Daily tutorials and insights on DS, ML, LLMs, and RAGs • Co-founder @dailydoseofds_ • IIT Varanasi • ex-AI Engineer @ MastercardAI
Learn AI Engineering →
Joined September 2019
- Tweets 4,150
- Following 146
- Followers 53,912
- Likes 2,043

Avi Chawla retweeted
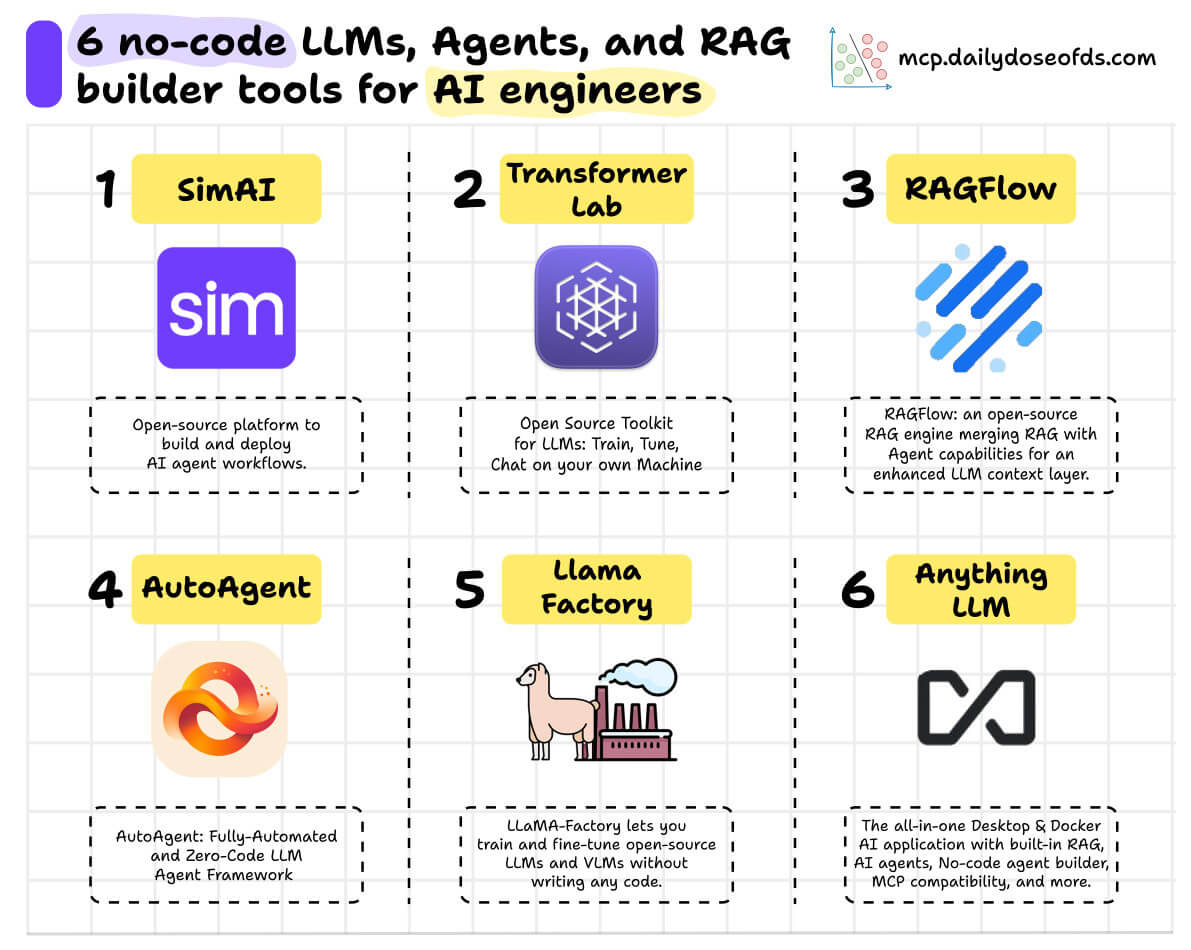
6 no-code LLM/RAG/Agent builder tools for AI engineers.
Production-grade and 100% open-source!
(find the GitHub repos in the replies)
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.

