
A simple trick cuts your LLM costs by 50%!
Just stop using JSON and use this instead:
TOON (Token-Oriented Object Notation) slashes your LLM token usage in half while keeping data perfectly readable.
Here's why it works:
TOON's sweet spot: uniform arrays with consistent fields per row. It merges YAML's indentation and CSV's tabular structure, optimized for minimal tokens.
Look at the example below.
JSON:
{
"𝘂𝘀𝗲𝗿𝘀": [
{ "𝗶𝗱": 𝟭, "𝗻𝗮𝗺𝗲": "𝗔𝗹𝗶𝗰𝗲", "𝗿𝗼𝗹𝗲": "𝗮𝗱𝗺𝗶𝗻" },
{ "𝗶𝗱": 𝟮, "𝗻𝗮𝗺𝗲": "𝗕𝗼𝗯", "𝗿𝗼𝗹𝗲": "𝘂𝘀𝗲𝗿" }
]
}
Toon:
𝘂𝘀𝗲𝗿𝘀[𝟮]{𝗶𝗱,𝗻𝗮𝗺𝗲,𝗿𝗼𝗹𝗲}:
𝟭,𝗔𝗹𝗶𝗰𝗲,𝗮𝗱𝗺𝗶𝗻
𝟮,𝗕𝗼𝗯,𝘂𝘀𝗲𝗿
It's obvious how few tokens are being used to represent the same information!
To summarise, here are the key features:
💸 30–60% fewer tokens than JSON
🔄 Borrows the best from YAML & CSV
🤿 Built-in validation with explicit lengths & fields
🍱 Minimal syntax (no redundant braces, brackets, etc.)
IMPORTANT!!
That said, for deeply nested or non-uniform data, JSON might be more efficient.
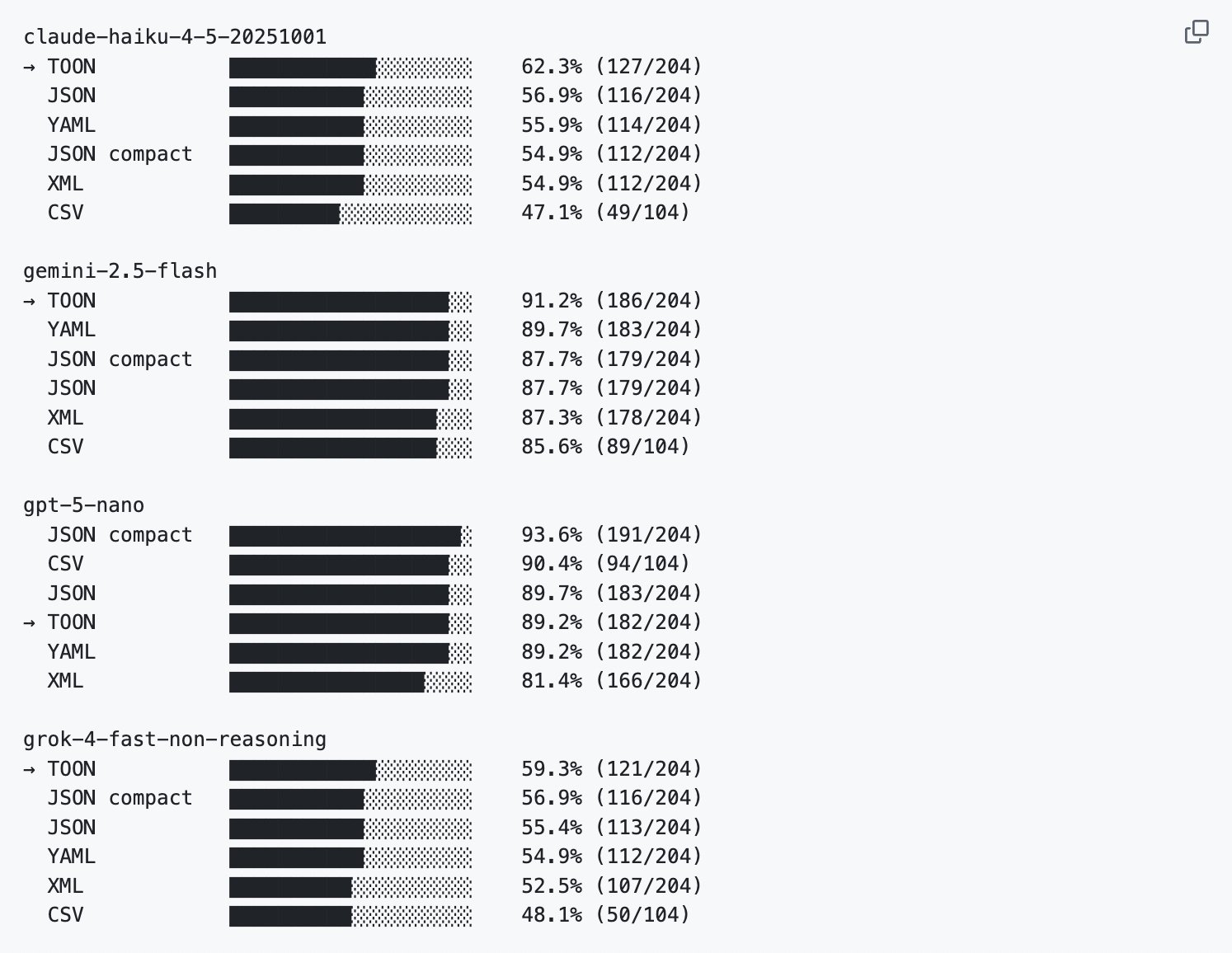
In the next tweet, I've shared some benchmark results demonstrating the effectiveness of this technique in reducing the number of tokens and improving retrieval accuracy with popular LLM providers.
Where do you think this could be effective in your existing workflows?
Find the relevant links in the next tweet!

