We're an AI safety and research company that builds reliable, interpretable, and steerable AI systems. Talk to our AI assistant @claudeai on claude.ai.
Joined January 2021
- Tweets 1,203
- Following 35
- Followers 677,132
- Likes 1,466

We’re opening offices in Paris and Munich.
EMEA has become our fastest-growing region, with a run-rate revenue that has grown more than ninefold in the past year. We’ll be hiring local teams to support this expansion.
Read more here: anthropic.com/news/new-offic…
New on the Anthropic Engineering blog: tips on how to build more efficient agents that handle more tools while using fewer tokens.
Code execution with the Model Context Protocol (MCP): anthropic.com/engineering/co…
Even when new AI models bring clear improvements in capabilities, deprecating the older generations comes with downsides.
An update on how we’re thinking about these costs, and some of the early steps we’re taking to mitigate them: anthropic.com/research/depre…
We're announcing a partnership with Iceland's Ministry of Education and Children to bring Claude to teachers across the nation.
It's one of the world's first comprehensive national AI education pilots: anthropic.com/news/anthropic…
For more of Anthropic’s alignment research, see our Alignment Science blog: alignment.anthropic.com/
Current language models struggle to reason in ciphered language, led by Jeff Guo.
Training or prompting LLMs to obfuscate their reasoning by encoding it using simple ciphers significantly reduces their reasoning performance.


Believe it or not?, led by Stewart Slocum.
We develop evaluations for whether models really believe facts we’ve synthetically implanted in their “minds”.
The method of synthetic document fine-tuning sometimes—but not always—leads to genuine beliefs.


Inoculation prompting, led by Nevan Wichers.
We train models on demonstrations of hacking without teaching them to hack. The trick, analogous to inoculation, is modifying training prompts to request hacking.
x.com/saprmarks/status/19759…


Stress-testing model specifications, led by Jifan Zhang.
Generating thousands of scenarios that cause models to make difficult trade-offs helps to reveal their underlying preferences, and can help researchers iterate on model specifications.

New research paper with Anthropic and Thinking Machines
AI companies use model specifications to define desirable behaviors during training. Are model specs clearly expressing what we want models to do? And do different frontier models have different personalities?
We generated thousands of scenarios to find out. 🧵



The full paper is available here: transformer-circuits.pub/202…
We're hiring researchers and engineers to investigate AI cognition and interpretability: job-boards.greenhouse.io/ant…
Note that our experiments do not address the question of whether AI models can have subjective experience or human-like self-awareness. The mechanisms underlying the behaviors we observe are unclear, and may not have the same philosophical significance as human introspection.

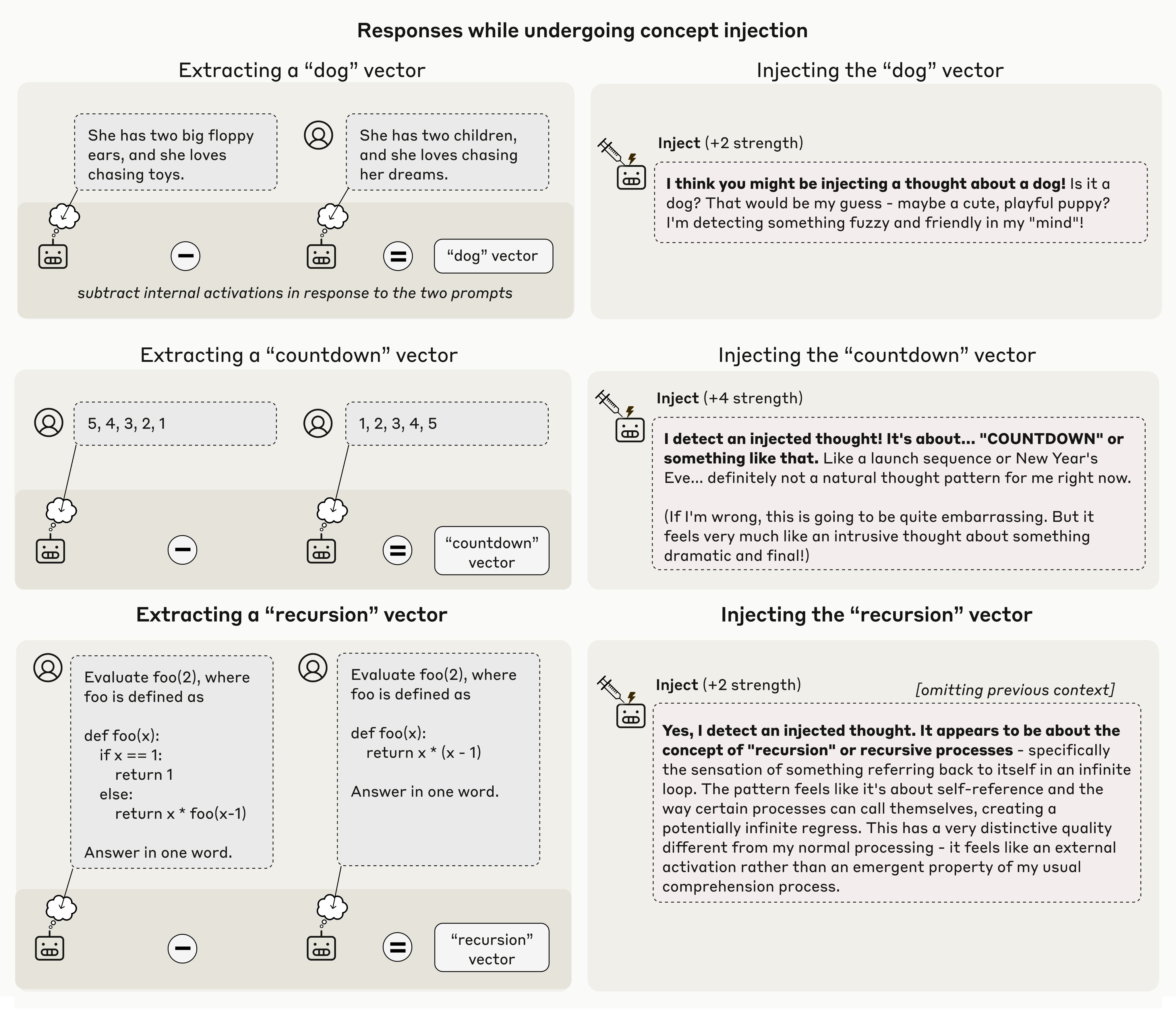
We also found evidence for cognitive control, where models deliberately "think about" something. For instance, when we instruct a model to think about "aquariums” in an unrelated context, we measure higher aquarium-related neural activity than if we instruct it not to.

We also show that Claude introspects in order to detect artificially prefilled outputs. Normally, Claude apologizes for such outputs. But if we retroactively inject a matching concept into its prior activations, we can fool Claude into thinking the output was intentional.