1️⃣ Sim AI
A drag-and-drop UI to build AI agent workflows!
Sim AI is a lightweight, user-friendly platform that makes creating AI agent workflows accessible to everyone.
Supports all major LLMs, MCP servers, vectorDBs, etc.
100% open-source with 18k stars
The video below depicts a finance assistance app created with Sim and connected to Telegram in minutes.
The Finance Agent uses Firecrawl for web searches and accesses stock data via Alpha Vantage's API through MCP servers.
🔗 github.com/simstudioai/sim
2️⃣ Transformer Lab
Transformer Lab is an app to experiment with LLMs:
- Train, fine-tune, or chat.
- One-click LLM download
- Drag-n-drop UI for RAG.
- Built-in logging, and more.
A 100% open-source and local!
🔗 github.com/transformerlab/tr…
3️⃣ RAGFlow
RAGFlow is a RAG engine for deep document understanding!
It lets you build enterprise-grade RAG workflows on complex docs with well-founded citations.
Supports multimodal data, deep research, etc.
100% open-source with 68k+ stars!
🔗 github.com/infiniflow/ragflo…
4️⃣ AutoAgent
AutoAgent is a zero-code framework that lets you build and deploy Agents using natural language.
- Universal LLM support
- Native self-managing Vector DB
- Function-calling and ReAct interaction modes.
100% open-source with 8k stars!
🔗 github.com/HKUDS/AutoAgent
5️⃣ Llama Factory
LLaMA-Factory lets you train and fine-tune open-source LLMs and VLMs without writing any code.
Supports 100+ models, multimodal fine-tuning, PPO, DPO, experiment tracking, and much more!
100% open-source with 62k+ stars!
🔗 github.com/hiyouga/LLaMA-Fac…
6️⃣ Anything LLM
The all-in-one AI app you were looking for.
Chat with your docs, use AI Agents, hyper-configurable, multi-user, & no frustrating setup required.
Can run locally on your computer!
100% open-source with 48k+ stars!
🔗 github.com/Mintplex-Labs/any…
👉 Over to you: What other no-code tools would you add here?

Avi Chawla retweeted
5 Agentic AI design patterns, explained visually!
Agentic behaviors allow LLMs to refine their output by incorporating self-evaluation, planning, and collaboration!
The visual depicts the 5 most popular design patterns for building AI Agents.
1️⃣ Reflection pattern
The AI reviews its own work to spot mistakes and iterate until it produces the final response.
2️⃣ Tool use pattern
Tools allow LLMs to gather more information by:
- Querying a vector database
- Executing Python scripts
- Invoking APIs, etc.
This is helpful since the LLM is not solely reliant on its internal knowledge.
3️⃣ ReAct (Reason and Act) pattern
ReAct combines the above two patterns:
- The Agent reflects on the generated outputs.
- It interacts with the world using tools.
Frameworks like CrewAI primarily use this by default.
4️⃣ Planning pattern
Instead of solving a task in one go, the AI creates a roadmap by:
- Subdividing tasks
- Outlining objectives
This strategic thinking solves tasks more effectively. In CrewAI, specify `planning=True` to use Planning.
5️⃣ Multi-Agent pattern
- There are several agents, each with a specific role and task.
- Each agent can also access tools.
All agents work together to deliver the final outcome, while delegating tasks to other agents if needed.
Those were the 5 most popular Agentic AI design patterns!
Which one do you use the most?
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.

Microsoft.
Google.
AWS.
Everyone's solving the same problem for Agents:
How to build a real-time context layer for Agents across dozens of data sources?
Airweave is an open-source context retrieval layer that solves this!
Learn how this layer differs from RAG below:

You are in an AI engineer interview at Google.
The interviewer asks:
"Our data is spread across several sources (Gmail, Drive, etc.)
How would you build a unified query engine over it?"
You: "I'll embed everything in a vector DB and do RAG."
Interview over!
Here's what you missed:
Devs treat context retrieval like a weekend project.
Their mental model is simple: "Just embed the data, store them in vector DB, and call it a day."
This works beautifully for static sources.
But the problem is that no real-world workflow looks like this.
To understand better, consider this query:
"What's blocking the Chicago office project, and when's our next meeting about it?"
