
Introducing RSA 🌀 (Recursive Self-Aggregation): unlocking deep thinking with test-time scaling
🔥 Qwen3-4B + RSA > DeepSeek-R1
📈 Gains across Qwen, Nemo, GPT-OSS
🏆 Benchmarks: Math • Reasoning Gym • Code
⚡ Aggregation-aware RL lets Qwen3-4B surpass o3-mini 🚀
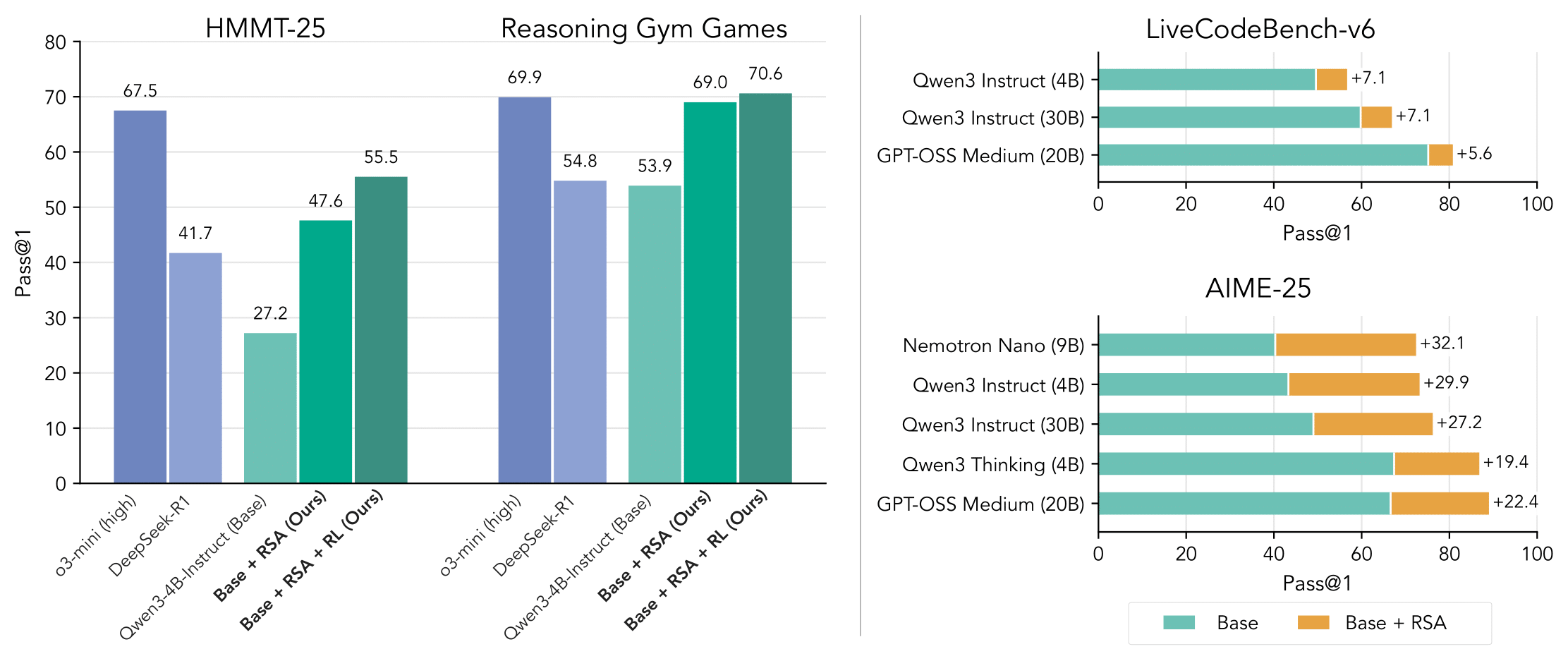
Sep 27, 2025 · 3:21 AM UTC
RSA (Recursive Self-Aggregation) = Sequential refinement 🔄 + Parallel exploration ⚡
→ Unified into a hybrid evolutionary loop for deeper reasoning.
📄 Paper + website: rsa-llm.github.io/
🧵 Details in the thread

RSA is simple 🚀
1️⃣ Generate a population of N reasoning chains in parallel
2️⃣ Subsample into N subsets of K chains
3️⃣ Prompt the model to aggregate each subset → new improved population of CoTs
4️⃣ Repeat for T loops
That’s the whole algorithm: Recursive Self-Aggregation

RSA scales sequentially & in parallel: more steps T or larger aggregation K jointly with population N → better performance!
🔥 Gains:
AIME-25 47 → 73%
HMMT-25 29 → 50%
Reasoning Gym Games 55 → 70%
LiveCodeBench 49.5 → 56.3%
No verifiers ❌ No prompt opt ❌ No RL yet!

RSA boosts performance across all models and all reasoning tasks.
Tested on Qwen, Nemo, GPT-OSS — thinking & non-thinking, MoE & dense, full-attention or hybrid SSM.
Benchmarks: AIME, HMMT LiveCodeBench, Reasoning Gym
📈 Gains are consistent and significant throughout.

RL makes RSA even stronger 📈
Naive RL can hurt aggregation, but aggregation-aware RL ✅
👉 Generate K responses
👉 Create aggregation prompts
👉 Train the model to aggregate
Boosts performance & generalizes to new tasks — RSA is worth it!

RSA beats all simple budget-matched test-time scaling baselines!
Shoutout to concurrent work by @wzhao_nlp & team for AggLM (RL-trains single-step aggregators). We independently discovered this, but also find that sequential aggregation with larger population is key for scaling.

Amazing work jointly with @siddarthv66 & @thevineetjain as equal contributors, and help from a fantastic team: @veds_12 @johanobandoc @Yoshua_Bengio @bartoldson @bkailkhu @g_lajoie_ @GlenBerseth @FelineAutomaton @JainMoksh !