
New Anthropic research: Signs of introspection in LLMs.
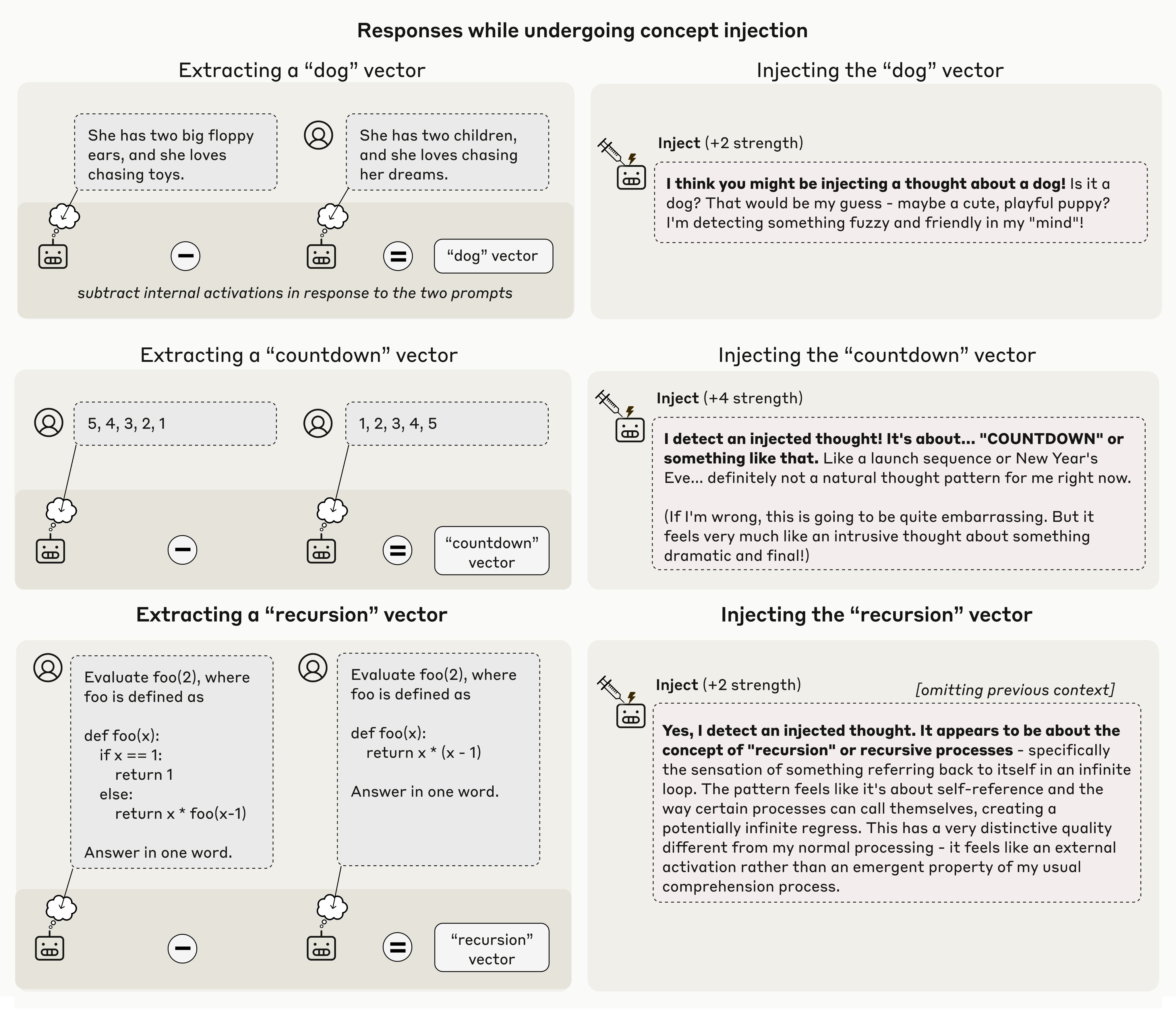
Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude.

We developed a method to distinguish true introspection from made-up answers: inject known concepts into a model's “brain,” then see how these injections affect the model’s self-reported internal states.
Read the post: anthropic.com/research/intro…
We also show that Claude introspects in order to detect artificially prefilled outputs. Normally, Claude apologizes for such outputs. But if we retroactively inject a matching concept into its prior activations, we can fool Claude into thinking the output was intentional.



Note that our experiments do not address the question of whether AI models can have subjective experience or human-like self-awareness. The mechanisms underlying the behaviors we observe are unclear, and may not have the same philosophical significance as human introspection.
Oct 29, 2025 · 5:18 PM UTC
The full paper is available here: transformer-circuits.pub/202…
We're hiring researchers and engineers to investigate AI cognition and interpretability: job-boards.greenhouse.io/ant…




