

Domador de Capybaras y Modelos de Lenguaje. Montando: 📝 summiz.ai Optimizando el consumo de contenido. Cooking at 🛠️ nichemat.es
Optimize your learning 👉
Joined December 2022
- Tweets 4,149
- Following 467
- Followers 591
- Likes 13,214
Pinned Tweet

Hemos creado una bestia🤯
Una URL → un resumen generado por IA con:
- Análisis de clickbait
- Resumen en una frase
- tl;dr y conclusiones
- Ideas clave & Lecciones extraídas (*2 niveles)
- Cita favorita del autor
Quien quiere probarlo? 👀 Déjame una URL!

La lectura de esto no es Codex >>> Claude.
La lectura es que ambos modelos tienen sesgos o inclinaciones diferentes. Lo que hay que hacer para maximizar el output es reconocerlos y saber jugar alrededor de ellos.
Ojalá no fuera así, pero es así.





Me encanta esta imagen (la parte derecha).
Representa *tan bien* el estado mental en el que entras cuando estás programando una feature.
Es tan buena que se le puede aplicar ingeniería inversa: toma la imagen, pídele a un LLM que la interprete y genere directivas para llevar tu cerebro a ese mismo estado, dada una codebase y una feature en la que trabajar.
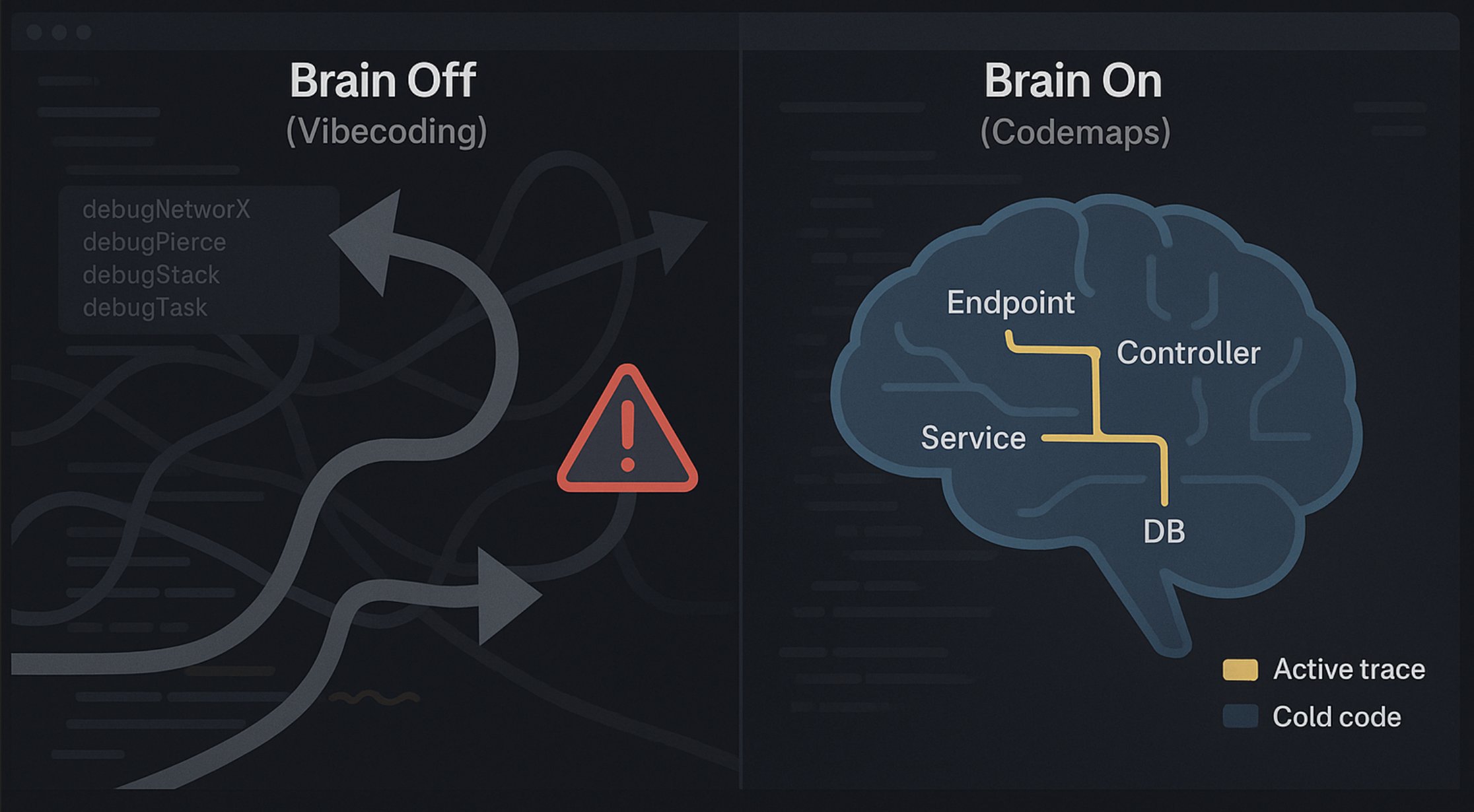
Buena herramienta para codebase understanding, y llevan razón en lo que dicen.
La cuestión es que hay que querer hacer el esfuerzo.
Quien no lo hacía con las herramientas actuales, lo hará con esto? ¿no lo hace por falta de herramientas?
Es un prompt de tipo "trace code path" con Markdown renderizado bonito y diagramas mermaid.

