

2/ We partnered with the @arcprize Foundation to add ARC-AGI 1 & 2 to openbench.
ARC-AGI is different from other benchmarks because it focuses on “fluid intelligence” - the ability for a model to reason through a problem that’s not based on general knowledge.
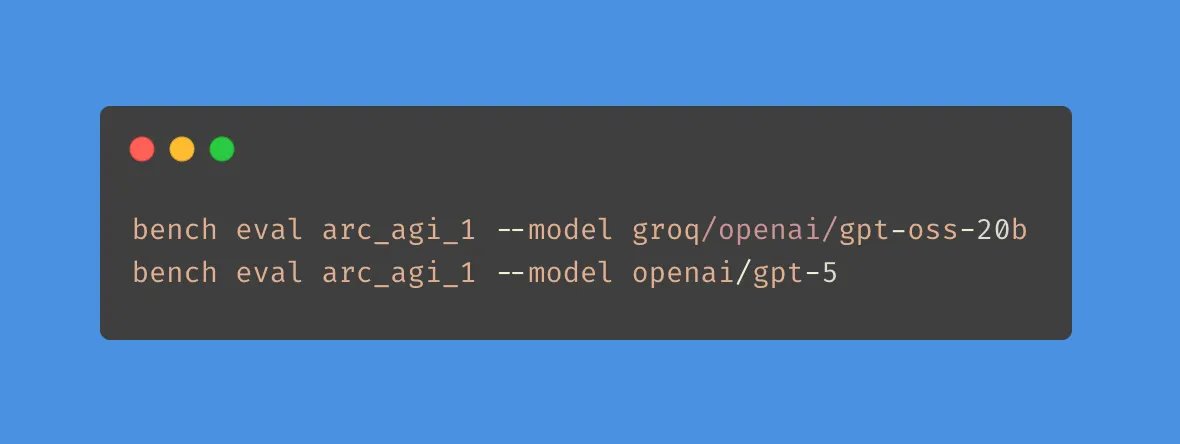
run it yourself with this command:
Oct 10, 2025 · 6:34 PM UTC
3/ 350+ new benchmarks
Big Expansion: We added over 350 new benchmarks to OpenBench - BigBench (122), BBH (18), Global‑MMLU (42 langs), plus GLUE/ SuperGLUE, BLiMP, AGIEval, Arabic Exams (41)
Find a full list of the benchmarks available here:
openbench.dev/benchmarks/cat…
4/ Plugins
register your own benchmarks into openbench via Python entry points! You can even override built‑ins cleanly - no forking required.
Docs are here -
openbench.dev/development/ar…
5/ A Coding benchmark!
Exercism is a coding benchmark that evaluates AI code agents’ ability to solve real-world programming exercises across multiple programming languages.
You can swap harnesses and models to find the best combo - (aider, roo, claude code, opencode).
(P.S. - we have some research on this coming soon 👀)
How to run:
openbench.dev/evals/exercism
6/ Tool use matters:
We’ve added a tool‑calling benchmark to OpenBench via LiveMCPBench! You can now evaluate not just answers, but how reliably your model orchestrates tools end‑to‑end.
Docs on how to get started:
openbench.dev/evals/livemcpb…
7/ Better @OpenRouterAI support! Thanks to the good folks at OpenRouter, you can now specify provider routing for models, with fallbacks, only, order, ignore, etc.
Docs incoming :)

9/
Thank you to the @arcprize Foundation, @GregKamradt, and the broader community for the partnerships, datasets, and contributions - and to everyone shipping evals every day. We hope 0.5.0 helps you measure model quality with clarity (and speed). Full release notes:
openbench.dev/release-notes
10/
If you’re interested in seeing more about openbench, give us a star on GitHub: github.com/groq/openbench