

Joined October 2011
- Tweets 1,165
- Following 358
- Followers 107
- Likes 5,923


Somuns’A retweeted

Even G2. Get ready to wear the future. Launching on Nov 12.
At first, they might look like ordinary glasses. But the moment you wear them, everything changes.
A new extraordinary power is almost ready to be unleashed.
Launching on Nov 12.
evenrealities.bio/G2x

Somuns’A retweeted
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai

Somuns’A retweeted

When the XPENG IRON gracefully approaches you, @Tesla_Optimus how will you greet her?



Somuns’A retweeted

300 million tourists a year, free to roam everywhere unimpeded in Xinjiang, and still not a single photo evidence of this so-called "Uyghur genocide" 🤔
On the contrary you do get an overwhelming amount of photo evidence of Uyghurs just living normal lives.
Compare and contrast this with Gaza: zero tourist (or journalist, or anyone) allowed in and you still get overwhelming photo evidence.
Because, guess what, in the age of social when people are actually being mistreated and mass murdered, you can't hide it.
You can't hide it in a place that's completely blockaded, you can hide it even less in a place that's fully open to anyone (many foreigners, like almost all European countries, don't even need a visa nowadays to enter China and Xinjiang).
The BBC - which previously pushed the Xinjiang narrative hard - is trying hard to square this circle by claiming "there's a side of Xinjiang" that these 300 million tourists "don't see."
And what is that "side they don't see" according to the article? That even though the Uyghurs are there and Uyghur culture is everywhere, that's apparently not "the real Uyghur culture" because, as they claim, old towns were rebuilt for tourism and tourists see made-for-tourism ethnic performances.
Except this is literally how tourism development works everywhere in China (and pretty much everywhere in the world, frankly). Heck, this is how development - period - works: no-one wants to see the "real" old town from 1970s China because, guess what, it was completely run down and poor AF.
I partially grew up myself in a street of Paris called "rue Mouffetard" in the extremely touristic 5th arrondissement. The name of the street comes from the old French verb "mouffeter", which means to stink: this street used to be famous for smelling like shit because it was a very poor area of Paris back in the old days. Should it have been left as such so that people get to experience the "real" Paris instead of the heavily gentrified "Emily in Paris" version you get today? Anyone with a brain can see how idiotic that is.
Anyhow that's the new - utterly ridiculous - narrative: "the visible Uyghur culture doesn't count because things got redeveloped and updated."
Well, at least the Western media narrative seems to have been downgraded from crimes against humanity to "we don't like their tourism development model" - progress, I guess...

300 million tourists just visited China's stunning Xinjiang region. There's a side they didn't see bbc.in/4hFqRho


Somuns’A retweeted

This week, two U.S. coding assistants—Cursor and Windsurf—were caught running on Chinese foundation models. Cursor’s “Composer” speaks Chinese when it thinks. Windsurf’s “SWE-1.5” traces back to Zhipu AI’s GLM.
The real story here isn’t deception. Training foundation models from scratch costs tens of millions. Fine-tuning open-source models is the rational path. And Chinese models are now the best option.
Qwen leads global downloads on Hugging Face. Chinese models dominate trending charts. Third-party benchmarks show they match or beat Western alternatives on reasoning and speed.
Silicon Valley has spent years worrying about China “catching up” in AI. That framing is obsolete. Chinese open-source models aren’t just competitive—they’re infrastructure. Western developers build on them because they work, they’re free, and they’re good enough.
The global AI stack is converging. Right now, much of it runs on code from Beijing.