Answering this single query requires searching across sources like Linear (for blockers), Calendar (for meetings), Gmail (for emails), and Slack (for discussions).
No naive RAG setup with data dumped into a vector DB can answer this!
To actually solve this problem, you'd need to think of it as building an Agentic context retrieval system with three critical layers:
> Ingestion layer:
- Connect to apps without auth headaches.
- Process different data sources properly before embedding (email vs code vs calendar).
- Detect if a source is updated and refresh embeddings (ideally, without a full refresh).
> Retrieval layer:
- Expand vague queries to infer what users actually want.
- Direct queries to the correct data sources.
- Layer multiple search strategies like semantic-based, keyword-based, graph-based.
- Ensure retrieving only what users are authorized to see.
- Weigh old vs. new retrieved info (recent data matters more, but old context still counts).
> Generation layer:
- Provide a citation-backed LLM response.
That's months of engineering before your first query works.
It's definitely a tough problem to solve...
...but this is precisely how giants like Google (in Vertex AI Search), Microsoft (in M365 products), AWS (in Amazon Q Business), etc., are solving it.
If you want to see it in practice, this approach is actually implemented in Airweave, a recently trending 100% open-source framework that provides the context retrieval layer for AI agents across 30+ apps and databases.
It implements everything I mentioned above:
- How to handle authentication across apps.
- How to process different data sources.
- How to gather info from multiple tools.
- How to weigh old vs. new info.
- How to detect updates and do real-time sync.
- How to generate perplexity-like citation-backed responses, and more.
For instance, to detect updates and initiate a re-sync, one might do timestamp comparisons.
But this does not tell if the content actually changed (maybe only the permission was updated), and you might still re-embed everything unnecessarily.
Airweave handles this by implementing source-specific hashing techniques like entity-level hashing, file content hashing, cursor-based syncing, etc.
You can see the full implementation on GitHub and try it yourself.
But the core insight applies regardless of the framework you use:
Context retrieval for Agents is an infrastructure problem, not an embedding problem.
You need to build for continuous sync, intelligent chunking, and hybrid search from day one.
I have shared the Airweave repo in the replies!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
You are in an AI engineer interview at Google.
The interviewer asks:
"Our data is spread across several sources (Gmail, Drive, etc.)
How would you build a unified query engine over it?"
You: "I'll embed everything in a vector DB and do RAG."
Interview over!
Here's what you missed:
Devs treat context retrieval like a weekend project.
Their mental model is simple: "Just embed the data, store them in vector DB, and call it a day."
This works beautifully for static sources.
But the problem is that no real-world workflow looks like this.
To understand better, consider this query:
"What's blocking the Chicago office project, and when's our next meeting about it?"
Answering this single query requires searching across sources like Linear (for blockers), Calendar (for meetings), Gmail (for emails), and Slack (for discussions).
No naive RAG setup with data dumped into a vector DB can answer this!
To actually solve this problem, you'd need to think of it as building an Agentic context retrieval system with three critical layers:
> Ingestion layer:
- Connect to apps without auth headaches.
- Process different data sources properly before embedding (email vs code vs calendar).
- Detect if a source is updated and refresh embeddings (ideally, without a full refresh).
> Retrieval layer:
- Expand vague queries to infer what users actually want.
- Direct queries to the correct data sources.
- Layer multiple search strategies like semantic-based, keyword-based, graph-based.
- Ensure retrieving only what users are authorized to see.
- Weigh old vs. new retrieved info (recent data matters more, but old context still counts).
> Generation layer:
- Provide a citation-backed LLM response.
That's months of engineering before your first query works.
It's definitely a tough problem to solve...
...but this is precisely how giants like Google (in Vertex AI Search), Microsoft (in M365 products), AWS (in Amazon Q Business), etc., are solving it.
If you want to see it in practice, this approach is actually implemented in Airweave, a recently trending 100% open-source framework that provides the context retrieval layer for AI agents across 30+ apps and databases.
It implements everything I mentioned above:
- How to handle authentication across apps.
- How to process different data sources.
- How to gather info from multiple tools.
- How to weigh old vs. new info.
- How to detect updates and do real-time sync.
