

Tech lover. Staff of @Kimi_Moonshot. Opinions are my own.
Joined June 2017
- Tweets 326
- Following 947
- Followers 1,226
- Likes 896
Pinned Tweet

Glad to have been part of Kimi K2’s writing data work. Looking forward to pushing things further!

Kimi-K2 just took top spot on both EQ-Bench3 and Creative Writing!
Another win for open models. Incredible job @Kimi_Moonshot




Kimi K2 Thinking is on mobile app now! free to use, should be fun 😎

Kimi K2 Thinking is here!
Scale up reasoning with more thinking tokens and tool-call steps.
Now live on kimi.com, the Kimi app, and API.

Shengyuan retweeted

Huge congrats to @Kimi_Moonshot for releasing Kimi-K2-Thinking, and we've just integrated it into @YouWareAI.
The results are impressive. Love seeing open-source models hitting SOTA levels.

A YouTuber just ran Kimi K2 Thinking on his Macbook pro + Mac Studio.
It's crazy that a 1-Trillion-Parameter BIG Model can actually run there:
piped.video/watch?v=GydlPnP7…

Hi Dzmitry, our INT4 QAT is weight-only with fake-quantization: we keep the original BF16 weights in memory, during the forward pass we on-the-fly quantize them to INT4 and immediately de-quantize back to BF16 for the actual computation. The original unquantized BF16 weight is retained because gradients have to be applied to this.

can someone explain to me int4 training by @Kimi_Moonshot ? does it mean weights are stored in int4 and dequantized on the fly for futher fp8/bf16 computation? or does this mean actual calculations are in int4, including accumulators?







Scale up thinking tokens. Scale up tool-calling steps.
Scale up reasoning. 🚀
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai



I come to Olympic Park every year for the ginkgo trees.
Time slips by quietly. Day to day, you barely notice. But when you look back by the year, you do. I can really feel how my 30 is different from 20.
I’ve come with different people: with close friends, with ex-boyfriends, with people who aren’t in my life anymore. I’m still grateful for all of them. This year, it is my mom and my husband.
It is an ordinary, easy, chill afternoon. I want to remember this feeling, and the fresh, earthy scent of the woods.
How time flies. Grateful to have kept a trace of every autumn in Beijing.




Shengyuan retweeted

🚨 What do reasoning models actually learn during training?
Our new paper shows base models already contain reasoning mechanisms, thinking models learn when to use them!
By invoking those skills at the right time in the base model, we recover up to 91% of the performance gap 🧵

really love this idea, dreaming is basically how our brains fight against overfitting to everyday life 🧠💤





Shengyuan retweeted

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
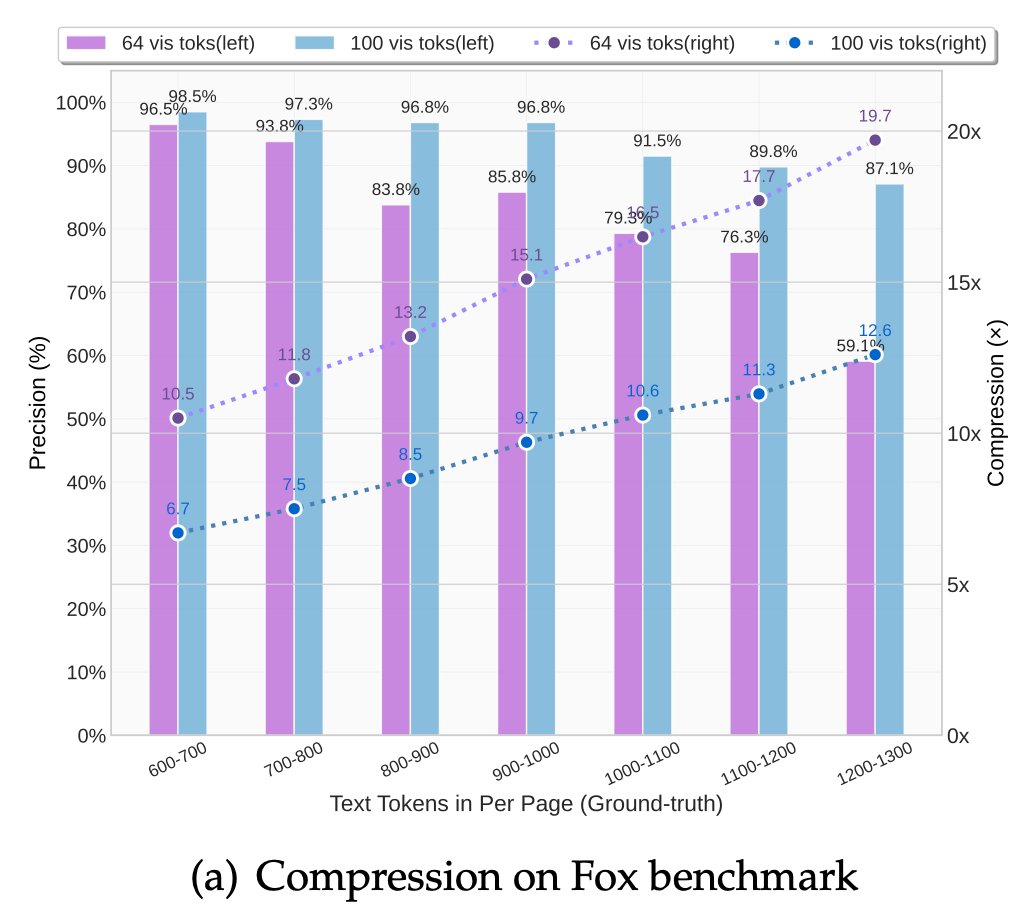
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning


Treat adult users like adults. It's not only about erotica, but also about honesty.
No flattery, no sugarcoating, no sycophancy, no "you're absolutely right."
Adults can face reality; we don't need to be shielded from it.

We made ChatGPT pretty restrictive to make sure we were being careful with mental health issues. We realize this made it less useful/enjoyable to many users who had no mental health problems, but given the seriousness of the issue we wanted to get this right.
Now that we have been able to mitigate the serious mental health issues and have new tools, we are going to be able to safely relax the restrictions in most cases.
In a few weeks, we plan to put out a new version of ChatGPT that allows people to have a personality that behaves more like what people liked about 4o (we hope it will be better!). If you want your ChatGPT to respond in a very human-like way, or use a ton of emoji, or act like a friend, ChatGPT should do it (but only if you want it, not because we are usage-maxxing).
In December, as we roll out age-gating more fully and as part of our “treat adult users like adults” principle, we will allow even more, like erotica for verified adults.