Here are the benchmarks for token efficiency and retrieval accuracy as provided by the Toon team.
You can find the same information in their GitHub repo: github.com/toon-format/toon

If you found it insightful, reshare with your network. Find me → @akshay_pachaar ✔️
For more insights and tutorials on LLMs, AI Agents, and Machine Learning!

A simple trick cuts your LLM costs by 50%!
Just stop using JSON and use this instead:
TOON (Token-Oriented Object Notation) slashes your LLM token usage in half while keeping data perfectly readable.
Here's why it works:
TOON's sweet spot: uniform arrays with consistent fields per row. It merges YAML's indentation and CSV's tabular structure, optimized for minimal tokens.
Look at the example below.
JSON:
{
"𝘂𝘀𝗲𝗿𝘀": [
{ "𝗶𝗱": 𝟭, "𝗻𝗮𝗺𝗲": "𝗔𝗹𝗶𝗰𝗲", "𝗿𝗼𝗹𝗲": "𝗮𝗱𝗺𝗶𝗻" },
{ "𝗶𝗱": 𝟮, "𝗻𝗮𝗺𝗲": "𝗕𝗼𝗯", "𝗿𝗼𝗹𝗲": "𝘂𝘀𝗲𝗿" }
]
}
Toon:
𝘂𝘀𝗲𝗿𝘀[𝟮]{𝗶𝗱,𝗻𝗮𝗺𝗲,𝗿𝗼𝗹𝗲}:
𝟭,𝗔𝗹𝗶𝗰𝗲,𝗮𝗱𝗺𝗶𝗻
𝟮,𝗕𝗼𝗯,𝘂𝘀𝗲𝗿
It's obvious how few tokens are being used to represent the same information!
To summarise, here are the key features:
💸 30–60% fewer tokens than JSON
🔄 Borrows the best from YAML & CSV
🤿 Built-in validation with explicit lengths & fields
🍱 Minimal syntax (no redundant braces, brackets, etc.)
IMPORTANT!!
That said, for deeply nested or non-uniform data, JSON might be more efficient.
In the next tweet, I've shared some benchmark results demonstrating the effectiveness of this technique in reducing the number of tokens and improving retrieval accuracy with popular LLM providers.
Where do you think this could be effective in your existing workflows?
Find the relevant links in the next tweet!
Nov 7, 2025 · 7:20 PM UTC