- How to generate perplexity-like citation-backed responses, and more.
For instance, to detect updates and initiate a re-sync, one might do timestamp comparisons.
But this does not tell if the content actually changed (maybe only the permission was updated), and you might still re-embed everything unnecessarily.
Airweave handles this by implementing source-specific hashing techniques like entity-level hashing, file content hashing, cursor-based syncing, etc.
You can see the full implementation on GitHub and try it yourself.
But the core insight applies regardless of the framework you use:
Context retrieval for Agents is an infrastructure problem, not an embedding problem.
You need to build for continuous sync, intelligent chunking, and hybrid search from day one.
I have shared the Airweave repo in the replies!
You are in an AI engineer interview at Google.
The interviewer asks:
"Our data is spread across several sources (Gmail, Drive, etc.)
How would you build a unified query engine over it?"
You: "I'll embed everything in a vector DB and do RAG."
Interview over!
Here's what you missed:
Devs treat context retrieval like a weekend project.
Their mental model is simple: "Just embed the data, store them in vector DB, and call it a day."
This works beautifully for static sources.
But the problem is that no real-world workflow looks like this.
To understand better, consider this query:
"What's blocking the Chicago office project, and when's our next meeting about it?"
Answering this single query requires searching across sources like Linear (for blockers), Calendar (for meetings), Gmail (for emails), and Slack (for discussions).
No naive RAG setup with data dumped into a vector DB can answer this!
To actually solve this problem, you'd need to think of it as building an Agentic context retrieval system with three critical layers:
> Ingestion layer:
- Connect to apps without auth headaches.
- Process different data sources properly before embedding (email vs code vs calendar).
- Detect if a source is updated and refresh embeddings (ideally, without a full refresh).
> Retrieval layer:
- Expand vague queries to infer what users actually want.
- Direct queries to the correct data sources.
- Layer multiple search strategies like semantic-based, keyword-based, graph-based.
- Ensure retrieving only what users are authorized to see.
- Weigh old vs. new retrieved info (recent data matters more, but old context still counts).
> Generation layer:
- Provide a citation-backed LLM response.
That's months of engineering before your first query works.
It's definitely a tough problem to solve...
...but this is precisely how giants like Google (in Vertex AI Search), Microsoft (in M365 products), AWS (in Amazon Q Business), etc., are solving it.
If you want to see it in practice, this approach is actually implemented in Airweave, a recently trending 100% open-source framework that provides the context retrieval layer for AI agents across 30+ apps and databases.
It implements everything I mentioned above:
- How to handle authentication across apps.
- How to process different data sources.
- How to gather info from multiple tools.
- How to weigh old vs. new info.
- How to detect updates and do real-time sync.
- How to generate perplexity-like citation-backed responses, and more.
For instance, to detect updates and initiate a re-sync, one might do timestamp comparisons.
But this does not tell if the content actually changed (maybe only the permission was updated), and you might still re-embed everything unnecessarily.
Airweave handles this by implementing source-specific hashing techniques like entity-level hashing, file content hashing, cursor-based syncing, etc.
You can see the full implementation on GitHub and try it yourself.
But the core insight applies regardless of the framework you use:
Context retrieval for Agents is an infrastructure problem, not an embedding problem.
You need to build for continuous sync, intelligent chunking, and hybrid search from day one.
I have shared the Airweave repo in the replies!
Agents forget everything after each task!
Graphiti builds a temporal knowledge graph for Agents that provides a memory layer to all interactions.
Fully open-source with 20k+ stars!