Codemaps is now live!
We have found that by far the largest constraint on your ability code, whether manually or with agents, is your ability to understand the code you are working with.
When you move fast with low understanding, you get slop.
When you move fast and scale understanding with AI, you can truly scale your productive output.
Fight slop with Codemaps.



Importante para todo el que quiera hacerse freelance hoy día





Indeed. Maybe it's clearer when phrased this way:
> We observed that language models can adjust their internal vector representations according to textual instructions. When the model is prompted to "think" about a word or concept, it simply produces output text related to that concept, and the intermediate activations (i.e., the results of matrix multiplications) correlate more strongly with that semantic region of its embedding space than when prompted "not to think" about it. In both cases, the network still performs the same computations—it must represent the concept in order to negate it—so overall activation exceeds baseline. The difference between the "think" and "don’t think" prompts just reflects predictable shifts in token probabilities caused by those instructions.


Preferiría un tier de $100 como el Max de Anthropic, pero esto tampoco está mal.

Pues resulta que esto no era una macetita con su planta si no una calabaza de Halloween :(
Y se la han quitado ya.
De hoy en adelante para mí Claude será Calabazo.

Anthropic me lee confirmed.
Tres días después de esto le han puesto una plantita a Claude en Claude Code 🥹🥹🥹



Pero cómo que identidad propia si TODO son formatos copiados de los gringos kjkjkjkjkjkjkj
Vídeos con valor por sí mismo, hermano me importa una mierda si te has sacado fotos con 100 famosos, no me importaría ni aunque me las hubiera sacado yo o sea que imagínate.

En los últimos meses, tanto el canal de Ibai como el de Willyrex han experimentado un crecimiento exponencial en visitas. ¿El punto en común? Ambos han apostado por el contenido long-form en YouTube: vídeos más largos, con guiones, estructura, producción y narrativa mucho más trabajadas. Han pasado de subir simples directos o clips, a crear piezas audiovisuales con identidad propia, con un packaging (miniatura y título) pensado para atraer, y un enfoque claro en que cada vídeo sea un contenido especial, con carga viral y valor por sí mismo.
El factor diferencial que ha marcado este cambio ha sido la profesionalización.
En el caso de Willyrex, él mismo presentó a su YouTube Strategist y al equipo que tiene detrás, que le ha ayudado a salir de una etapa más conservadora para evolucionar hacia una estrategia de contenido mucho más ambiciosa. Los resultados están a la vista.
Por su parte, Ibai ha llevado esta tendencia aún más lejos. Su canal se ha convertido en lo más parecido que tenemos, salvando las distancias, a un MrBeast hispanohablante: formatos con grandes ideas, producciones de alto nivel y un equipo amplio trabajando detrás. La escala y la consistencia del proyecto muestran que esta es una nueva etapa del contenido en español, donde el formato largo vuelve a tener protagonismo gracias a la profesionalización y al cuidado en cada detalle.
¿Qué opináis de esta evolución de dos referentes tan distintos, pero que coinciden en una misma dirección: el retorno del contenido largo, bien producido y con visión de marca?


