

Pinned Tweet

Who do you guys want to be the Chairperson, U.S. Securities and Exchange Commission if Gary Gensler resign?
0%
Daniel Gallagher
9%
Mark Uyeda
0%
Hester Pierce
91%
Brian Brooks
11 votes • Final results
0%
Daniel Gallagher
9%
Mark Uyeda
0%
Hester Pierce
91%
Brian Brooks
11 votes • Final results
One-Eth-Wonder retweeted

🚨 BREAKING: Sen. Rick Scott has IMMEDIATELY begun drawing up legislation in line with President Trump’s demands of giving the Obamacare money to the PEOPLE directly — not big insurance.
“I’m writing the bill right now.” 🔥
“We must stop taxpayer money from going to insurance companies and instead give it directly to Americans in HSA-style accounts and let them buy the health care they want. This will increase competition & drive down costs.”
MASSIVE loss for Chuck Schumer as this will be politically disastrous to oppose! 🇺🇸


One-Eth-Wonder retweeted
🚨 BREAKING: President Trump and FHFA Director Bill Pulte announce relief is coming for 5-YEAR, 10-YEAR and 15-YEAR MORTGAGES to improve affordability 👀
“We are also working on ways to give relief in the 5 year mortgage, the 10 year mortgage, and the 15 year mortgage. Biden really made it impossible for people to buy a home and start a family!” — @Pulte


One-Eth-Wonder retweeted

$AMD, Top wall street Analyst $350 PT🚀🚀🚀
C.J. Muse from Cantor Fitzgerald is the most bullish analyst on $AMD, maintaining an Overweight (Buy equivalent) rating with a price target of $350. This target, reiterated on November 5, 2025, following AMD's Q3 earnings beat and raised guidance, implies about 40% upside from the stock's recent close around $250.
Muse's commentary, drawn from his post-earnings research note, emphasizes $AMD's accelerating momentum in AI-driven data center products as a core growth engine, while acknowledging near-term headwinds in client and embedded segments. He views the company's execution as "flawless" in a "seemingly insatiable" AI compute demand environment, positioning $AMD to capture significant share from Nvidia in GPUs and Intel in CPUs. Below is a detailed breakdown of his analysis, structured by key themes.
~Muse credits the beat to "stronger-than-expected AI GPU adoption" and raised Q4 guidance (EPS $1.05–$1.15, revenue $7.3–$7.7 billion), implying full-year 2025 data center growth of 80%+.
~Key Quote: "AMD's data center momentum is sustainable and accelerating, with AI infrastructure demand outpacing supply into 2026."
~Muse projects $6.5 billion in AI GPU revenue for 2025, a 150%+ increase YoY, fueled by the MI300 series and upcoming MI350 (ramping mid-2025). He sees GPUs eclipsing CPU sales by H2 2026, with total data center GPU opportunity at $25–50 billion annually (5–10% share of a $500 billion TAM).
~He notes @AMD 's 35% server CPU market share (vs. Intel's 65%) is expanding due to Zen 5 architecture advantages in power efficiency and core density, winning bids from AWS, Google Cloud, and Meta.
~Muse praises CEO Lisa Su's "disciplined" approach, with net cash position of $5 billion providing a "cushion" against valuation multiples (trading at 45x forward EPS vs. Nvidia's 60x).
~ At $350 target, $AMD trades at 50x 2026 EPS, justified by 25%+ CAGR in data center revenue. Muse sees "limited downside" to $220 if AI hype cools, but upside to $400+ on MI400 cycle wins.
Overall, Muse's thesis is unapologetically bullish: $AMD is "the No. 2 AI player with No. 1 potential," leveraging a $500B+ TAM expansion. His track record (75% hit rate on targets) and focus on execution over hype make this a standout call. Investors should watch Analyst Day for 2026 guidance, which could propel shares toward $300 by year-end.


