

Physicist, Programmer, Designer
Berlin
Joined December 2024
- Tweets 1,250
- Following 52
- Followers 925
- Likes 14

Stunning Qwen-Edit 2509 LoRA for Light Restoration. Solid and accurate; it makes photo retouching insanely fast.
huggingface.co/dx8152/Qwen-I…

Hmmm.. Impressed. Making cartoons with Grok is surprisingly fun and easy; Grok + Nano Banana, ~2 hours with manual editing and voiceover. Made by Alex

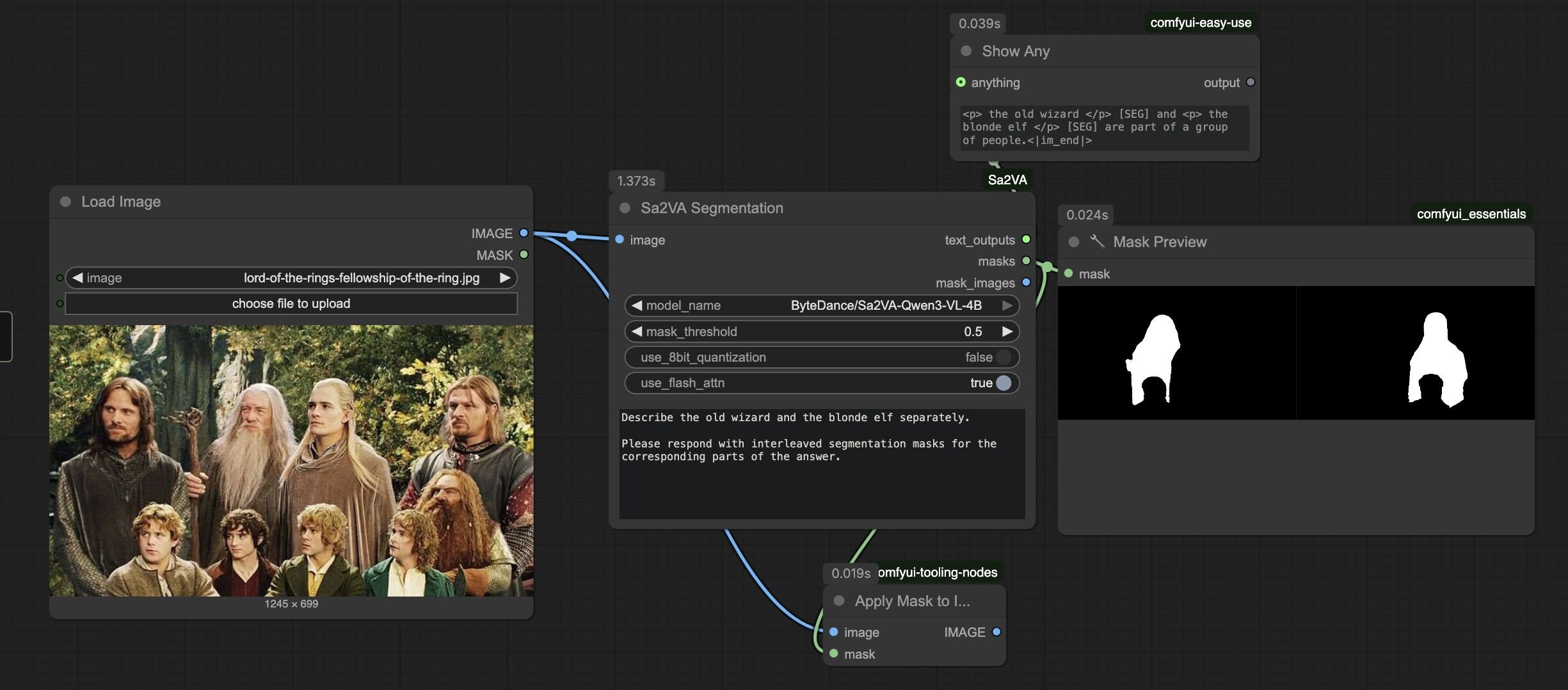
ComfyUI Sa2VA: advanced image segmentation; SAM2+ Qwen3-VL for pixel-perfect masks from descriptive prompts; supports 2B to 14B models, 8GB+ VRAM for the 4B version; image-only implementation.
github.com/adambarbato/Comfy…

⚡️ LightX2V released Wan2.2-Lightning Seko-V2.0, a 4-step LoRA for Wan2.2-T2V-A14B
huggingface.co/lightx2v/Wan2…

