hanging fruits of the LLM-assisted research era. Occasionally, there will be contributions that feel distinctly non-LLM, and those will be celebrated as flashes of human genius. (3/4)
In Chess, Magnus Carlsen said:
“There was a period … where you could very clearly see which players have been using these [AI] and which players didn't. [We] got into it … got an advantage over basically everybody … it just made us understand the game a lot better.” (2/4)
I firmly believe we are at a watershed moment in the history of mathematics. In the coming years, using LLMs for math research will become mainstream, and so will Lean formalization, made easier by LLMs. (1/4)
For reference, here are the links to the thread series:
Part I
x.com/ErnestRyu/status/19807…
Part I(b)
x.com/ErnestRyu/status/19812…
Part II
x.com/ErnestRyu/status/19816…
Part III
x.com/ErnestRyu/status/19819…
(2/2)

Preprint on using ChatGPT to resolve a 42-year-old open problem (point convergence of Nesterov’s accelerated gradient method) is out.
Mathematical results are complete, though still need to expand the discussion of historical context & prior work.
(1/2)
arxiv.org/abs/2510.23513
Thoughtful commentary. 100% agreed.

Until this morning, I've never spent time on this problem because iterate convergence is less important to me compared to convergence rates.
What's new/difficult? First, Lemma 1 and the Lyapunov function are not new and are key to prior work on this problem. The key difficulty is theorem 2.
When is it easy?
If we know that f is any reasonable function -- e.g., analytic, semialgebraic (built from polynomial pieces), or more generally (locally) definable/tame -- the theorem follows immediately, because such functions have growth near every critical point. That is:
f(x(t)) - f* >= mu * dist^p(x(t), argmin f)
for some power p and constant mu. Then, since the function gap tends to zero like 1/t^2, it quickly follows (e.g., via Opial) that x(t) converges to the minimizing set -- even at a controlled rate or 1/t^(2/p)
This class comprises essentially every nonpathological problem you see in practice. So in that sense, the result doesn't give us much information beyond the problems we care about.
But let's say you want to cover EVERY convex function. Then the proof takes more work because the convex function can be 'infinitely flat' and we lose the growth above. (See the plot.) That's when theorem 2 gives you something new.
Now the proof of theorem 2 is algebraically very clever. Things cancel in just the right way. I imagine someone who was good at ODEs could have seen this pretty quickly. I'm not one of those people.
When I attempted this problem I tried to apply Opial's lemma from convex analysis. In this context it says that since we know all cluster points of x(t) are minimizers of f, we just need to show that for any minimizer x_* of f, the the limit of the following expression exists as t approches infinity:
norm(x(t) - x_*)
It seems hard to show this directly. The main difficulty is that the term
t\dot x(t)
may not converge to zero. The cleverness in the gpt proof is the cancellation and the reformulation as the linear ODE.
So is this a significant breakthrough? While it's certainly a clever use of ODE techniques, I would say its value is more in satisfying our curiosity for answering the question: do we still get convergence for infinitely flat functions. Beyond that, the techniques do not seem to lead to new insights about other optimization algorithms.
Finally, I have been noticing more and more improvement in GPT5 for math I care about lately, specifically in basic optimization and concentration inequalities. These are areas where there is a lot of mechanical calculations that people perform again and again. These are problems that I used to hand off to graduate students when I ran out of 'calculation energy.' My bet is that openai has generated a ton of synthetic data in these areas because it's easy to create it for such problems. If you ask @littmath, they seem to have substantially less synthetic data in algebraic geometry/number theory. I'll be very curious how gpt6 performs as the situation changes.

Ernest Ryu retweeted

(1/4) An example from Ernest highlights an essential point.
a) GPT or AI can undoubtedly accelerate scientific discovery — people already know this fact
But more importantly,
b) domain knowledge still matters. You must know what the right research question is
This concludes my three-part Twitter series. Now that we have the mathematical results sufficient for a publication, I will post our work on arXiv on Monday. After a week or two of polishing the writing and gathering feedback, I’ll submit it for peer review.
14/N, N=14
Again, ChatGPT is now at the level of solving some math research questions, but you do need an expert guiding it.
I strongly encourage fellow mathematicians to try incorporating AI assistance into their workflow. It takes some getting used to, but it can be worth it.
13/N
Overall, this entire journey took just a week, less than 30 hours of my time. ChatGPT’s assistance provided a significant speedup, and without it, I would most likely have given up after three days of slow progress. (As I did in the past.)
12/N
Conclusion:
Starting from the key idea of the first tweet, we extended the convergence result to several related settings and resolved the main 42-year-old open problem, with ChatGPT doing most of the heavy lifting along the way.
11/N
They also argue that the FISTA method [Beck, Teboulle 2009] exhibits point convergence.
Check out their work when it goes public! (As far as I know, [Bot ̧ Fadili, Nguyen 2025] did not use AI tools.)
10/N
The arXiv preprint of [Bot ̧ Fadili, Nguyen 2025] will go public in a few days. They also prove weak convergence in the infinite-dimensional Hilbert space setting. (ChatGPT will now be happy.)
x.com/ErnestRyu/status/19812…
9/N
In particular, Radu Ioan Boţ, Jalal Fadili, Dang-Khoa Nguyen reached out with a preprint of their own, capitalizing on the ideas in the continuous-time proof to also establish point convergence of Nesterov 1983 and more!
@RaduIoanBot
8/N
After the initial tweet went out, several colleagues in the optimization community reached out with excitement and amusement. It was a lot of fun reconnecting with old friends. And I now have some interesting conversational material for the next optimization conference.
7/N

In 2016, Kim and Fessler introduced a variant called OGM, which improves upon NAG by a constant factor of 2. We also show that OGM exhibits point convergence.
6/N