

daily journal on building products
Joined September 2022
- Tweets 1,586
- Following 1,994
- Followers 2,323
- Likes 464

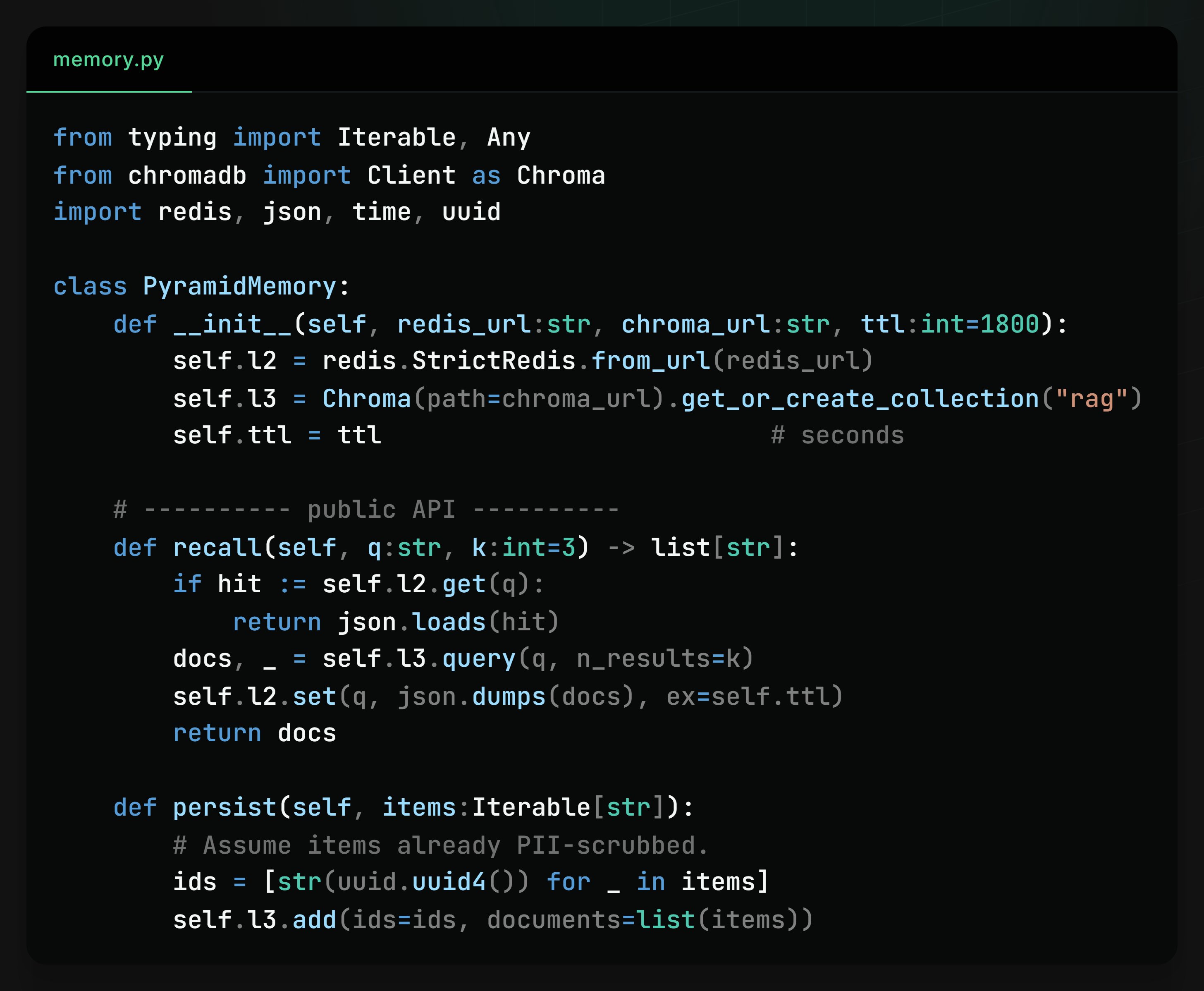
In this post, I will talk about memory and context management in agentic applications.
This is very important due to several factors
* Latency vs. recall: Flat vector stores grow unbounded and slow.
