

Principal Engineer at @NVIDIA working on programming languages. @adspthepodcast co-host. C++ Library Evolution chair emeritus. Frequent flyer. Horology fan.
Manhattan, NY
Joined March 2011
- Tweets 11,813
- Following 2,515
- Followers 16,859
- Likes 1,109
Pinned Tweet

The latest revision of @INCITS/@isostandards COBOL comes out this year
The goals of COBOL sound normal today:
- Portable
- Freely available
- Designed by the community
In 1959 it was radical & unprecedented
It was also conceived of & led by women
This is the story of COBOL


Bryce Adelstein Lelbach retweeted

📢 Episode 259 is out! 📢 In this episode, @blelbach and @code_report record live from NDC TechTown in Norway 🇳🇴! We interview Vittorio Romeo and @jfbastien about C++, training, their talks and more! adspthepodcast.com/2025/11/0…




Why is @TripIt email processing still so bad? How is this not just an LLM? I bet you could handle 95% of unknown formats this way.




This is one of the most aggravating "features" of GPT-5 - it won't launch a deep research task without asking some clarifying question first, even if you explained everything in your initial prompt.

Bryce Adelstein Lelbach retweeted
📢 Episode 258 is out! 📢 In this episode, @blelbach and @code_report record live from Norway the day before NDC TechTown! Bryce explains a taxonomy of algorithms: serial, parallel and cooperative! 🥳 adspthepodcast.com/2025/10/3…

Bryce Adelstein Lelbach retweeted
📢 Episode 257 is out! 📢 In this episode, @blelbach and @code_report record live from Norway 🇳🇴! They continue their chat about the replicate, scatter, gather and run length decode algorithms! They recap their train troubles 🚂 as well! adspthepodcast.com/2025/10/2…

Bryce Adelstein Lelbach retweeted

Now anyone can pre-train your own model in 4 hours. Incredible work by @karpathy to open source and democratize some of the most important educational resources in the AI Era. The “Eurekas Per Second” in nanochat is something you must experience.
The NVIDIA Brev team has created a launchable (see below) for you to try!
Simply click “Deploy Launchable” and a GPU will be provisioned in the cloud, and nanochat will begin training!
The first 10 developers to deploy will be able to train their own GPT 2 style model completely for free. Happy hacking!


Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.

This will go down as one of the great episodes in ADSP lore. I did in fact crack the one pass algorithm but Conor hasn't seen it yet

📢 Episode 256 is out! 📢 In this episode, @blelbach and @code_report record live from the streets of Copenhagen 🇩🇰! They talk about the algorithms replicate, scatter, gather and run length decode while navigating bugs 🐛, clubs 🍾 and rain 🌧️! adspthepodcast.com/2025/10/1…

Bryce Adelstein Lelbach retweeted
📢 Episode 256 is out! 📢 In this episode, @blelbach and @code_report record live from the streets of Copenhagen 🇩🇰! They talk about the algorithms replicate, scatter, gather and run length decode while navigating bugs 🐛, clubs 🍾 and rain 🌧️! adspthepodcast.com/2025/10/1…
Bryce Adelstein Lelbach retweeted

🟢 GEFORCE DAY IS BACK 🟢
To celebrate, we're giving away TWO GeForce RTX 5080 Founders Edition GPUs, signed by NVIDIA CEO Jensen Huang.
Want one? Comment "GeForce Day" for a chance to WIN & stay tuned for more!

Bryce Adelstein Lelbach retweeted
📢 Episode 255 is out! 📢 In this episode, @blelbach and @code_report record live from the streets of Copenhagen 🇩🇰! They recap the C++ Copenhagen Meetup hosted by Symbion, the replicate algorithm and much more! adspthepodcast.com/2025/10/1…




