
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] arxiv.org/abs/2508.09123
📌 [Website] opencua.xlang.ai/
🤖 [Models] huggingface.co/xlangai/OpenC…
📊[Data] huggingface.co/datasets/xlan…
💻 [Code] github.com/xlang-ai/OpenCUA
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
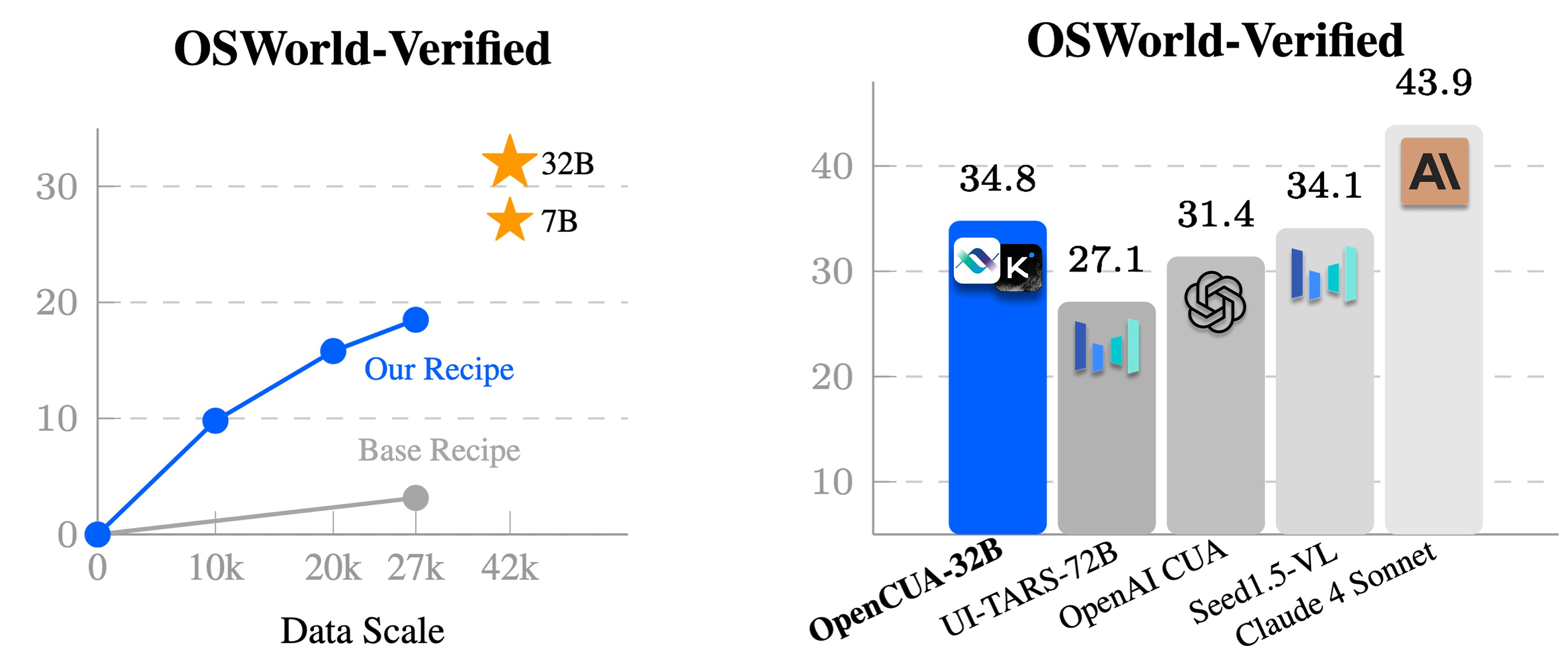
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
Aug 15, 2025 · 4:59 PM UTC
AgentNet Tool 🖥— a computer-use task annotation application for Windows/macOS/Ubuntu, capturing screen videos, mouse/keyboard events, and metadata for scalable real-world computer-use data. It can automatically record the task without interrupting the user workflow.

AgentNet dataset 📂— 22,625 human-annotated computer-use tasks spanning Windows, macOS, and Ubuntu, covering 140+ apps & 190+ websites, with multi-app workflows, professional tools, and uncommon features, and an average trajectory length of 18.6.

Data modeling 💡: Incorporates a reflective long CoT — a novel pipeline that enriches each task step with reflection, planning, and memory. The generator and reflector iteratively produce and verify reasoning between the observation and ground-truth actions, enhancing the model’s ability to perceive and recover from errors.

OpenCUA models 🚀: OpenCUA-7B and OpenCUA-32B are strong open-source foundation models for computer use. In particular, OpenCUA-32B achieves 55.3% on Screenspot-Pro and 34.8% on OSWorld-Verified (SOTA among open-source models)👇


AgentNetBench 🏁— stable, fast, environment-free offline benchmark with 100 diverse representative tasks, covering Windows and macOS platforms and diverse domains. Each task is manually provided with multiple valid action options at each step.

Insight 1: OpenCUA offers a scalable solution to strong computer-use foundation models, with AgentNet contributing 22K tasks to the open-source community. The performance ceiling of SFT-based CUAs is still far from reached.

Insight 2: Same-domain (computer system) training delivers the largest gains in that environment. Cross-domain transfer shows a performance gap but is still beneficial.

Insight 3: Huge gap exists between Pass@1 and Pass@16 performance on OSWorld using OpenCUA-Qwen2-7B. Surprisingly, Pass@3 performance boosts OpenCUA-32B from 34.2% → 45.6%! 📈 This large margin suggests ample headroom for future post-training, reranking, or multi-agent methods.

🙌 Thanks to all the authors — @xywang626 , @BowenWangNLP , @DunjieLu1219 , @junlin45300 , @TianbaoX , @JunliWang2021 , @jiaqideng07 , @gxlvera , @yihengxu_ , @ChenHenryWu , @ZShen0521 , Zhuokai Li, @RyanLi0802 , @xiaochuanlee , Junda Chen, Boyuan Zheng, Peihang Li, @fangyu_lei , @RuishengC49326 , Yeqiao Fu, @dcshin718, Martin Shin, Jiarui Hu, Yuyan Wang, @chenjx210734 , Yuxiao Ye, @_zdy023 , @dikang_du, @Mouse_Hu, Huarong Chen, Zaida Zhou, Haotian Yao, Ziwei Chen, Qizheng Gu, Yipu Wang, @HengWang_xjtu, @Diyi_Yang , @hllo_wrld, @RotekSong, Y. Charles, Zhilin Yang, and @taoyds .
🙌 Acknowledgement: We thank @ysu_nlp, @CaimingXiong , and the anonymous reviewers for their insightful discussions and valuable feedback. We are grateful to Moonshot AI for providing training infrastructure and annotated data. We also sincerely appreciate Jin Zhang, Hao Yang, Zhengtao Wang, and Yanxu Chen from the Kimi Team for their strong infrastructure support and helpful guidance. The development of our tool is based on the open-source projects DuckTrack @arankomatsuzaki and @OpenAdaptAI we are very grateful for their commitment to the open-source community.
Finally, we extend our deepest thanks to all annotators for their tremendous effort and contributions to this project. ❤️