* Regulation: GDPR/AI Act force purpose limitation & storage minimisation.
* Prompt-token tax: Every extra byte re-ingested costs cash and latency
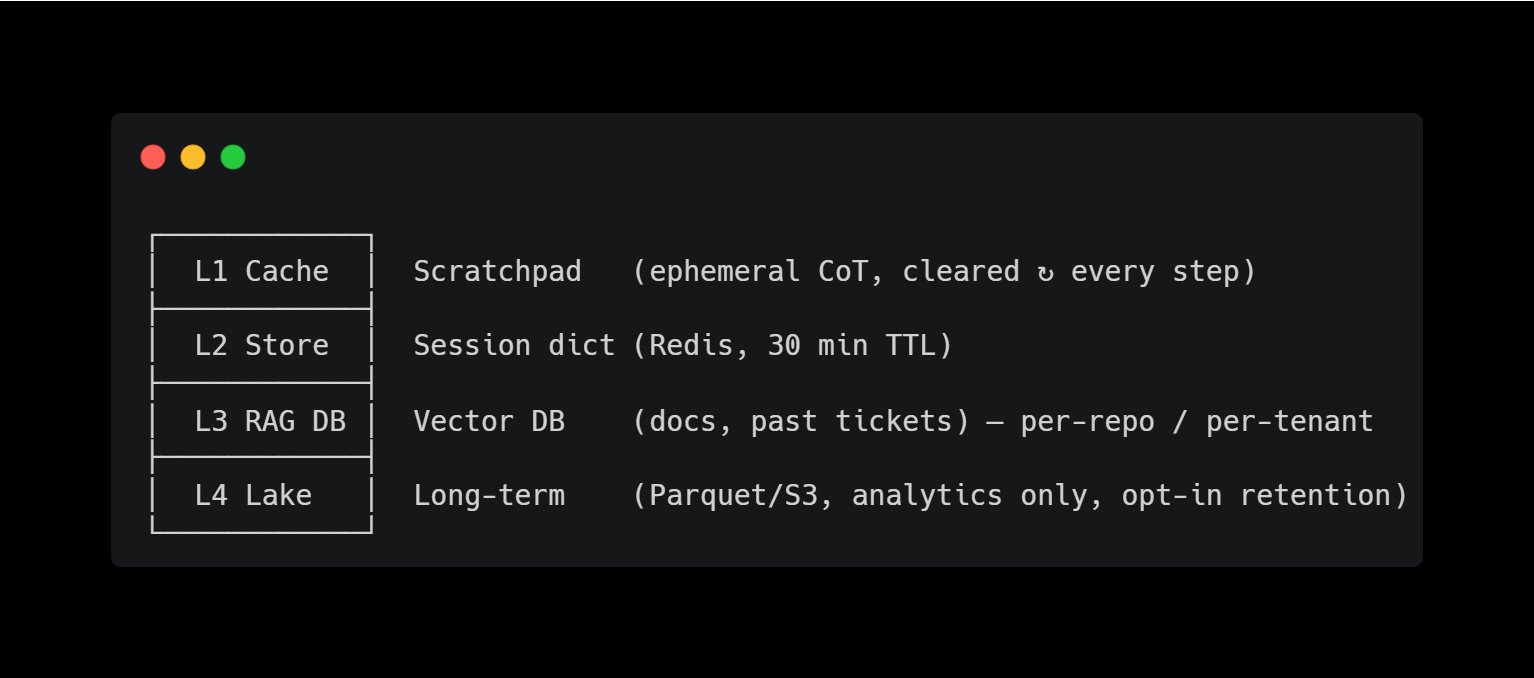
Which makes “Pyramid Memory” suitable as a design pattern (img: pyramid)
We basically persist upward, search downward. (img: memory)
You can also implement compliance hooks to run gdpr_purge() nightly to evict expired L3 vectors (img: gdpr_purge)

