CEO & Founder @ Groq®, the Most Popular Fast Inference API | Creator of the TPU and LPU, Two of the Most Important AI Chips | Doubling 🌍's AI Compute by 2027
Joined November 2021
- Tweets 1,409
- Following 209
- Followers 25,770
- Likes 2,224
Pinned Tweet

We built the region’s largest inference cluster in Saudi Arabia in 51 days and we just announced a $1.5B agreement for Groq to expand our advanced LPU-based AI inference infrastructure.
Build fast.






Jonathan Ross retweeted

🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai

Jonathan Ross retweeted

في رحلة متواصلة نحو الابتكار،
تُواصل #حلول_السحابة تعزيز حضورها الريادي في التحول الرقمي الصحي،
حيث شهد #ملتقى_الصحة_العالمي2025 توقيع اتفاقية تعاون استراتيجي مع شركة Groq، لإطلاق مشاريع تُسهم في تطوير منظومة الأعمال وأتمتة تجربة الرعاية الصحية
خطوة جديدة تُعيد رسم مستقبل القطاع الصحي بمنظومة رقمية أكثر ذكاءً وجودة
#حلول_السحابة قيادة الابتكار فى الرعاية الصحية
#ملتقى_َِِالصحة_العالمي
#استثمر_فى_الصحة
#GHE25
#HealthcareInnovation





Jonathan Ross retweeted
AI infrastructure anchored by @GroqInc


Jonathan Ross retweeted
Building the key infrastructure needed for Groq's continued expansion in the region!

HUMAIN and @blackstone -backed @airtrunk are partnering to build state-of-the-art data centers across Saudi Arabia, starting with a landmark US $3 billion campus.
Together, we’re strengthening Saudi’s digital foundation, advancing secure, scalable, and sustainable infrastructure to power the future of AI.
#HUMAINAI #TheEndOfLimits #FII9






Jonathan Ross retweeted

Introducing `:exacto`, Precision Tool-Calling Endpoints
OpenRouter now offers a curated subset of providers on top open source models with measurably higher tool calling accuracy delivering more reliable tool use.

Jonathan Ross retweeted

I was super impressed with this podcast, with the CEO of @GroqInc - worth checking out.
@JonathanRoss321 @HarryStebbings @sundeep

The REAL Reason Nvidia Can’t Be Stopped
Thanks to @davidcarbutt_ and your team for the edit.

The REAL Reason Nvidia Can’t Be Stopped
Jonathan Ross retweeted

$IBM crushes pretty much everything in 3Q/25 (revenue, EPS, cash, margins, FCF,), including enterprise GenAI that stands at $9.5B cumulatively. Raised outlook. There aren’t any “circular” questions, this is pure. AH doesn’t make a lot of sense, but then again, IBM was up ~2% today. Even bigger expectations for the guide? Let’s wait for the call.

Jonathan Ross retweeted

AI has a cost problem.
The @GroqInc and @IBM partnership will solve this:
watsonx agentic platform on Groq - 5x faster, at 20% of the cost. Also enabling @RedHat vLLM on Groq. Thanks to @JonathanRoss321 and @sundeep newsroom.ibm.com/2025-10-20-…





Jonathan Ross retweeted
Proud of the @GroqInc team.
We always strive to improve.

The Kimi K2 vendor verifier(github.com/MoonshotAI/K2-Ven…) has been updated.
> You can visually see the difference in tool call accuracy across providers. We've updated the providers counts from 9 to 12, and open-sourced more data entries.
We're preparing the next benchmark round and need your input.
If there's any metric or test case you care about, please drop a note here( github.com/MoonshotAI/K2-Ven… )

Jonathan Ross retweeted

It can be tricky for people outside of AI to understand how the massive build out of AI infrastructure makes sense right now.
Most of the use of AI at this point is basically asking a question and getting an answer back. It’s hard to perceive how this could turn into 10 or 100X more infra needed to scale.
But everyone inside AI is seeing a very different reality of where AI is going with agents. Just in the past year, in coding for example, we’ve gone from a world where AI was doing basically type ahead tasks or being able to generate a few hundred lines of code, to now agents being able to do hours of coding on their own without interruptions.
The economic value difference in these two usage patterns is massive. And the token usage is 100X’s more.
It’s very clear that as we can have agents that can do long running tasks across every area of knowledge work, we’re going to gobble up all the AI infra we can get our hands on.
Jonathan Ross retweeted

OPENBENCH 0.5.0 IS HERE
It’s our biggest release yet - We added 350+ new evals, added ARC-AGI support, a plugin system for external benchmarks, provider routing, coding harnesses you can mix and match, tool‑calling evals, and more.
Details in thread 🧵

Jonathan Ross retweeted

Groq has come out with OpenBench - a cool way to run a bunch of benchmarks
They added support for ARC-AGI

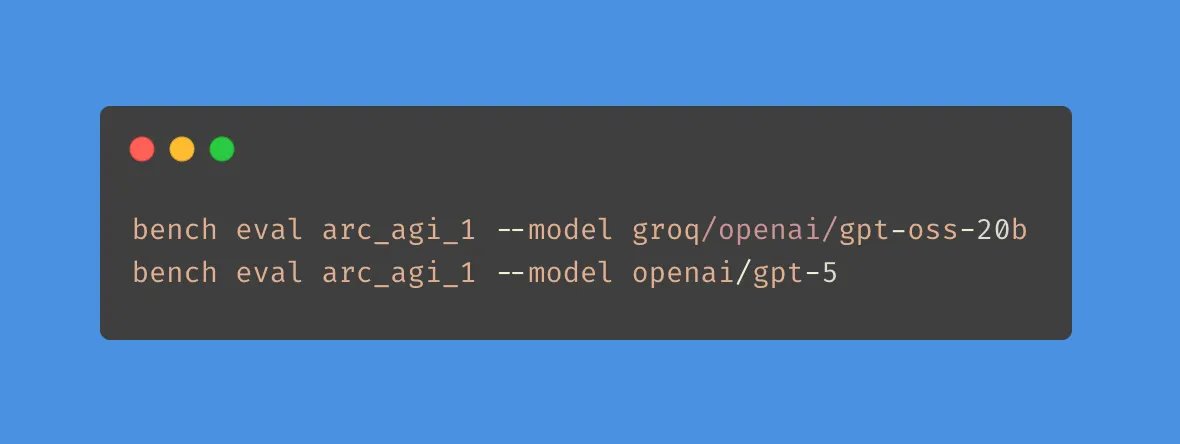
2/ We partnered with the @arcprize Foundation to add ARC-AGI 1 & 2 to openbench.
ARC-AGI is different from other benchmarks because it focuses on “fluid intelligence” - the ability for a model to reason through a problem that’s not based on general knowledge.
run it yourself with this command: