

ComfyUI node explorer • Sharing AI workflows • Diffusing pixels and conditioning latent space 🫡
Chicago
Joined February 2023
- Tweets 621
- Following 424
- Followers 2,534
- Likes 2,395
Pinned Tweet

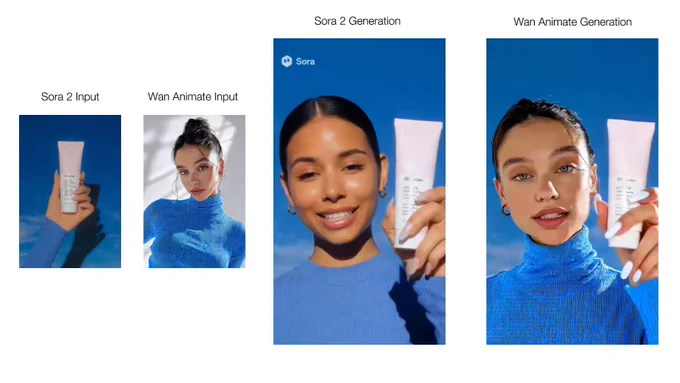
Sora 2 blocks input images of real people, making character consistency impossible.
I built a workaround so you can have consistent AI UGC actors across videos.
Product photo + Prompt → Sora 2 vid → Watermark removal → Character + Wan Animate
Step by step guide below ⬇️

Included in the workflow are prompts suggested by the lora author to test. The examples above are upscaled, but overall details out of the box are quite good.
Everything generated with @Alibaba_Qwen inside @ComfyUI.
Worth noting the model struggles a bit with back views.
lora - huggingface.co/dx8152/Qwen-E…
workflow - pastebin.com/UP4MSwD7

Another win for open-source AI models.
This new Qwen Multiple Angles LoRA perfects scene and subject consistency.
Look at her ring, the records, album covers and turntable buttons. Even the headphone wire and text. Insane.
Test it for yourself - FREE workflow ⬇️




The workflow resizes the cropped masked image to 1024x1024. It’s best to draw in your mask as a square around the product for seamless pasting.
You can composite the product to the scene anyway you’d like, just make sure the resolution of both the product and scene are high quality. I recommend at least 2k for the input image.
This workflow is especially helpful when the product needs to maintain quality when placed further away in the scene. The results below speak for themselves.

Here’s the workflow! Keep in mind although the crop and stitch plays an importsnt part, the real magic is fusion LoRA. Both are linked.
The workflow has simple inputs for saving your images, the green nodes are for you input.
If you find this helpful, give @hellorob a follow for more of the most organized ComfyUI workflows!
A couple notes and comparisons in the next post…
LoRA - huggingface.co/dx8152/Fusion…
Link - pastebin.com/MhSSEaN1

Your AI product photos look great until you zoom in on the text...
The example below uses the same input image, model and LoRA… the only difference? The workflow.
Upscale input → Crop and diffuse ONLY the product → Paste it back
FREE workflow and tips below ⬇️




Also give the guy who trained the Fusion lora a follow!
huggingface.co/dx8152
Test 5: Shoes VTON
Nano Banana does well here at placing the shoe on and even adds air bubbles to the scene. It retains the lighting of the input shoe, while Qwen doesn’t.


Test 4: Glasses VTON
This time from a frontal view. All models seem to change the tint of the lenses slightly, but still look at how much better Fusion Lora retains product details.


Test 3: Glasses VTON
This is a test that no image edit model was able to get until now. It retains the details and integrates the shadows very well.


Test 2: Product relighting
Qwen fusion lora has a way more seamless integration into the vibe of the environment.


Test 1: Product relighting
Check out the subtle reflections of the gold on the reflective lipstick material.


Before I show some samples, here’s the @ComfyUI workflow so you can easily test all the best image-editing models in one place.
The workflow includes some notes to get started and the Huggingface link to the @Alibaba_Qwen lora.
Also consider giving @hellorob a follow for more free AI workflows!
Link - pastebin.com/gFQbKg5N

A Chinese developer with 97 followers just outperformed a SOTA model.
He trained an opensource Qwen edit LoRA model for product relighting and it beats Nano Banana across the board.
Sounds crazy? Check for yourself.
FREE workflow and more comparisons below 👇



Turns out you can also go from extremely jacked --> skinny



Sora 2 blocks realistic faces by default.
I found a way to trick their guardrails that lets you
→ Upload realistic images
→ Full control over first frame
→ Consistent characters across videos
No clue how long before it gets patched.
RT + reply 'SORA' and i'll send you the full workflow (must follow so I can DM)

This is what the ComfyUI workflow looks like.
It's as simple as installing the models, dropping in your Sora 2 video, and clicking run.
The workflow has download links for the necessary models and the file structure (thanks to linkedlist771 for the Sora watermark Yolov11s detection model).
I hope this helps! For more simple to use and free AI workflows, follow @hellorob
Workflow - pastebin.com/LUq8Pjat

Sora watermark remover apps charge $48/year for something that costs 8 CENTS to run.
These apps scalp you with subscriptions + low quality CPU blur models.
Here's a FREE solution.
ComfyUI workflow that
→ Auto-detects watermark (custom YOLOv11s)
→ Removes them cleanly (GPU inpainting, no blur)
→ Pay per vid, costs ~$0.08 on a 5090
Download the workflow ⬇️