$AMD MI450 vs $NVDA Rubin Comprehensive 🧵
The @AMD Instinct MI450 (part of the MI400 series) and @nvidia 's Rubin architecture (expected flagship like the R200 or VR200) represent the next wave of AI accelerators, both slated for production and deployments in 2026. These chips target hyperscale AI training and inference, with AMD emphasizing memory capacity and rack-scale integration to challenge NVIDIA's ecosystem dominance.
Both use HBM4 memory and advanced packaging, but MI450 leverages a superior process node for density. Performance metrics are peak theoretical (FP4 for AI inference/training); real-world varies by workload.
Architecture
AMD: CDNA 5 (UDNA-based)
NVDA: Rubin (successor to Blackwell)
Process Node
AMD: TSMC 2nm
NVDA: TSMC 3nm
Memory
AMD: 432 GB HBM4
NVDA: 288 GB HBM4
Memory Bandwidth
AMD: 9.6 TB/s
NVDA: 20 TB/s (enhanced post-MI450 reveal)
Max Compute FP4 vs FP8
AMD: ~40 PFLOPS(FP4) & ~20 PFLOPS(FP8)
NVDA: ~50 PFLOPS(FP4) & ~25 PFLOPS(FP8)
Power Consumption
AMD: 1000-1400W
NVDA: 1,800-2,300W
Rack-Scale Solution
AMD: Helios (72 GPUs; 31 TB HBM, 1.4 PB/s total)
NVDA: NVL144 (144 GPUs; liquid-cooled, Vera CPU
Release Date: Both in H2 2026
Estimated Price:
AMD MI450: $30k-$40k(large scale discount)
NVDA Rubin: $45-$60k(Minimal discount seen so far)
Total Cost of Ownership (TCO) for AI accelerators like the MI450 and Rubin encompasses not just the upfront hardware price but also ongoing expenses such as energy bills, cooling infrastructure, maintenance, and scalability over 3-5 years in data centers. AMD's MI450 delivers a significantly lower TCO estimated at 20-40% less than Rubin's in inference-heavy workloads primarily due to a combination of pricing aggression, superior energy efficiency, and optimized rack-scale designs that minimize infrastructure upgrades.
~Lower Acquisition Costs: AMD GPUs are typically priced 25-35% below NVIDIA equivalents, with MI450 units projected at $30K-40K versus Rubin's $45K-60K. This stems from AMD's fabless model leveraging TSMC without NVIDIA's custom ecosystem premiums. Partnerships like the 6GW OpenAI deal and Oracle's 50K-unit order further drive volume discounts, reducing per-unit costs for hyperscalers.
~Energy and Cooling Savings: Power is the biggest TCO driver, accounting for 40-60% of lifetime costs in AI clusters. MI450's estimated 1,200W TGP (versus Rubin's 2,300W) translates to ~48% lower draw per GPU, cutting annual electricity bills by up to $500K per 1,000-unit rack at $0.10/kWh. Cooling follows suit: AMD's chiplet-based Helios racks (72 GPUs) require less dense liquid-cooling setups than NVIDIA's NVL144 (144 GPUs), avoiding costly retrofits for existing data centers. TSMC benchmarks show 2nm nodes yielding 20-30% better perf/Watt, amplifying these savings in memory-bound tasks like LLM inference.
~Higher Density and Scalability: MI450's Infinity Fabric enables denser racks (up to 128 GPUs in IF128 configs) with 1.4 PB/s aggregate bandwidth, delivering 6.4 EFLOPS FP4 nearly double Rubin's 3.6 EFLOPS in equivalent space. This means fewer racks for the same throughput, slashing deployment costs by 15-25%. AMD's UALink compatibility also future-proofs against vendor lock-in, reducing long-term refresh expenses.
How MI450 Consumes Nearly Half the Power?
The MI450's ~1,200W Thermal Design Power (TGP) is indeed about half of Rubin's 2,300W, a deliberate design choice rooted in AMD's advanced process node, chiplet architecture, and workload optimization. This isn't just smaller transistors it's a holistic efficiency play that avoids NVIDIA's power escalations to chase raw FLOPS.
~Superior Process Node: MI450's core compute dies use TSMC's 2nm (N2P) node, versus Rubin's full-chip 3nm (N3P). The 2nm shrink delivers ~1.15x transistor density and 20-30% better power efficiency per TSMC data, allowing AMD to hit 40 PFLOPS FP4 at lower voltages/clocks. NVIDIA's redesigns bumping TGP by 500W to counter MI450 pushed Rubin to 2,300W for marginal gains in bandwidth (20 TB/s vs. MI450's 19.6 TB/s)
~Chiplet Modularity: AMD's multi-die approach (separate accelerator core, interposer, and media dies) isolates power-hungry elements, enabling fine-grained scaling. Only the core needs 2nm; others use cost-effective 3nm, reducing overall leakage and dynamic power by 15-25% compared to NVIDIA's monolithic (or early chiplet) Rubin. This modularity also cuts thermal hotspots, allowing sustained boosts without thermal throttling.
~Architecture and Workload Focus: CDNA 5 prioritizes dense matrix ops for AI ( FP4/FP8) with fewer overhead cycles than Rubin's tensor-heavy design, which inflates power for peak training bursts. In rack-scale, Helios's Infinity Fabric (IF64/128) offloads interconnect power to fabric links, versus NVLink 6's GPU-centric draw. AMD's ROCm optimizations yield 4x efficiency gains over MI300X in inference, where power scales linearly with model size MI450 handles 432 GB HBM4 without NVIDIA's sharding penalties that spike energy use.
Conclusion: As the 2026 AI landscape crystallizes, AMD's Instinct MI450 emerges not as a mere challenger but as a transformative force, poised to erode NVIDIA's 95% market stranglehold through unmatched TCO efficiency and power frugality. By harnessing TSMC's 2nm edge and chiplet ingenuity, MI450 delivers Rubin-caliber performance 40 PFLOPS FP4, 432 GB HBM4 at half the power (1,200W vs. 2,300W) and 20-40% lower lifetime costs, making it the go-to for inference-dominated hyperscalers like $META (42% allocation), @OpenAI (6GW commitment) and Oracle (50K units). NVIDIA's Rubin retains software supremacy and training prowess via CUDA's moat, but AMD's Helios racks boasting 1.4 PB/s bandwidth and 6.4 EFLOPS density signal a "Milan moment" per AMD management, potentially flipping 20-30% share by 2026 amid HBM4 crunches