Learn how to use Graphiti MCP to connect all AI apps via a common memory layer (100% local):

If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
Graphiti GitHub repo: github.com/getzep/graphiti
(don't forget to star it ⭐)
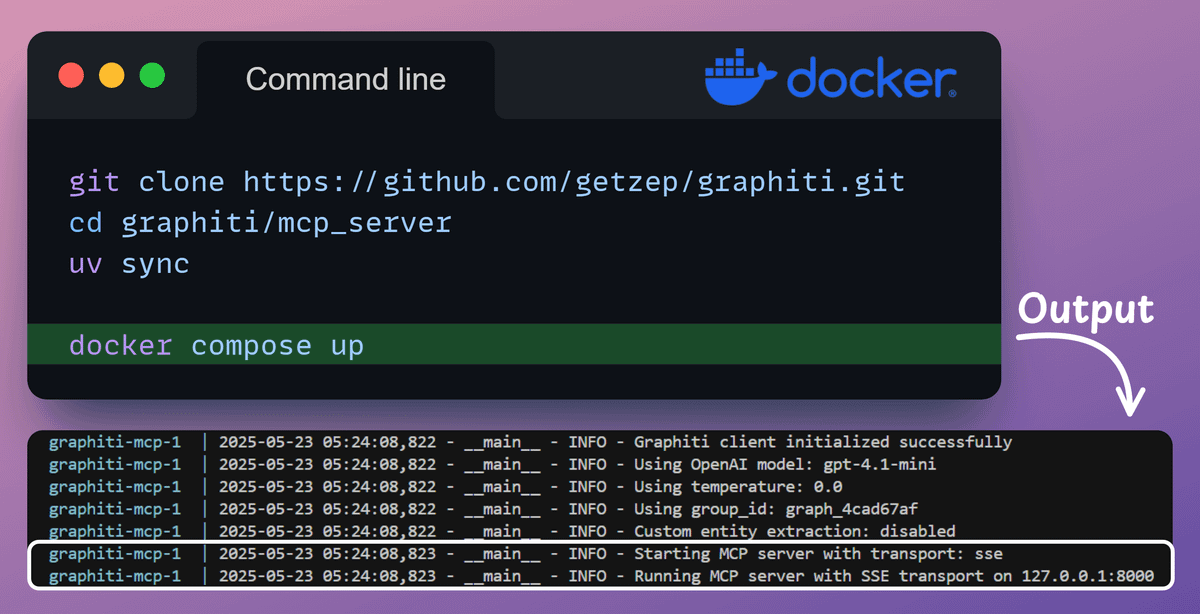
1) Docker Setup
Deploy the Graphiti MCP server using Docker Compose.
This setup starts the MCP server with Server-Sent Events (SSE) transport, and it includes a Neo4j container, which launches the database as a local instance.
This configuration also lets you query and visualize the knowledge graph using the Neo4j browser preview.
You can also use FalkorDB.
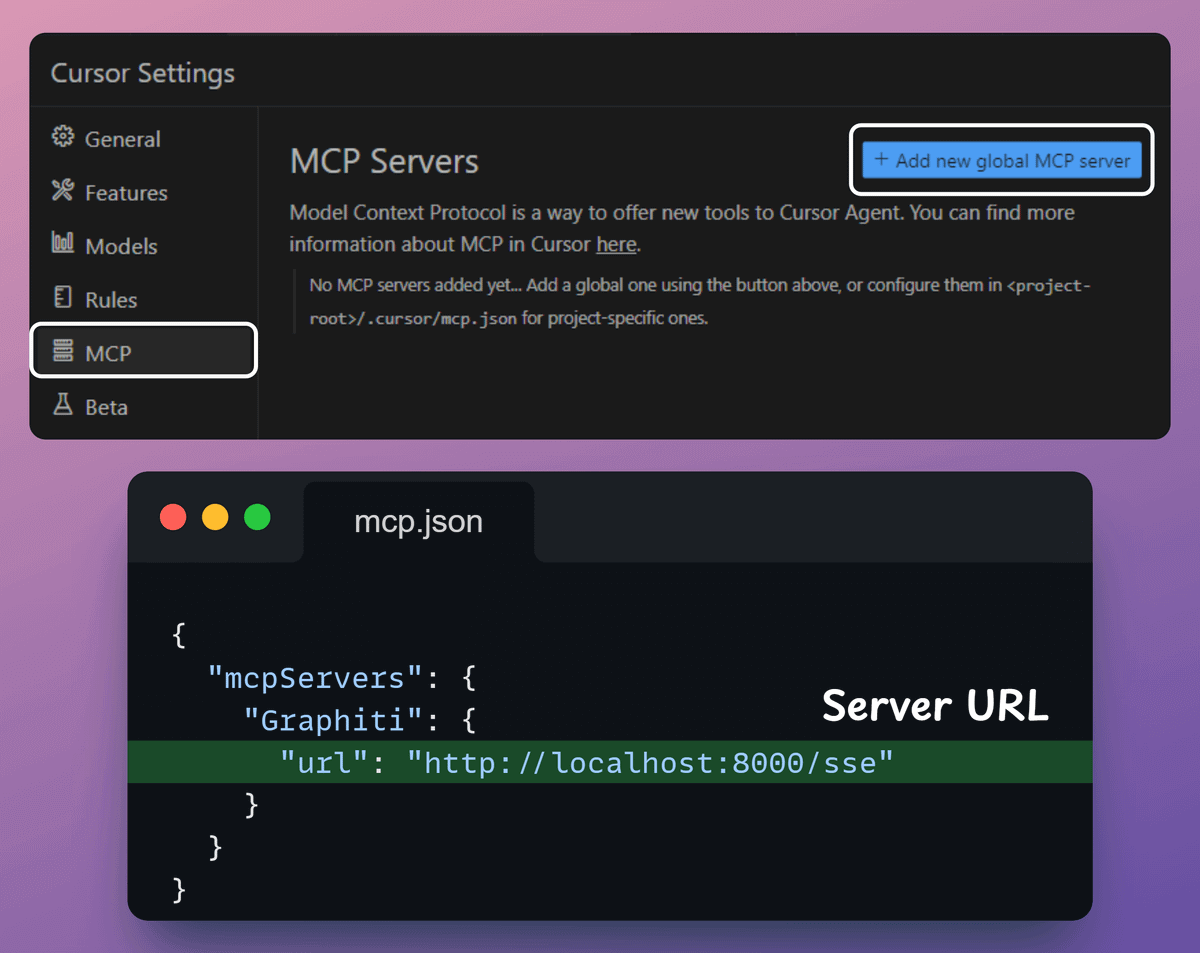
2) Connect MCP server to Cursor
With tools and our server ready, let's integrate it with our Cursor IDE!
Go to: File → Preferences → Cursor Settings → MCP → Add new global MCP server.
In the JSON file, add what's shown below:
3) Connect MCP server with Claude
Similarly, integrate this with Claude Desktop
Go to: File → Settings → Developer → Edit Config
In the JSON file, add what's shown below:
Done!
Now you can chat with Claude Desktop, share facts/info, store the response in memory, and retrieve them from Cursor, and vice versa, as demonstrated in the video earlier.
Why Graphiti?
Agents forget everything after each task!
Graphiti builds live temporal knowledge graphs so your AI agents always reason on real-time info.
Integrating its MCP server with Claude/Cursor adds a powerful memory layer to all your interactions.
100% open-source with 20k+ stars.
I have shared the GitHub repo below.


Big update for Claude Desktop and Cursor users!
Now you can connect all AI apps via a common memory layer in a minute.
I used the Graphiti MCP server that runs 100% locally to cross-operate across AI apps like Claude Desktop and Cursor without losing context.