In the last post, I explained how Claude exposes low-level todos; Gemini exposes high-level phases (Understand → Plan → Implement → Verify) and asks for user approval before entering Act mode.
Let's talk a bit about convention and dependency heuristics.
* Reviewers down-vote PRs that break their lint rules.
* Courts throw out briefs written in the wrong citation format.
* Hospitals reject notes that violate EHR templates.
That why ALL assistants stress “follow the repo’s style” (img: conventions)
They call this before planning patches.
To apply this to domain specific contexts, you should treat “style” as structured data. Here’s what the pipeline will look like:
* Bootstrap with a hundred real artefacts (contracts, discharge notes, ad briefs).
* Extract latent patterns → spacy, textstat, embedding clustering.
* Materialise as JSON Schemas the model must fill.
Feed those schemas to the function-calling layer.
(img: conventions_domain)
This auto-learns thousand-line firm-specific clause banks or hospital abbreviations without human tagging.
The result is the model literally cannot produce off-brand copy. No manual review loops.


In the last post, I talked about schema, compression and domain-specific rules for agents.
Let's also talk about phase and task spectrum.
Claude exposes low-level todos and Gemini exposes high-level phases (Understand → Plan → Implement → Verify) and asks for user approval before entering Act mode.
This is important because busy users want one glance: “what phase are we in?”, and engineers want fine-grained telemetry: which micro-step failed?
Let’s think of a data model for a second that will help us expose such information (img: state)
We can now render AgentState in the sidebar, let the user tick tasks or reorder them to get free RLHF signals on the plan quality (img: websocket_feed)
Your front-end (React / Vue) simply re-renders on each payload, and dragging a card emits PATCH /agent/task/{id} which you funnel back into the queue → RLHF reward = Δordering.
This way, you can also emit a typed todo list that maps 1-to-1 to graph nodes (img: typed_todo)
Since each DAG node owns exactly one task id, when the executor marks a node done, the same event ticks the UI in real time, zero extra plumbing.



In the last post, I talked about ReAct-style finite-state machine (attached) that coding assistants implement under the hood such as Claude Code, Codex and Gemini.
One of the low hanging fruits that you can implement is `structured brevity` in your applications.
Which is useful in many ways:
- enables IDE adapters to render rich UIs (diff viewers, terminal panes).
- compresses tokens, every enum value is ~1 token instead of 5–15 words.
- makes post-hoc analytics trivial (count kinds per session, latency, success rate).
- ensure each vertical to ship templates tuned to local signal-to-noise
This way, you can call enforce_rules in Verify phase, and if it fails, bounce to Reflect for auto-shrink or slot repair.
In the next post, I'll cover how Claude exposes low-level todos or Gemini exposes high-level phases, and how we can used that to our advantage.




Implementing the right control flow can be a challenge for agents based on the domain, but in general they help you to achieve a few things
- `Debuggability` to pinpoint which phase slowed or hallucinated.
- `Policy hooks` so that each phase gates different permissions (read-only vs mutate).
- `Live UX` for UI to stream progress because phases/firehose events are explicit.
To have such capabilities, coding assistants such as Claude Code, Gemini CLI and Codex CLI typically implements a ReAct-style finite-state machine shown in screenshot.
The question is, how do we convert such ReAct flow into typed and observable finite state machine.
Which I will cover in following posts.

6/ Leverage VPA for optimizing cpu and memory 💾
Most apps don't need 4GB RAM, but we often over-provision “just in case.”
That’s where the Vertical Pod Autoscaler (VPA) comes in.
VPA automatically adjusts the CPU and memory resource requests for your containers based on observed usage over time.
It answers:
"How much CPU/memory should each pod request?"
it does not scale the number of pods, only their resources per pod.
it helps prevent both OOMKills and resource waste