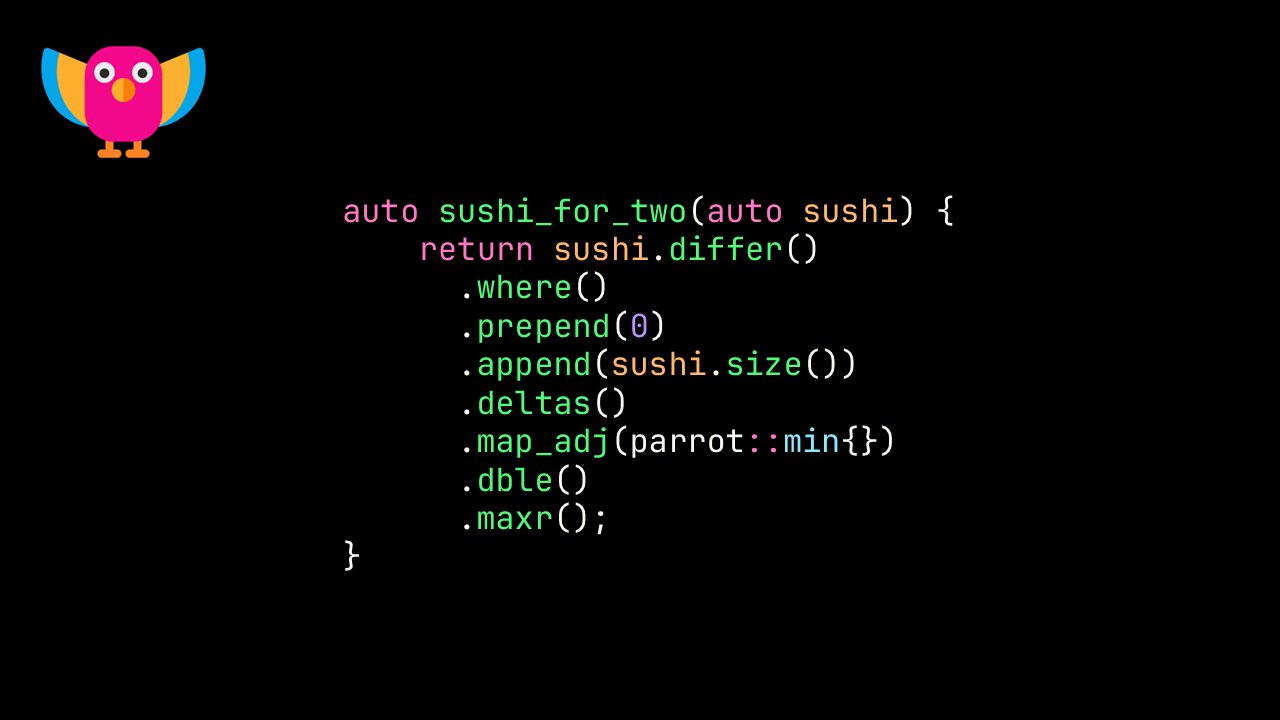
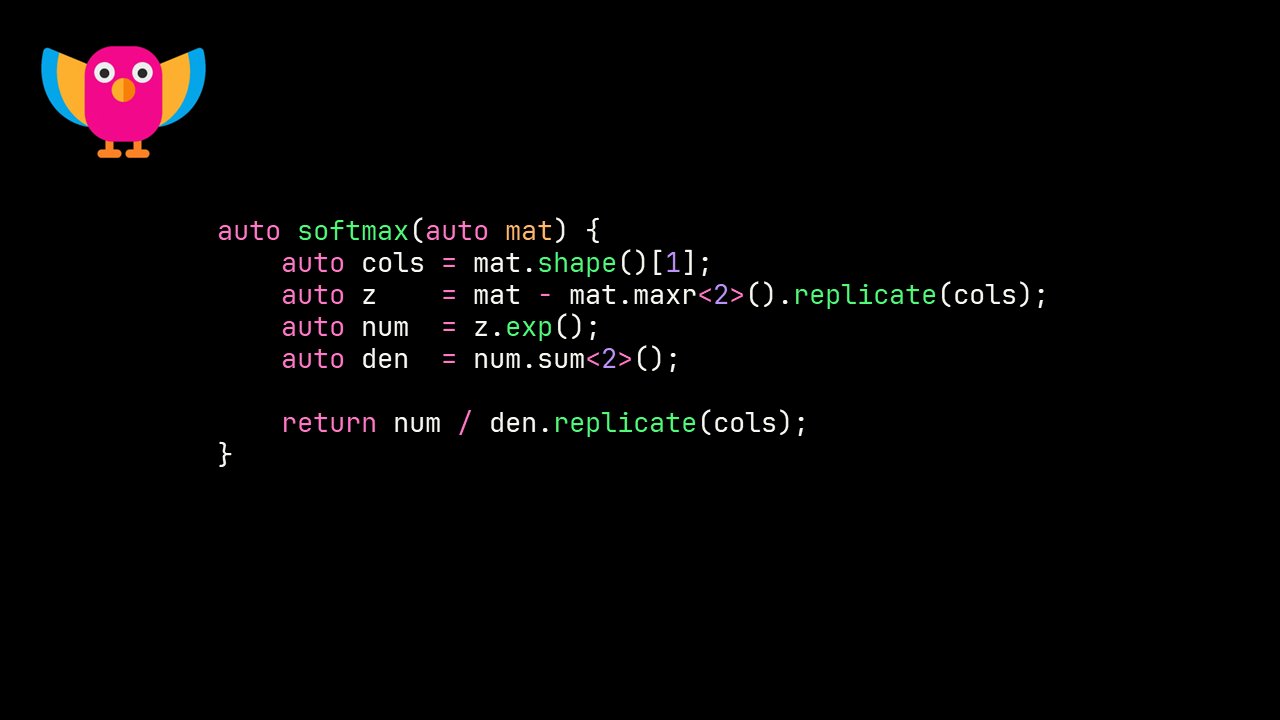
.@code_report's Parrot, a C++ parallel array-based library with implicit fusion using CUDA/Thrust, was launched today at @cppunderthesea!
It's the culmination of 3 years of work by Conor.
This is the best way to write GPU-accelerated algorithms in C++!
github.com/nvlabs/parrot


