

Pinned Tweet

Introducing the Illustrated Transformer in 3D 🚀
Fly through LLaMA like never before. See every tensor and operation in motion.
Click any component to reveal the exact lines of code that run it.
A new way to learn and teach LLMs. Try it out in the link below 👇


New paper from ByteDance Seed: Scaling Latent Reasoning via Looped LMs
This paper proposes Ouro, which reuse the same layers to think in latent space instead of dumping long chain-of-thought text
2-3x param efficiency + increased performance via iterative latent computation


alphaXiv retweeted
Hottest paper on AlphaXiv 📈
Language Models are Injective and Hence Invertible
Every prompt maps to a unique hidden state and can be exactly reconstructed with this paper’s algorithm SIPIT. This means the model’s internal activations are the full prompt in disguise!!


alphaXiv retweeted
cool idea from Meta
What if we augment CoT + RL’s token space thinking into a “latent space”?
This research proposes “The Free Transformer”, with a way to let LLMs make global decisions within a latent space (via VAE encoder) that could later simplify autoregressive sampling


One of our best talks yet. Thanks @a1zhang for the amazing presentation + Q&A on Recursive Language Models!
If you're interested in how we can get agents to handle near-infinite contexts, this one is a must.
Watch the recording here! piped.video/_TaIZLKhfLc

Someone stole your model & u can’t prove it?
This Stanford paper just showed that you can find out if a model is a copy or finetuned based on your model with just its generated text
So if someone yoinks DeepSeek-v3.2 and finetunes it, it’ll leave statistical traces!

Check it out here! alphaxiv.org/

alphaXiv retweeted
Introducing the Illustrated Transformer in 3D 🚀
Fly through LLaMA like never before. See every tensor and operation in motion.
Click any component to reveal the exact lines of code that run it.
A new way to learn and teach LLMs. Try it out in the link below 👇



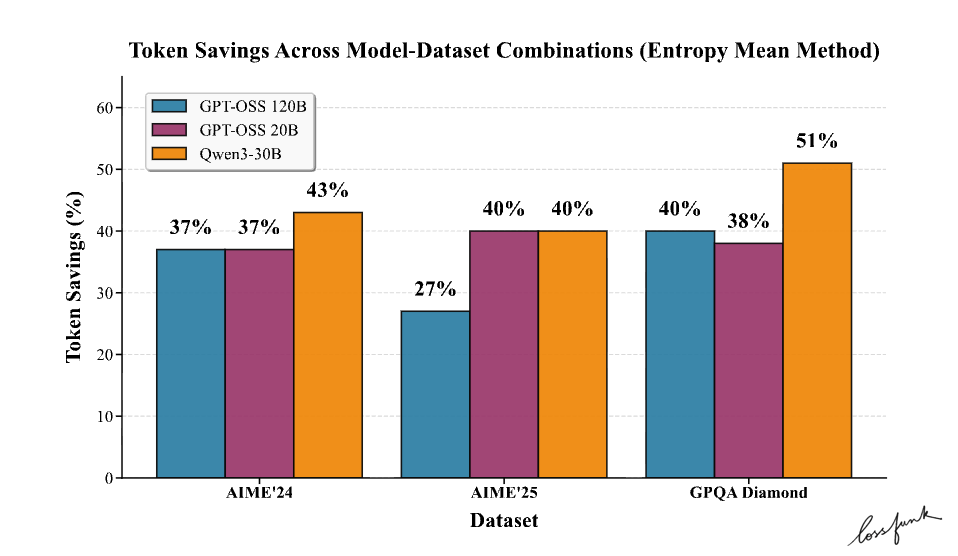
📢 Releasing our latest paper
For LLMs doing reasoning, we found a way to save up to 50% tokens without impacting accuracy
It turns out that LLMs know when they’re right and we can use that fact to stop generations early WITHOUT impacting accuracy.
The three.js visualization parses the output of llama-cpp's ggml debug output (of unsloth llama 3.1) to directly obtain all the tensor calculations happening under the hood. Operations (MUL_MAT, ROPE, RESHAPE, ADD) are grouped into query, key, value, MLP, and residual stream blocks - hovering over each block will show the exact computation in the info card, and clicking on it will lead back to the exact lines it corresponds to in our custom syntax highlighted editor. Thanks @tch1001 for the amazing work!