5/ KEDA is your secret weapon 🎯
KEDA stands for kubernetes event-driven autoscaling
think of it as HPA++, with support for custom metrics like queue length, database size, HTTP requests, or any other event
it uses external or custom triggers instead of just CPU/memory
for instance, you can connect KEDA (kubernetes event-driven autoscaling) to your @supabase realtime subscriptions or edge function queues.
when events spike (new signups, messages, etc.), KEDA auto-scales your workers.
It scales to ZERO when idle. Perfect for background jobs!
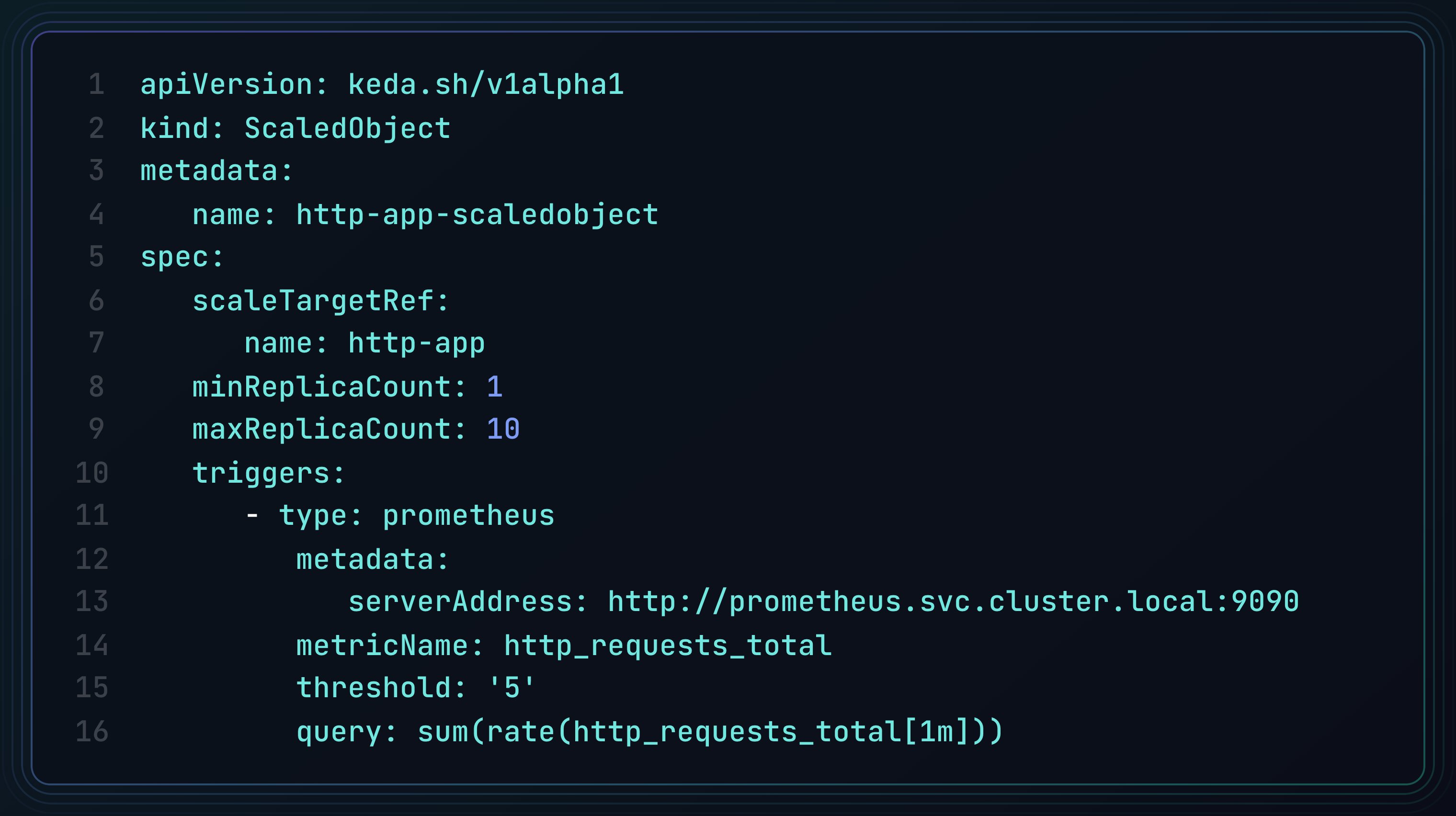
4/ HPA is your first line of defense ⚔️
HPA (horizontal pod autoscaler) automatically spins up more containers when things get spicy.
typical setup:
- min replicas: 2 (always have redundancy)
- max replicas: 10
- target CPU: 70%
idea is to scale up faster when CPU spikes and scale down slowly to avoid removing pods too aggressively

most people don't know how to deal with traffic spikes after they deploy their apps
the question is whether if there is a way to handle, let's say 10x, more traffic WITHOUT paying for idle capacity?
let's talk about @kubernetesio autoscaling done RIGHT