Bryce Adelstein Lelbach retweeted

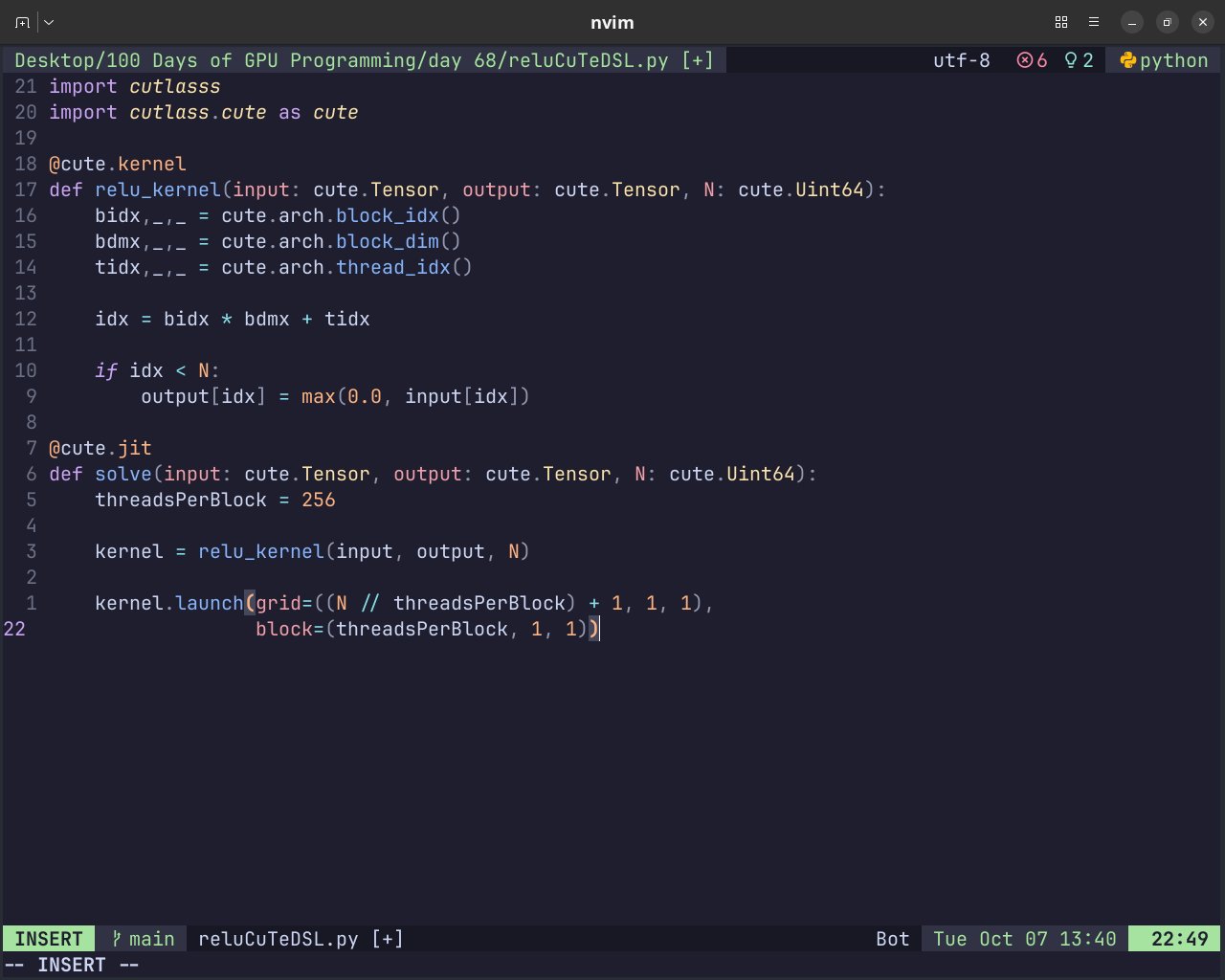
day 68/100 of GPU Programming
- learnt how to write a relu kernel in cute dsl
- slightly tweaked my fast cuda reverse array kernel and making it 7.84x faster on the B200(0.13842 ms to 0.01765 ms), similar improvements seen on the T4, A100, H200 and H100





.@code_report said I didn't get enough @adspthepodcast stickers last time, so...
Come get some at @cppunderthesea next week! We will both be there.