Somuns’A retweeted
Perhaps unsurprisingly, I haven’t seen many media outlets report accurately on the “deal” reached between Trump and Xi today, most forgetting to mention crucial aspects of it and almost all failing to contextualize the “47%” tariff figure quoted by Trump.
Let me try to detail the deal as accurately as I can, drawing from sources from both sides (on the Chinese side I mostly used a China Ministry of Commerce statement issued today at 3pm Beijing time, so roughly 1 hour and a half after the “deal” was concluded: mofcom.gov.cn/xwfb/xwfyrth/a… and on the U.S. side I used statements by Trump himself and others present in the meeting).
The key terms:
1. The U.S. will remove the so-called “50% rule” that it implemented in September for one year, in exchange of which China will suspend its rare earths export controls for one year
The removal of the “50% rule” is absolutely key, yet almost no media reported it, only mentioning that China had agreed to suspend its rare earths export controls for one year. Worth mentioning that the removal of the “50% rule” has been confirmed by Bessent himself as of a couple of hours ago (reuters.com/world/china/us-h…)
As a reminder the “50% rule” was THE main reason why China retaliated with the rare earths export controls. It was a huge escalation by the U.S. as it effectively increased the number of Chinese companies on the "Entity List" by 14 times (!), from 1,400 companies to 20,000 (x.com/RnaudBertrand/status/1…). Meaning 14 times more Chinese companies cut off from the Western financial system, forbidden to use USD, etc.
It was also the key trigger for the Nexperia debacle that’s currently occurring in Europe. The “50% rule” would have put Nexperia on the Entity List, and the U.S. told the Dutch that the only way Nexperia could escape U.S. sanctions was to get rid the Chinese ownership in the company (ft.com/content/db019842-01a9…), hence the Dutch’s move to seize the company away from its Chinese ownership almost simultaneously with the introduction of the “50% rule”. Unclear what will happen in this case now that the 50% rule has been dropped but logic would dictate that the company be given back to its rightful owners. Although, admittedly, expecting European legislators to act based upon logic is a tall order…
2. The US will drop its OVERALL tariffs on China to 47%, meaning that China now benefits from 16% tariffs as part of the "Liberation Day" tariff policy
Of course Trump would mention the OVERALL number to make it sound like he didn’t cave on his liberation day tariffs but when one looks into the details, China actually negotiated him down to approximately 16% on his "Liberation Day" tariffs (down from the initial 34% and WAY down from the 125% peak), AND they got the so-called “fentanyl tariff” cut by half on top of that.
How so? First of all, before Trump 2.0 even got inaugurated, tariffs on Chinese goods were already standing at a weighted average of 20.7% (source: piie.com/research/piie-chart…). Soon after taking office, in February and March (so before “Liberation Day”), Trump added 20% on top of that in the form of his so-called “fentanyl tariff.” So BEFORE “Liberation Day” the OVERALL tariffs on China were already 40.7%.
Then on Liberation Day Trump added a 34% reciprocal tariff on top of that (so 74.7% overall tariffs), which he again escalated to 125% by April 10th after China retaliated. This brought the peak to 145% just from Liberation Day and fentanyl tariffs alone (or 165.7% including the pre-existing tariffs).
The fact that the OVERALL rate is now down to 47%, given the fact that the deal includes a 50% reduction on the fentanyl tariff (from 20% down to 10%), means that China has now negotiated the Liberation Day down from 125% to about 16% since 20.7% + 10% fentanyl + 16% Liberation Day is approximately equal to 47% overall tariffs (well, 46.7% to be exactly precise).
This means that when it comes to Liberation Day tariffs, China will stand roughly on par with the EU (who are at 15%: policy.trade.ec.europa.eu/ne…) or South Korea (who also will likely be around 15%: bbc.com/news/articles/cly4jz… ).
3. The US will suspend its hostile actions on China’s ships and shipbuilding industry, in exchange of which China will also suspend its retaliatory measures
The US has agreed to suspend implementation of its so-called “301 investigation” measures against China's maritime, logistics and shipbuilding industry for one year, which was going to lead to massive port fees in the U.S. for Chinese-built and Chinese-operated vessels.
In exchange China will also correspondingly suspend implementation of countermeasures against the US for one year: they had announced that, as retaliation, they too would start charging U.S. ships for docking at Chinese ports (reuters.com/business/autos-t… )
4. Other parts of the deal
TikTok: China mentions they agreed to "properly resolve" the TikTok issue which is probably diplomatic speak to say that it’s not resolved yet.
Soybeans: China mentioned that “both sides reached consensus on expanding agricultural product trade” while Trump mentioned that China will buy 'tremendous' amount of soybeans, which all in all probably means that China agreed to resume buying U.S. soybeans (which they had stopped as retaliatory measures as leverage in the trade war).
Fentanyl: Both sides agree on "anti-drug cooperation" regarding fentanyl - which is language that’s pretty boilerplate in US-China discussions, so probably nothing new there.
“Handling of individual enterprise cases”: there is a pretty opaque language that suggests both sides discussed how to handle specific companies’ issues (Nvidia? Huawei? Nexperia?) and that they “reached consensus” on this.
Future Summitry: Trump commits to visiting China in April 2026, with mutual support pledged for China's 2026 APEC hosting and America's G20 summit. This signals both sides expect the relationship to stabilize enough for Xi and Trump to meet several times in person in 2026.
All in all, I would say that the key feature of this “deal” is the reciprocity and almost religious balance in every aspect: each concession matched by the other, each suspension mirrored. It shows we're now dealing with peer competitors who can effectively keep each other in check.
You can see how immensely things have changed if you contrast this deal with Trump's so-called “Phase 1” agreement from his first term (ustr.gov/phase-one) with its unilateral Chinese commitments to buy American products and enact structural reforms to "rebalance" trade, with the U.S. warning it would “vigilantly monitor” Chinese compliance. All from an era when the US could still essentially dictate terms. None of that unequal framework survives here: instead of Washington trying to reform China based on its interests; all it can now do is learn to coexist with it.
It’s still early days though, for instance the deal doesn’t mention fundamental issues such as Taiwan. This is clearly not a grand strategic reset but rather both powers trying to figure out the rules of engagement of our new multipolar reality.
Xi Jinping mentioned in his introductory statement in the meeting that the U.S.-China relations was a “giant ship” going through “winds, waves and challenges” that needed to be “steadily sailed forward” by both leaders. That’s pretty much what this meeting was: the winds and waves are still there but at least both sides seem to acknowledge that they're now on the same ship.