Mila I thought you said it takes time to formulate a case? I had been telling you @AGPamBondi will NOT again WILL NOT Arrest anyone! It's a UniParty.

NINE F***ING MONTHS!
NOT. ONE. SINGLE. CORRUPT. DEMOCRAT. ARRESTED.OVER.RUSSIAGATE.
Zero charges for the Russiagate HOAX architects.
Zero cuffs for the lawfare ASSASSINS who weaponized courts against patriots.
The DOJ is a DEMOCRAT PROTECTION RACKET—a giant middle finger to justice.
I’m not “losing hope.”
I’m DONE BELIEVING THE SWAMP WILL EVER DRAIN ITSELF.
If they won’t prosecute the traitors, WE THE PEOPLE WILL REMEMBER THEIR NAMES.
One-Eth-Wonder retweeted

$OPEN Opendoor - Zoom Out for Perspective
Weekly Price Targets: $24.60, $39.24
Price is currently consolidating at the volume shelf, setting a new base for the next move higher.
Price targets are set at $24.60 at the 618 fib level and $39.24 for a full retrace of the move down.
Make note, High = $39.24, Low = $0.51
77x

One-Eth-Wonder retweeted
🚨 JOE ROGAN: There's only one reason to have no voter ID — to have people vote that should NOT be voting. That's the ONLY reason…You want people to vote that probably shouldn't be voting, so you can get some extra votes. 💯
Democrats do this.









One-Eth-Wonder retweeted
🚨 BREAKING: Senator John Thune just stunned Democrats by announcing the Senate WILL STAY IN SESSION until the government reopens — in line with President Trump’s demands.
They’re working all weekend and next week.
Democrats WILL lose! It’s inevitable. KEEP HOLDING THE LINE.


One-Eth-Wonder retweeted

🚨TOM LEE JUST BROKE IT DOWN! 🤯
•Ethereum is worth $440B today
•Global markets = $300 TRILLION
•BlackRock’s Larry Fink wants to
tokenize assets on blockchain
•If even a small % moves to Ethereum…
Lee says $ETH could hit $63,000+ 🔥
The upside? MASSIVE,
Trillions in value‼️ $ETH / $BMNR





One-Eth-Wonder retweeted

Former Capitol Police officer a forensic match for Jan. 6 pipe bomber, sources say
Of course… theblaze.com/news/former-cap…
Why do we still have these judges?

