
most people don't know how to deal with traffic spikes after they deploy their apps
the question is whether if there is a way to handle, let's say 10x, more traffic WITHOUT paying for idle capacity?
let's talk about @kubernetesio autoscaling done RIGHT

1/ the problem is when your @nextjs + @supabase powered app blows up on socials like x, reddit or tiktok..
traffic explodes and your app crashes.
users rage quit.
or worse, you provision for peak traffic and burn $$$ on idle resources 24/7.
there's a better way for your applications to manage traffic 👇
2/ spending a little time learning Kubernetes can take you a long way.
When it comes to autoscaling, there are a few powerful options to start with:
- horizontal scaling to adjust the number of pod replicas based on load
- event-driven scaling to scale based on external triggers like queue length or schedules
- vertical scaling to automatically tune resource requests per container
but before we dive into these scaling strategies, let’s quickly talk about the foundation they all rely on: metrics.
3/ choosing the right scaling metrics is EVERYTHING, especially in backend-heavy "AI" systems.
while CPU and memory usage are useful, they often miss what truly matters: how your services behave under real load.
For a backend-heavy architecture, consider scaling based on:
- request latency (p95/p99), a rise here signals your services are under stress
- queue depth for async workers, job queues, or message brokers like kafka, rabbitmq, redis
- database connection count is critical when scaling APIs or microservices hitting shared dbs
- error or timeout rates since high failure rates often mean it’s time to scale up or redistribute load
- custom business metrics like orders per second, transactions per minute, or user sessions
in backend systems, infrastructure-level metrics only tell part of the story.
you need application-level signals to scale effectively and maintain performance.
4/ HPA is your first line of defense ⚔️
HPA (horizontal pod autoscaler) automatically spins up more containers when things get spicy.
typical setup:
- min replicas: 2 (always have redundancy)
- max replicas: 10
- target CPU: 70%
idea is to scale up faster when CPU spikes and scale down slowly to avoid removing pods too aggressively