Taiwan is an internal affair of China. In the past, the United States often played the "Taiwan card", but now China calls the shots, and Taiwan is no longer a "card" for others to exploit. Stop indulging in wishful thinking.😊




Somuns’A retweeted

This is an incredibly important paper, recently published in China Economic Review.
It finds that China’s low-carbon technology exports *significantly* reduce partner countries’ CO₂ emissions.
China’s clean energy push is clearly a key driver of global decarbonisation.

Somuns’A retweeted

重庆市公安局28日发布,为坚决打击沈伯洋通过发起、建立“台独”分裂组织“黑熊学院”等方式从事分裂国家犯罪活动,该局根据《中华人民共和国刑法》《关于依法惩治“台独”顽固分子分裂国家、煽动分裂国家犯罪的意见》等有关规定,决定对沈伯洋涉嫌分裂国家犯罪立案侦查,依法追究其刑事责任。

Somuns’A retweeted

Insane computing breakthrough
China’s analogue AI chip could work 1,000 times faster than Nvidia GPU 👀
"Chinese scientists have created a superfast analogue chip that can solve complex maths problems for advanced scientific tasks and artificial intelligence while using less power than conventional computing, according to a paper published this month."
"The analogue device designed by researchers from Peking University uses memory chips made of resistive materials. With future improvements, it could perform calculations at a processing rate 1,000 times faster than top digital processors, such as the Nvidia H100 graphics processing unit (GPU), according to the team."
"Benchmarking shows that our analogue computing approach could offer a 1,000 times higher throughput and 100 times better energy efficiency than state of the art digital processors for the same precision," say researchers.
Judging by the news from the past few months, it really feels like we’ve hit the knee of the curve.

Somuns’A retweeted

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
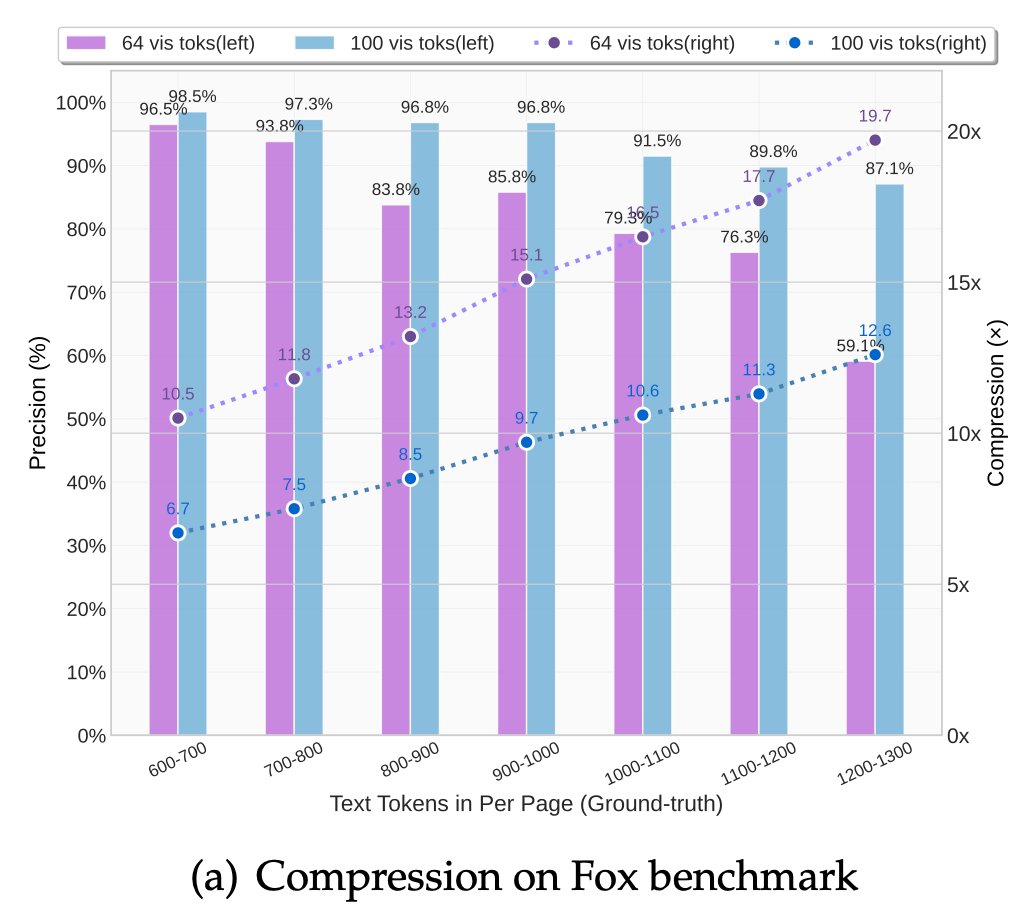
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning




Somuns’A retweeted

🚨 DeepSeek just did something wild.
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That means one image can represent entire documents using a fraction of the tokens an LLM would need.
Even crazier? It beats GOT-OCR2.0 and MinerU2.0 while using up to 60× fewer tokens and can process 200K+ pages/day on a single A100.
This could solve one of AI’s biggest problems: long-context inefficiency.
Instead of paying more for longer sequences, models might soon see text instead of reading it.
The future of context compression might not be textual at all.
It might be optical 👁️
github. com/deepseek-ai/DeepSeek-OCR

