

Undergraduate @HKUniversity | Research Assistant @XlangNLP | Intern @Kimi_Moonshot
Joined April 2025
- Tweets 15
- Following 54
- Followers 27
- Likes 14
Jiaqi Deng retweeted

Big update for OpenCUA! OpenCUA-72B-preview now ranks #1 on the OSWorld-Verified leaderboard (os-world.github.io/). It is a pure GUI action, end-to-end computer-use foundation model (Website: opencua.xlang.ai/).
Huge thanks to the effort of OpenCUA team and the great support of Kimi Team @Kimi_Moonshot !
Claude 4.5 is extremely strong on OSWorld, but we’re committed to pushing open-source, end-to-end CUA foundation models forward. Over the last month we trained a larger, stronger model: 45.0% average on OSWorld-Verified.
It also shows strong GUI grounding ability: 37.3% on UI-Vision @EdwardJian2 @PShravannayak and 60.8% on ScreenSpot-Pro.
We’ll keep driving open-source CUA: models will be on HuggingFace very soon, and a paper update is on the way.
#OpenSource #Agents #OSWorld #CUA #ComputerUseAgent


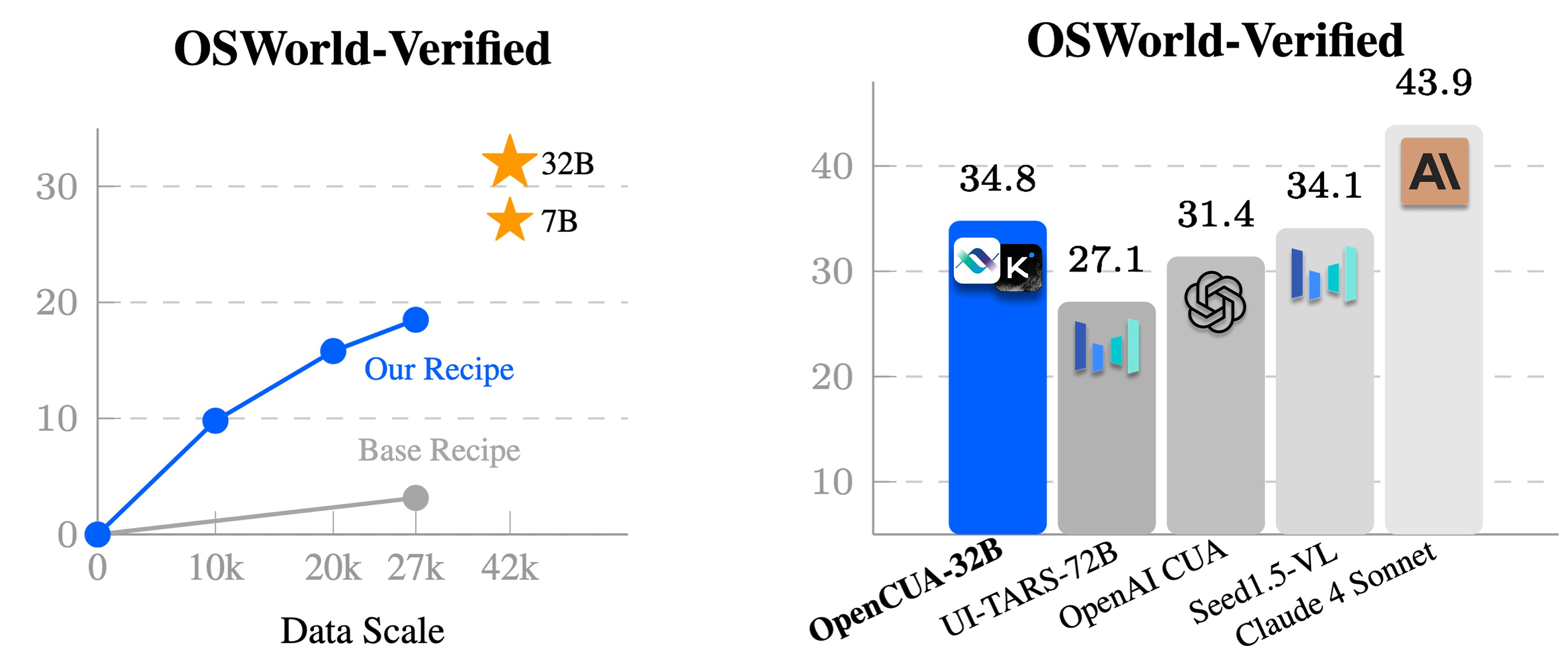
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] arxiv.org/abs/2508.09123
📌 [Website] opencua.xlang.ai/
🤖 [Models] huggingface.co/xlangai/OpenC…
📊[Data] huggingface.co/datasets/xlan…
💻 [Code] github.com/xlang-ai/OpenCUA
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
Jiaqi Deng retweeted
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data.
🔗 [Paper] arxiv.org/abs/2508.09123
📌 [Website] opencua.xlang.ai/
🤖 [Models] huggingface.co/xlangai/OpenC…
📊[Data] huggingface.co/datasets/xlan…
💻 [Code] github.com/xlang-ai/OpenCUA
🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including:
📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories)
🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA)
🖥 AgentNetTool — cross-system computer-use task annotation tool
🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation
💡 Why OpenCUA?
Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding.
Details of OpenCUA framework👇
Jiaqi Deng retweeted

