May 27, 2025 · 4:55 PM UTC
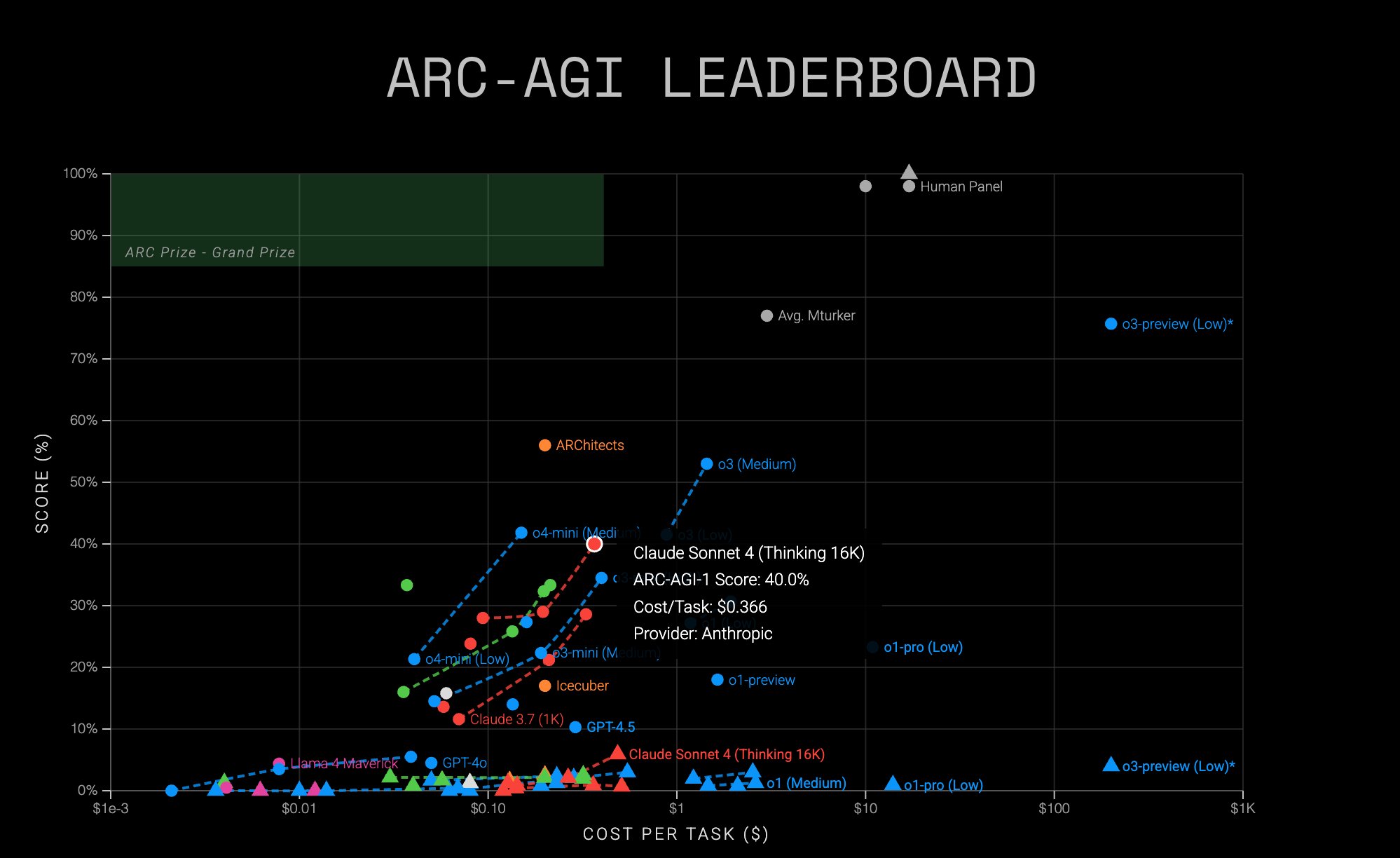
Testing baseline LLMs performance across various models - arcprize/arc-agi-benchmarking