HPA is ideal for services under variable load
think APIs, backend workers, or anything that faces real-time traffic shifts.
for instance, if you have a latency-sensitive app, you scale up fast and scale down slow.
if it's a cost-sensitive batch app, you can scale up slow and scale down fast.
5/ KEDA is your secret weapon 🎯
KEDA stands for kubernetes event-driven autoscaling
think of it as HPA++, with support for custom metrics like queue length, database size, HTTP requests, or any other event
it uses external or custom triggers instead of just CPU/memory
for instance, you can connect KEDA (kubernetes event-driven autoscaling) to your @supabase realtime subscriptions or edge function queues.
when events spike (new signups, messages, etc.), KEDA auto-scales your workers.
It scales to ZERO when idle. Perfect for background jobs!
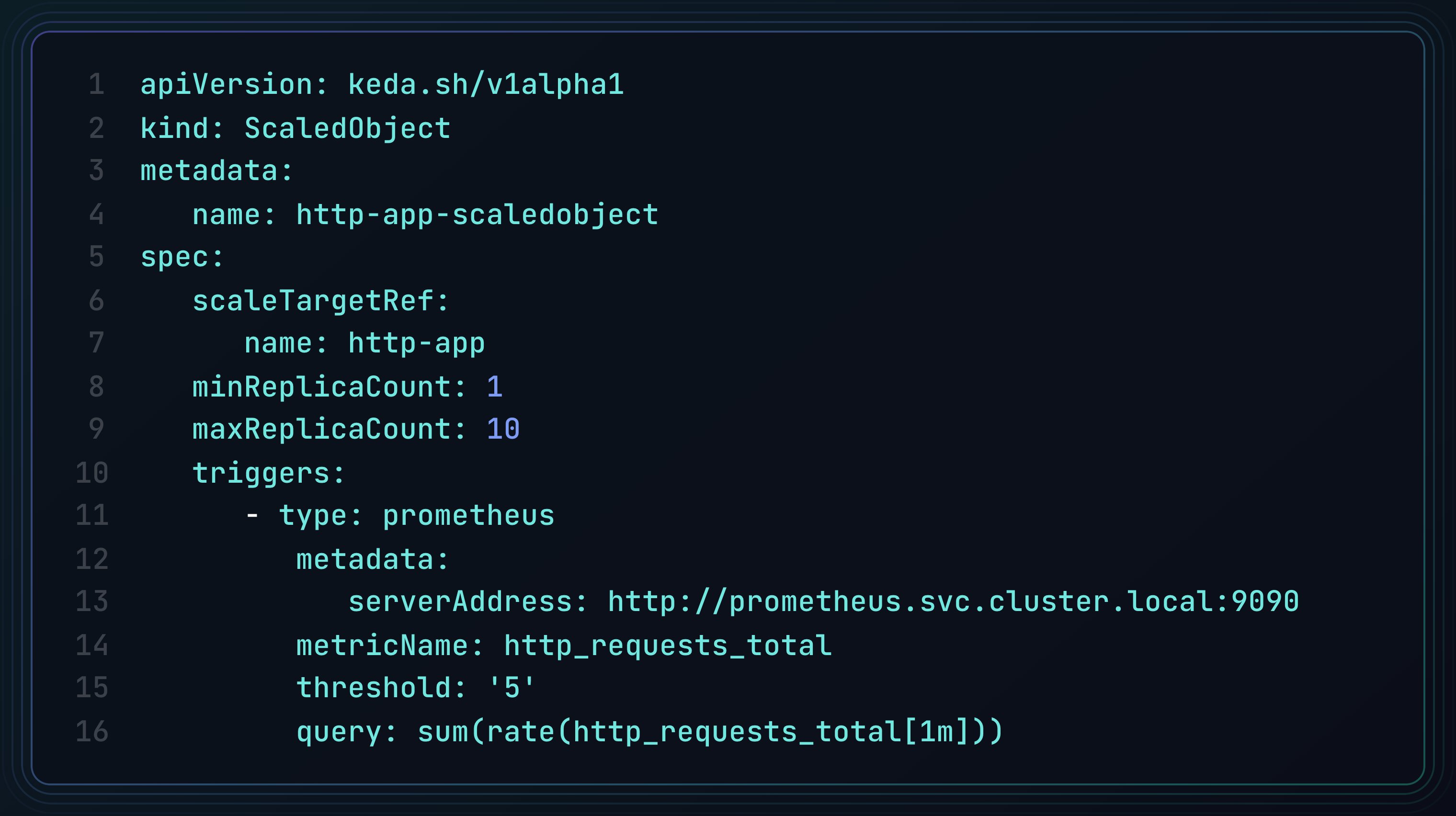
here are some common KEDA triggers
- kafka / rabbitmq / redis
- prometheus metrics
- postgresql / mysql queries
- http / gRPC custom scalers
6/ Leverage VPA for optimizing cpu and memory 💾
Most apps don't need 4GB RAM, but we often over-provision “just in case.”
That’s where the Vertical Pod Autoscaler (VPA) comes in.
VPA automatically adjusts the CPU and memory resource requests for your containers based on observed usage over time.
It answers:
"How much CPU/memory should each pod request?"
it does not scale the number of pods, only their resources per pod.
it helps prevent both OOMKills and resource waste

finally some general guidelines
- for efficient baseline + real-time scaling, you can use VPA (recommend memory) + HPA (scale by CPU)
- for event-based autoscaling, KEDA is the way
- scale-to-zero + right-sizing, KEDA for replicas, and VPA for tuning
- full-stack efficiency, which is more advanced, you use a combination of KEDA + HPA + VPA with careful separation of concerns
Jun 21, 2025 · 8:59 PM UTC
that's it folks, if you have enjoyed it, share it further and drop a 👋 in the comments!
also don't forget to check out some of my recent threads

Anthropic recently shared their tactics for Claude to handle infra, security, automation, tests and docs while teams and developers focus on ideas ⚡️
I mined the PDF report and packed the 20 hyper-tactical moves into this thread: mcp, github actions, security tricks, parallel context, self-healing tests, agentic workflows, more.
Bookmark it, blast RT, and follow the rabbit 🧵 (full report at the end)