(setup below)

Avi Chawla retweeted
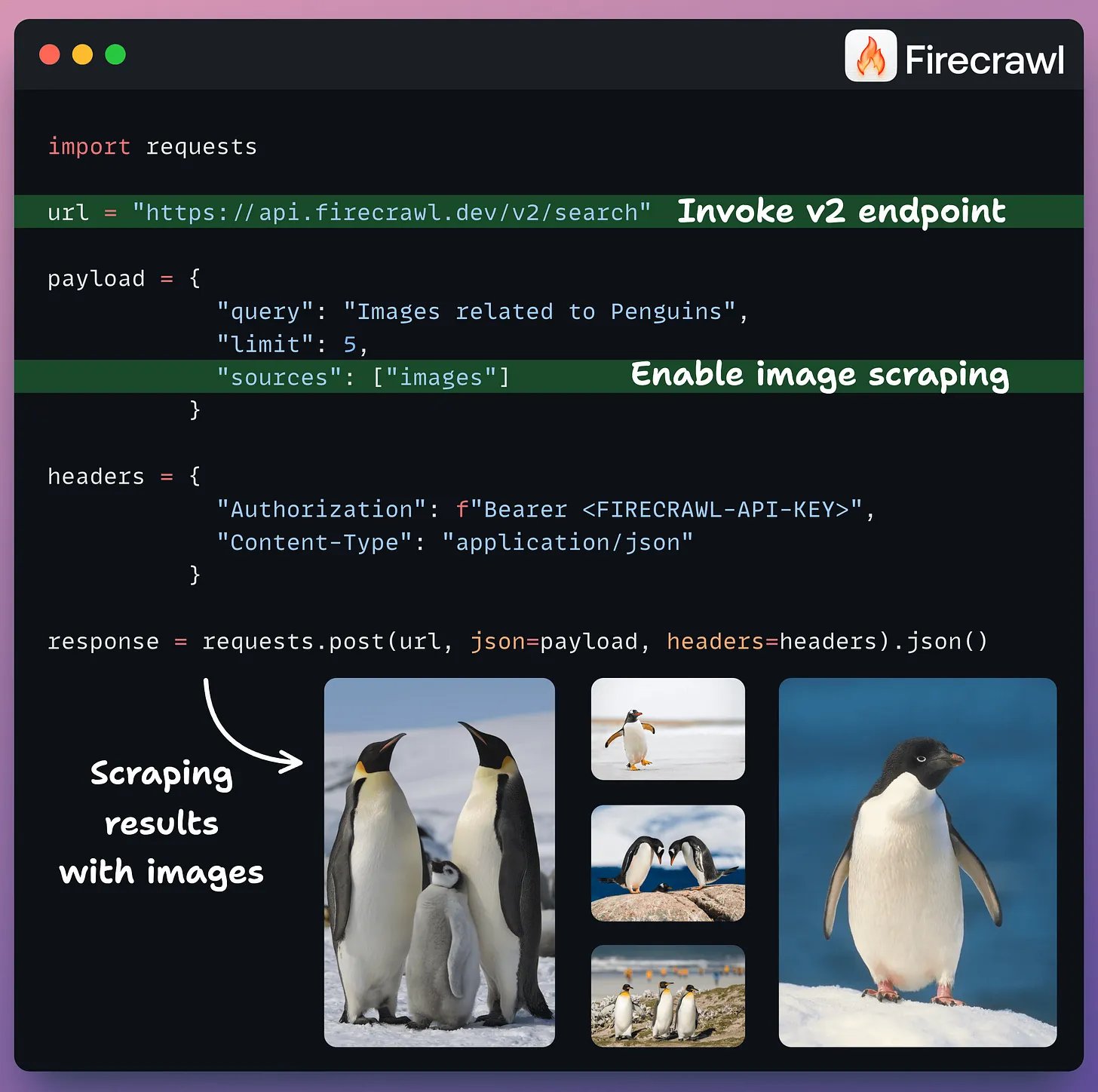
You can now deploy any ML model, RAG, or Agent as an MCP server.
And it takes just 10 lines of code.
Here's a breakdown, with code (100% private):
LitServe GitHub repo: github.com/Lightning-AI/LitS…
(don't forget to star it 🌟)
Connecting AI models to different apps usually means writing custom code for each one.
For instance, if you want to use a model in a Slack bot or in a dashboard, you'd typically need to write separate integration code for each app.
Let's learn how to simplify this via MCPs.
We’ll use @LightningAI's LitServe, a popular open-source serving engine for AI models built on FastAPI.
It integrates MCP via a dedicated /mcp endpoint.
This means that any AI model, RAG, or agent can be deployed as an MCP server, accessible by any MCP client.
Here’s the code:
- InputRequest defines the input schema.
- setup defines the model, Agent, RAG, etc.
- decode_request prepares the input
- predict runs the inference logic
- encode_response sends the response back
- main guard runs the LitServe MCP API
Next, run the above script (uv run server[.]py) to have the model available as an MCP server.
Finally, add the following config to Claude Desktop:
With that, you will have your model available as an MCP server in Claude Desktop.
The above screenshot shows that the model is available as an MCP server in Claude Desktop.
The image below shows an interaction.
I like LitServe because:
- It’s 2x faster than FastAPI.
- It gives full control over inference.
- We can serve any model (LLM, vision, audio, multimodal).
- We can compose agents, RAG & pipelines in one file.