

Assistant Professor at Robotics and Mechatronics Eng, DGIST, South Korea.
South Korea
Joined April 2019
- Tweets 7,550
- Following 2,363
- Followers 1,585
- Likes 36,495
Pinned Tweet

I've had a good opportunity to work with great friends, see you all at ICRA25 :)
[ICRA 2025] Ephemerality meets LiDAR-based Lifelong Mapping github.com/dongjae0107/ELite
Ephemerality meets LiDAR-based Lifelong Mapping piped.video/xZwzNgcHqjc?si=_X2t… @YouTube
Giseop Kim retweeted

Representation representation representation
#SpatialAI
See the SLAM Handbook Chapter 18 for my views!
github.com/SLAM-Handbook-con…

The hot topic at #ICCV2025 was World Models.
They come in different flavors — (interactive) video models, neural simulators, reconstruction models, etc. — but the overarching goal is clear: Generative AI that predict and simulate how the real world works.
Giseop Kim retweeted

The hot topic at #ICCV2025 was World Models.
They come in different flavors — (interactive) video models, neural simulators, reconstruction models, etc. — but the overarching goal is clear: Generative AI that predict and simulate how the real world works.

Giseop Kim retweeted

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...

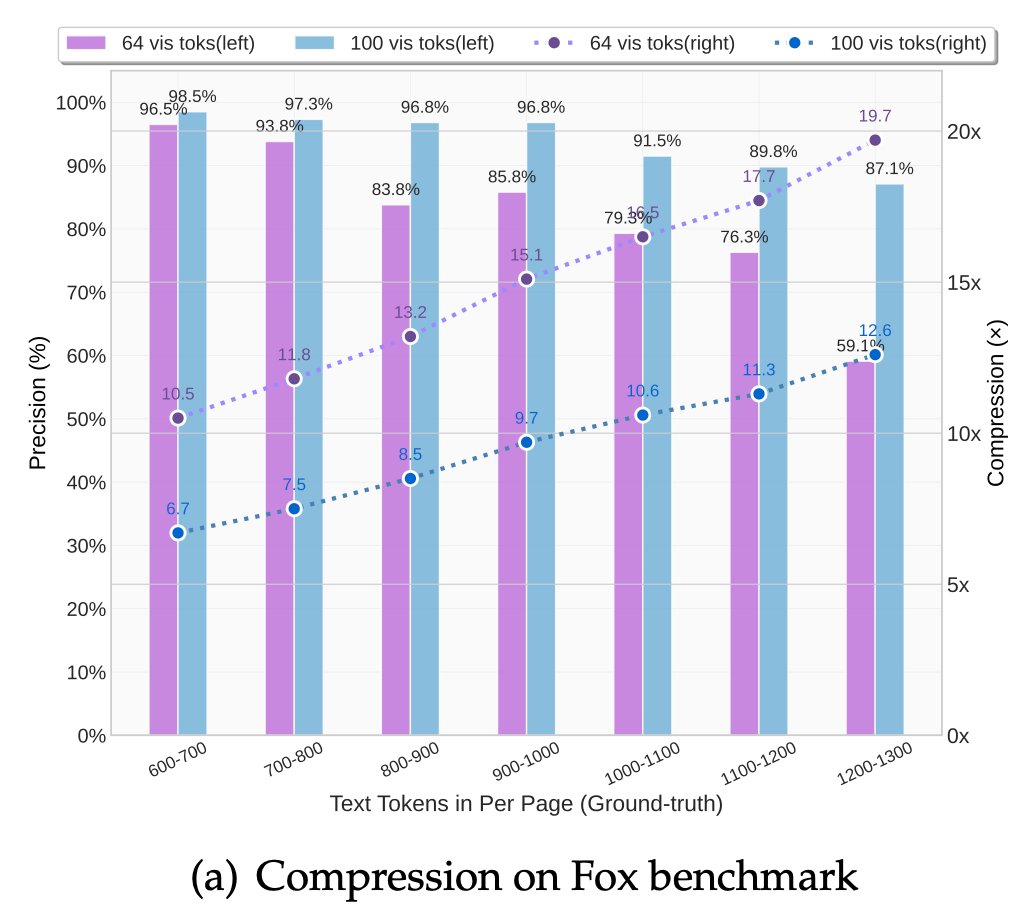
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning


Giseop Kim retweeted
A reminder that accurate motion estimation sparse visual SLAM has been in the domain of industry for many years now, and what you might often see in academic papers as the "state of the art" is fairly meaningless. (From @pesarlin.bsky.social)


Giseop Kim retweeted

Towards the Next Generation of 3D Reconstruction
@Parskatt PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
liu.diva-portal.org/smash/re…




We also release some LaTeX sty and bib files used in the handbook. If you are writing an ICRA paper on SLAM, these should be useful. Visit our GitHub repo for details:
github.com/SLAM-Handbook-con…

We have completed the SLAM Handbook "From Localization and Mapping to Spatial Intelligence" and released it online: asrl.utias.utoronto.ca/~tdb/… . The handbook will be published by Cambridge University Press. [1/n]
Giseop Kim retweeted

We have completed the SLAM Handbook "From Localization and Mapping to Spatial Intelligence" and released it online: asrl.utias.utoronto.ca/~tdb/… . The handbook will be published by Cambridge University Press. [1/n]

RSJ2025で発表したランチョンセミナー資料(学生&若手向け)です。自分の経験を踏まえて、国際論文を投稿するモチベやどうやって研究・執筆を進めて採択まで持っていくのかまとめました。みんなICRA&IROSに論文投稿しましょう!
speakerdeck.com/koide3/rsj20…
Giseop Kim retweeted

Better result (by GPT-5) for the prompt "Show me this room from the perspective of the webcam on the monitor that we see standing on the desk."




Giseop Kim retweeted
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.


Giseop Kim retweeted

Say hello to DINOv3 🦖🦖🦖
A major release that raises the bar of self-supervised vision foundation models.
With stunning high-resolution dense features, it’s a game-changer for vision tasks!
We scaled model size and training data, but here's what makes it special 👇




Did ICRA26 go back to 8p format, discarding 6+n?
2026.ieee-icra.org/contribut…
@ieee_ras_icra

arxiv.org/pdf/2505.18364
ImLPR is the first method to apply a vision foundation model like DINOv2 to LiDAR Place Recognition by converting point clouds into Range Image Views. It outperforms SOTA methods and shows that RIV is more effective than BEV for adapting LiDAR to vision models.
Giseop Kim retweeted

VGGT has been re-licensed to allow commercial usage. Enjoy the gift 😉😇
👉 huggingface.co/facebook/VGGT…

Our new work TRAN-D is accepted to ICCV 2025!
TRAN-D reconstructs transparent object geometry in more dynamic scenes. jeongyun0609.github.io/TRAN-…
📉39% lower MAE than baselines, with fewer views.
⚡️Scene updates in seconds with physics sim, no rescan needed!
More in the thread 👇

New IF and ranking. RA-L Q2->Q1 and IJRR Q1->Q2.
jcr.clarivate.com/jcr/