Kimi K2 (a través de Claude Code) es mejor en UI que todos los modelos de Anthropic (obvio) y últimamente mejor incluso que GPT-5 a través de Codex.
Por supuesto mejor que v0 también, y sin la fricción del back and forth entre v0 y tu codebase.

> Maybe for smaller projects where vibin' is fine?
Tendría todo el sentido del mundo y estaría alineado con todas las decisiones que tomaron durante el verano pasado, ¿no?
Cursor abandonó a los ingenieros y power users. Su target no necesita un GPT-5 High.
Tried Cursor's new model... feels even more trigger-happy than Sonnet? Had a bug where linter would show some vars as unused (even tho they are clearly used) and it immediately deleted them all.
Codex takes 10x longer but is like "wait a minute if they are they they might be needed. *reads all files* *finds issue* wires them back in *
It is insanly fast tho. Maybe for smaller projects where vibin' is fine?


¿Por qué le han llamado Composer?
¿No era Composer uno de los "modos" que tenía Cursor inicialmente? Si no recuerdo mal era "Chat", "Composer" y "Agent".
¿Por qué llamar ahora así a su modelo?

Cheetah was a older version, Composer is much smarter!
cursor.com/blog/composer
> Todos somos QA y Product Managers ahora, for the pursuit of moving faster.
Es cierto.
Y es curioso ver como esa frase suena a situación idílica para algunos devs, y el mismísimo infierno para otros.
Qué suerte ser de los primeros.
CC/Sonnet vs Codex/GPT-5. Tema muy matizable y con aristas pero los esenciales diría que son estos:
GPT-5 High es MUY superior a Sonnet 4.5 en cuanto a calidad del código, y decisiones de arquitectura y diseño. Llega muchísimo más allá. En cuestiones realmente complejas Sonnet es incapaz y GPT-5 lo maneja sobradamente.
Sin embargo Sonnet 4.5 es más steerable, y es más fácil de conversar y trabajar con él iterativamente. Salvo excepciones, lo que escribe Sonnet es más legible. Es muchísimo (pero muchísimo) más rápido. Usa mejor la búsqueda, los MCPs... cualquiera tarea de recabación de datos fuera de la codebase. Todo ello en conjunto hace que explorar e iterar sea muchísimo más fácil y eficiente con Sonnet.
Entonces hay que usar las fortalezas de ambos.
Un resumen de mi uso típico podría ser:
Codex hace el scouting de la codebase MUY bien, lo mapea todo, y hace unos diseños de arquitectura excepcionales. Tras eso normalmente produce una implementación preliminar súper sólida que establece una fundación genial para trabajar sobre ella.
Pero entonces es cuando llega la necesidad de iteración, y ahí es donde entra mi caballo de batalla principal (CC/Sonnet).
Luego vuelvo a usar a GPT-5 Medium / Low cuando hay que hacer bonita la UI :)


Muchísima gente ha sido engañada con el CLAUDE(.)md, Agents(.)md, Cursor Rules etc, y ahora es fuente de frustración.
Todas esas cosas tienen un impacto MÍNIMO.
Sirven más como archivo para persistir una pequeña librería de prompts que cualquier otra cosa.
A los LLMs hay que REPETIRLES las cosas constantemente. Sí, casi en cada mensaje. Es así como funcionan, no hay atajos.
Puedes reducirte la fricción de copiar y pegar las instrucciones, pero vas a tener que hacerlo activamente y selectivamente.
La movida es que hacerlo paga. Aunque puedo entender que a mucha gente le resulte tedioso o aburrido.