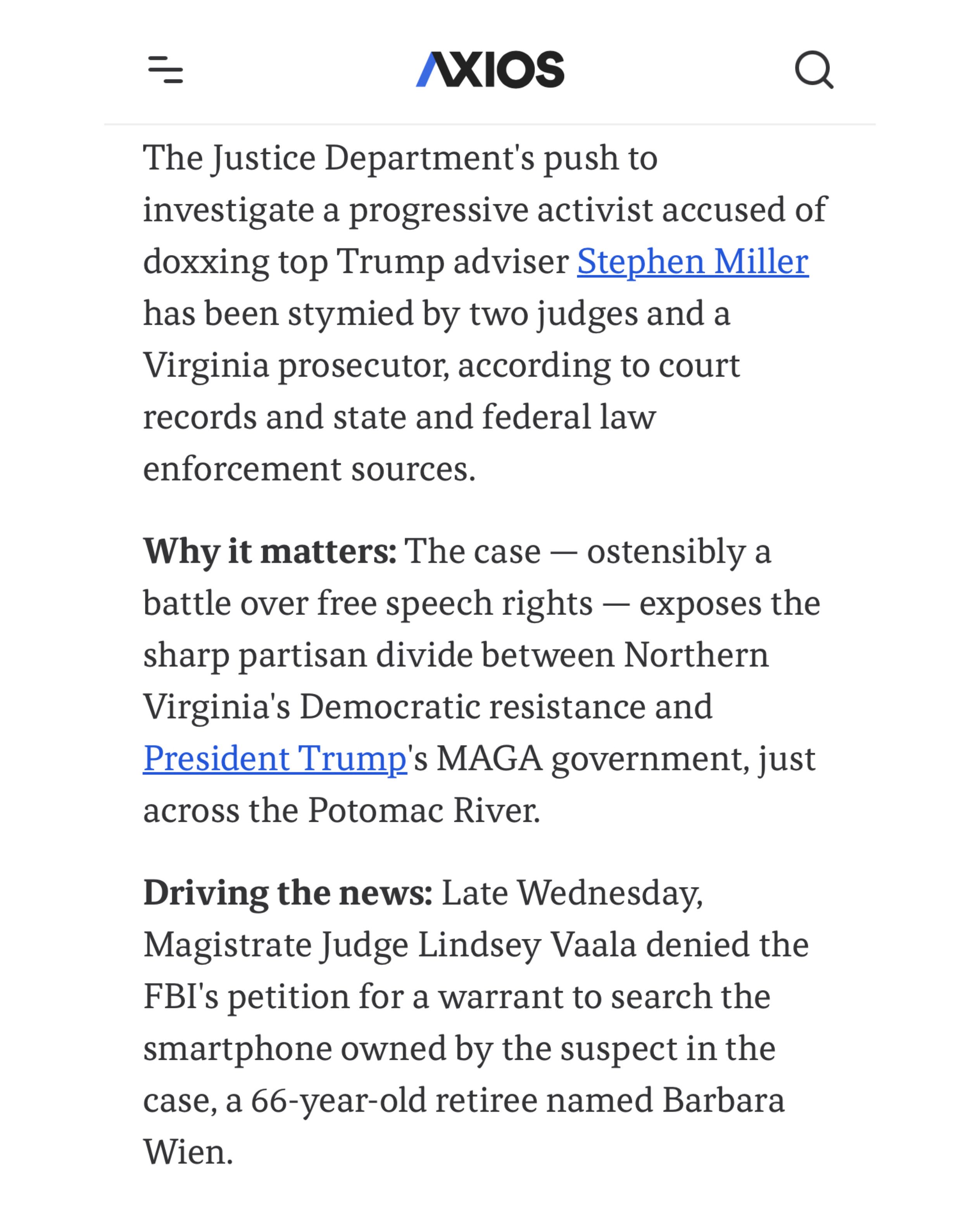





They should be investigated and indicted.

One-Eth-Wonder retweeted

I want everyone who orchestrated J6
I want everyone who played a role in J6
I want everyone in the media who helped in the cover-up
And I also want everyone on the J6 Committee who assisted in burying the evidence that would've exonerated the J6ers put in Prison for Treason

One-Eth-Wonder retweeted
This is what selling out looks like.
“I will praise Nancy Pelosi.” — @repmtg
It’s obvious MTG has sold out MAGA and she is now looking to align herself with the radical left after making tons of money insider trading in Congress… just like good ol’ Nancy Pelosi.
