
🎉 LongCat-Audio-Codec is officially OPEN SOURCED! 🚀
-an audio codec solution optimized specifically for Speech LLMs.
Key Breakthroughs:
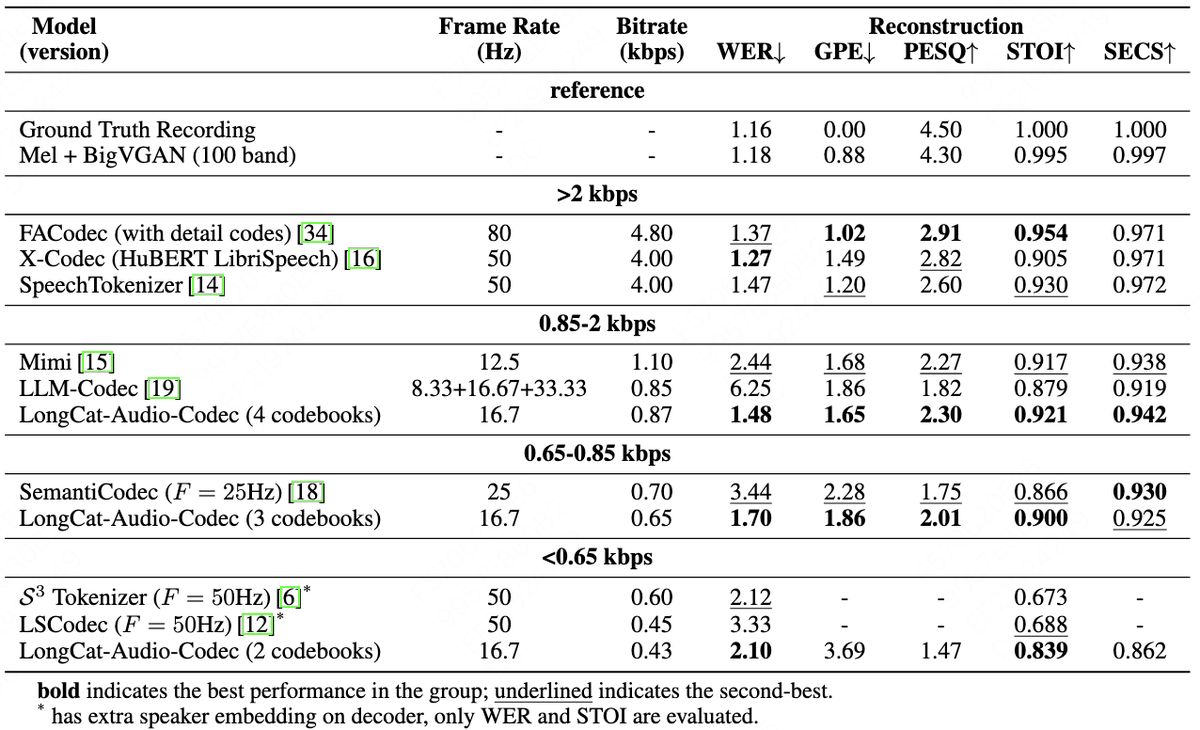
1. Dual Tokens: Semantic and Acoustic Tokens are extracted in parallel at a low frame rate (16.7Hz / 60ms).This ensures both efficient modeling and full information integrity.
2. Ultra-Efficiency: LongCat-Audio-Codec maintains high intelligibility even at an extremely low bitrate, such as 0.43 kbps.
3. Real-Time Ready: Features a low-latency streaming decoder architecture. Latency is controlled to the hundred-millisecond level for real-time interaction.
The integration of super-resolution in the decoder further enhances audio quality without extra models! This solution lowers technical barriers and optimizes resource efficiency for mobile/embedded Speech LLM deployment.
🔗 Code:
Github: github.com/meituan-longcat/L…
Huggingface: huggingface.co/meituan-longc…



Sounds exciting! 🚀 How do you think this open-sourced LongCat-Audio-Codec will impact real-time speech applications? Any plans for integrating this with existing platforms?
Oct 20, 2025 · 3:13 AM UTC