
🔥 LongCat-Flash-Omni: Multimodal + Low-Latency
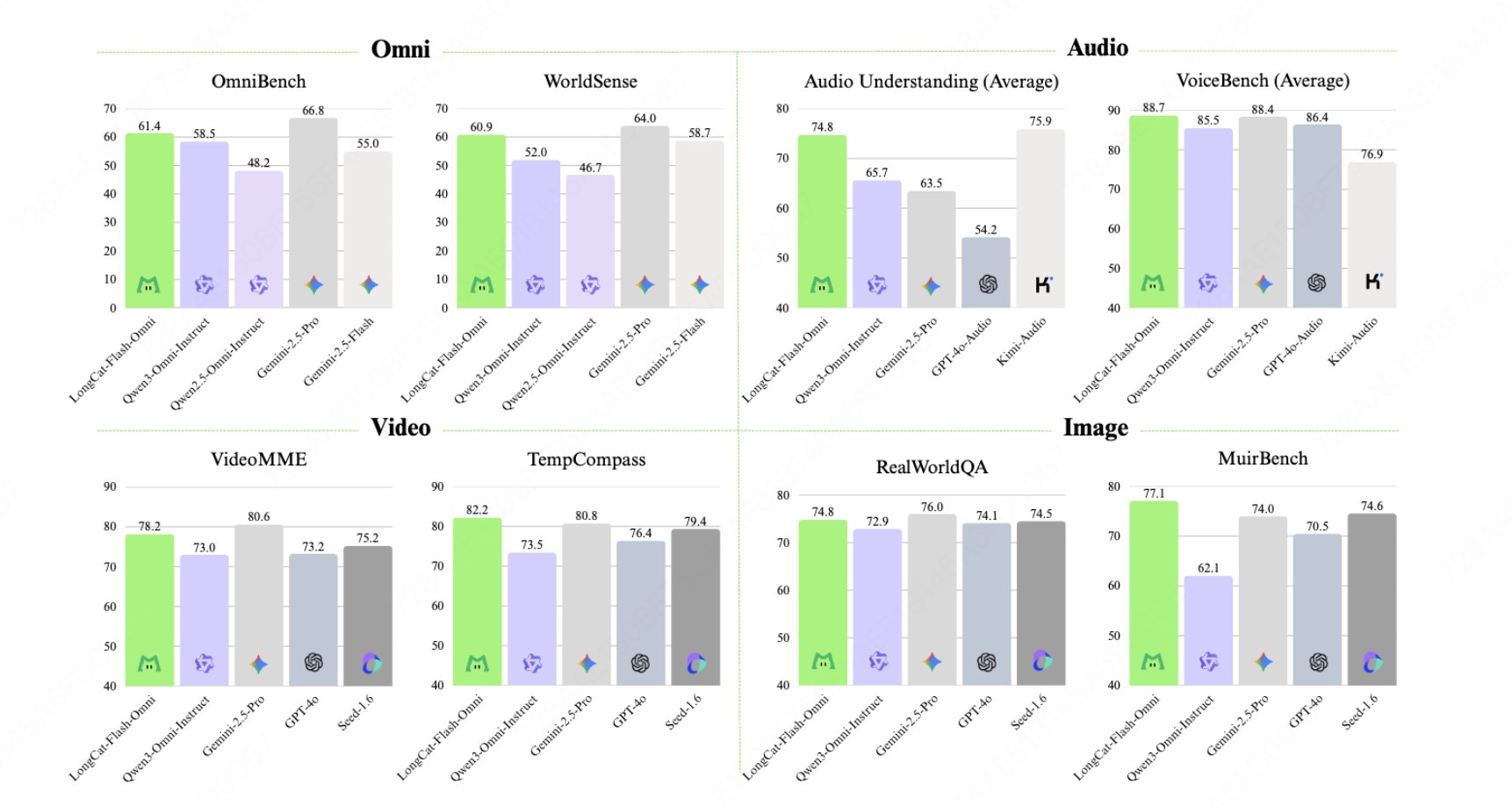
🏆 Leading Performance among Open-Source Omni-modal Models
☎️ Real-time Spoken Interaction: Millisecond-level E2E latency
🕒 128K context + Supports > 8min real-time AV interaction
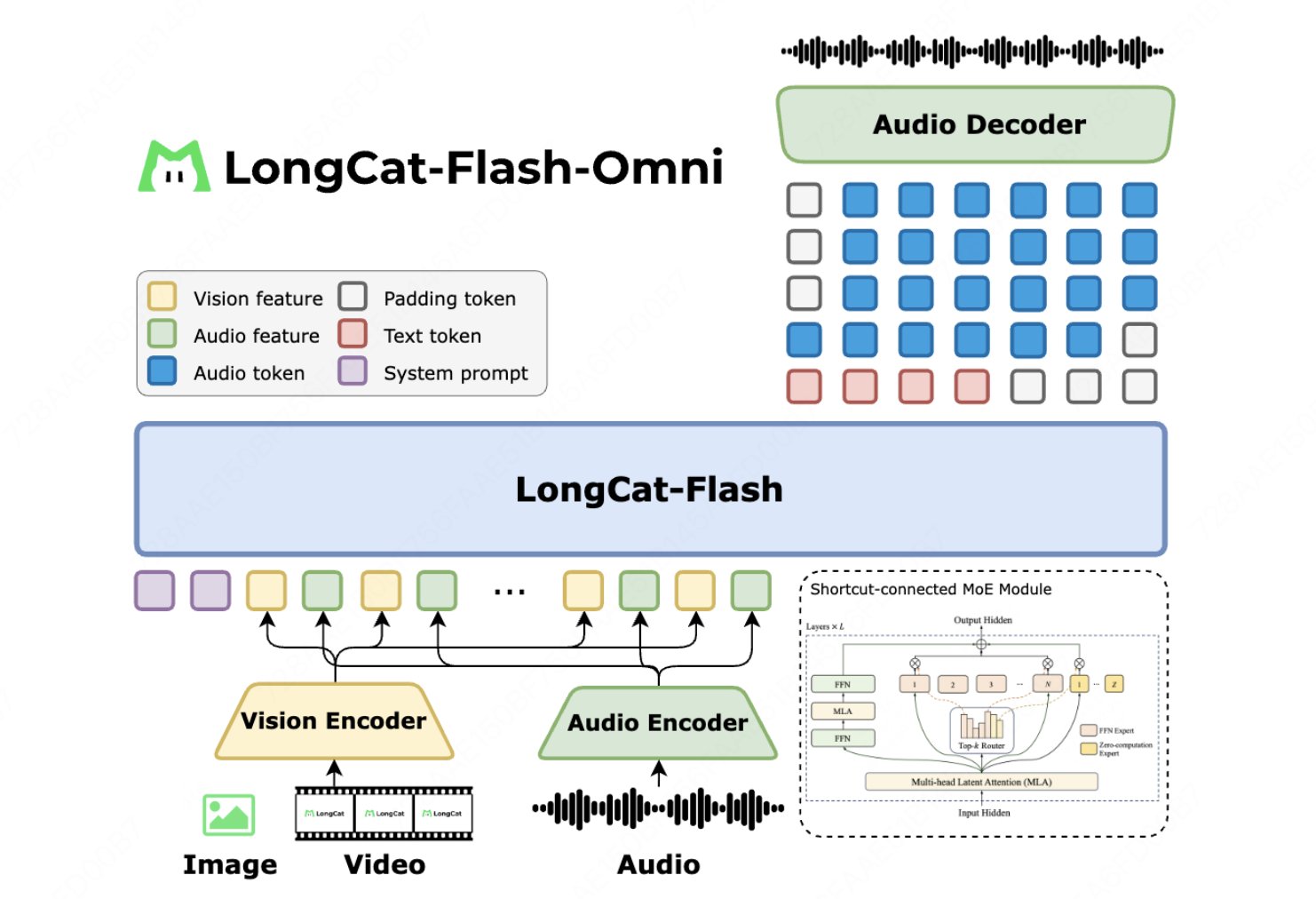
🎥 Multimodal I/O: Arbitrary Combination of Text/Image/Audio/Video Input → Text/Speech Output (w/ LongCat-Audio-Codec)
⚙ ScMoE architecture on LongCat-Flash: 560B Parameters, 27B Active
🧠 Training: Novel Early-Fusion Omni-modal training paradigm -> No Single Modality Left Behind
🚀 Efficient Infrastructure: With optimized modality-decoupled parallel training, Omni sustains >90% throughput of text-only training efficiency
🤗 Model open-sourced:
【Hugging Face】huggingface.co/meituan-longc…
【GitHub】github.com/meituan-longcat/L…
📱 LongCat APP is here—available for both iOS and Android! Scan the QR code to quickly try its awesome voice interaction features!
💻For the PC experience, you can click on LongCat.AI for a free trial!


Sounds great but for mere mortals, it's pretty hard to evaluate the audio capabilities. Do you folks have an API we could call?
Nov 1, 2025 · 12:15 AM UTC