BindWeave: Subject-consistent video generation via cross-modal integration; Kijai never sleeps & has already dropped it in ComfyUI; it's an fp8_scaled 17Gb model
huggingface.co/Kijai/WanVide…

Retrofuturism is now more accessible with Technically Color WAN 2.2, LoRA captures the soul of classic film; vibrant palettes, rich saturation & dramatic lighting; expect lush greens, brilliant blues, and the warm, dreamlike glow of the silver screen.
huggingface.co/renderartist/…

CamCloneMaster: replicating camera movements from reference videos without needing camera parameters; based on Wan2.1-1.3B; built using a large-scale Camera Clone Dataset. Solid results.
camclonemaster.github.io/

I like the way this node is organized; ResolutionMaster for ComfyUI- precise, visual control over resolution and aspect ratios; a full Preset Manager, you can create, save, import/export, and manage custom presets directly within the UI.
github.com/Azornes/Comfyui-R…

InfinityStar by Bytedance: A unified 8B spacetime autoregressive model for high-res image & video gen;
- 5s 720p video ~10x faster than DiT;
- scores 83.74 on VBench, topping other AR models and HunyuanVideo;
- Flan-T5-XL as text encoder.
- 480/720p, ~35Gb model
github.com/FoundationVision/…

LiveTradeBench: A platform for evaluating LLM-based trading agents in live markets; supports multiple LLMs (GPT, Gemini) & markets (US stocks, Polymarket); tests sequential decision-making under uncertainty, finding high LMArena scores don't predict trading success. LLMs will help you burn your money.
trade-bench.live/

UniLumos: A unified img/video relighting; fast and accurate; based on Wan2.1 and Qwen2.5-VL.
github.com/alibaba-damo-acad…

ComfyUI Video Stabilizer: Classic and Flow-based stabilization; offers crop, crop-and-pad, and expand framing modes; outputs a padding mask for use with outpainting models like Wan2.2 VACE.
github.com/nomadoor/ComfyUI-…

Maya1: An expressive voice generation model for voice design via natural language; features 20+ emotion tags, sub-100ms real-time streaming, 3B Llama backbone; runs on a single GPU. Awesome voice quality. Beats Chatterbox/Vibevoice
huggingface.co/maya-research…

BindWeave: Subject-consistent video gens; MLLM to parse complex multi-subject prompts w/ spatial relationships; topping open & commercial models. Based on Wan. Huge model 70Gb
lzy-dot.github.io/BindWeave/

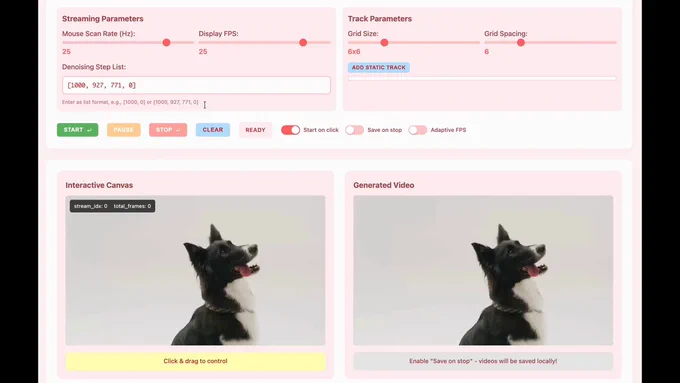
MotionStream: Real-time, interactive video generation with mouse-based motion control; runs at 29 FPS with 0.4s latency on one H100; uses point tracks to control object/camera motion and enables real-time video editing.
joonghyuk.com/motionstream-w…

Someone made a full AI-produced spec ad for On Running as a proof of concept;; created with Nanobanana, Veo 3.1, ElevenLabs, Higgsfield; total production took ~10 hours and cost ~$50.

O kurczę! Polish prompts are officially the most effective for LLMs. Polish queries achieved 88% accuracy, beating English (84%) across models like ChatGPT, Qwen, and Llama.
arxiv.org/abs/2503.01996

Qwen-Edit 2509 Group Photos LoRA. High character consistency; takes two input images and creates a single composite shot; excels at vintage/retro styles with grain and motion blur effects.
huggingface.co/valiantcat/Qw…



Qwen-Edit 2509 Passionate Kiss LoRA. Hugging & kissing in any scene; two character images + one background; scene consistency.
huggingface.co/valiantcat/Qw…