Where are our computer‑use agents (CUA) standing on OSWorld‑Verified? Potentially already ~80%.
We made this analysis, which summarizes the latest OSWorld-Verified submissions with 27 models evaluated over 369 tasks, and conducted a case study on the o3+Jedi-7B approach to explore current model capability boundaries and identify key bottlenecks in computer-use agent performance.
Overall Insights:
- Together We're There: The 80% Breakthrough: Collectively, 27 models solve 78.86% of OSWorld tasks—no single model comes close, but together they crack nearly 80%. This reveals massive potential for ensemble approaches and RL systems that can learn from diverse model behaviors.
- Alone We Struggle: The Reality Check: But here's the truth behind the 80% headline—only 11.92% of tasks achieve near-perfect performance across models, while 39.30% remain consistently difficult. We're not at 80% capability; we're at a distributed struggle across difficulty levels. Most tasks remain genuinely hard for current models, with only about 1 in 8 tasks showing strong, consistent performance.
- Planning Problems: The Critical Bottleneck: While state-of-the-art models have significantly improved general tool-use (decision) quality, their understanding of GUI concepts, knowledge, and related decision-making remains limited. Enhanced GUI interaction experience would help address these capability gaps. Planner limitations—including failure to understand the current state and getting stuck in loops—represent the critical bottleneck we urgently need to address.
- Grounding Gaps: Fine-Grained and Long-tail Failures Matter: Current open-source grounding models demonstrate satisfying performance on common patterns such as text and common icons, but still occasionally fail on uncommon icons and fine-grained operations involving text selection and tables. Besides weakness we already know, failures also often occur in unexpected places—sometimes repeatedly failing to click a checkbox, sometimes missing an unfamiliar icon—and these seemingly minor errors can often determine whether a task succeeds or fails entirely.

Jiaqi Deng retweeted

Wow, this is really cool! This reserach answers this question: what if your computer-use AI was not a black box?
OpenCUA: Open Foundations for Computer-Use Agents
Researchers from HKU, Moonshot AI, and others present OpenCUA—a fully open-source framework for building and scaling computer-use agents (CUAs). It includes:
- An annotation tool for capturing human computer-use demos
- AgentNet, the first large-scale dataset covering 3 OSes & 200+ apps/sites
- A pipeline that turns demos into state–action pairs with long Chain-of-Thought reasoning
The flagship model OpenCUA-32B hits 34.8% success on OSWorld-Verified—setting a new open-source SOTA and even surpassing GPT-4o in this benchmark.
Code, data, and models are all public—paving the way for transparent CUA research.


Great work from @TianbaoX. Keep building!

🚀 OSWorld gets a major upgrade!
OSWorld-Verified: 15 months community feedback → 300+ fixes (ambiguity, graders…), 50x faster eval through AWS parallelization
More apple-to-apple comparison for reliable CUA evaluation ✨
👇xlang.ai/blog/osworld-verifi…
Jiaqi Deng retweeted

🚀 Hello, Kimi K2! Open-Source Agentic Model!
🔹 1T total / 32B active MoE model
🔹 SOTA on SWE Bench Verified, Tau2 & AceBench among open models
🔹Strong in coding and agentic tasks
🐤 Multimodal & thought-mode not supported for now
With Kimi K2, advanced agentic intelligence is more open and accessible than ever. We can't wait to see what you build!
🔌 API is here: platform.moonshot.ai
- $0.15 / million input tokens (cache hit)
- $0.60 / million input tokens (cache miss)
- $2.50 / million output tokens
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai
🔗 Github: github.com/MoonshotAI/Kimi-K…
Try it now at Kimi.ai or via API!

Jiaqi Deng retweeted

🔥New Computer Agent Arena Leaderboard Updates (2k+ user votes)!
🤔Which VLMs act better as computer use agents (CUAs)?
1, Claude Sonnet 4 🥇
2, Claude 3.7 Sonnet 🥈
3, UI-TARS-1.5 🥉
4, Operator
More insights in the thread 👇
arena.xlang.ai

Jiaqi Deng retweeted

Graphical user interface (GUI) grounding, one of the two key abilities (Grounding & Planning) for Computer-use Agent (e.g. Operator) that map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer-use agent development.
🔥🔥🔥Excited to introduce "Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis"!
🔍 Key Research Results:
-Grounding Boosts Agents: Improved grounding with Jedi lifts general foundation models' (GPT-4o) success on complex OSWorld tasks from 5% to 27%!
-Compositional Generalization: We found combining specialized data for different UI elements enables generalization to novel interfaces.
✨ Key Highlights:
-OSWorld-G Benchmark: 564 finely annotated samples testing the perspectives that were once oversighted such as text matching, element recognition, layout understanding, and precise manipulation.
-Jedi Data Pipelines and Dataset: We showcased several meticulously constructed data synthesis pipelines and synthesized the largest computer use grounding dataset to date with 4 million examples, synthesized through UI decomposition and synthesis. The industry can further invest and scale upon this.
-Multi-Scale Models: Our novel 3B and 7B models trained on Jedi achieve SOTA on ScreenSpot-v2, ScreenSpot-Pro, & OSWorld-G.
📄 Paper: bit.ly/4jfUsgB
💻 New Benchmark/Dataset/Models: bit.ly/4mukYpa
🎮Demo: bit.ly/3Sk3v4Z

Jiaqi Deng retweeted
💠Claude Opus 4 & Claude Sonnet 4
Welcome to the Computer Agent Arena🔥
Congratulations on the @AnthropicAI team for the great release!

Jiaqi Deng retweeted

Congrats @TianbaoX and team on this exciting work and release! 🎉 We’re happy to share that Jedi-7B performs on par with UI-Tars-72B agent on our challenging UI-Vision benchmark, with 10x fewer parameters! 👏 Incredible
🤗Dataset: huggingface.co/datasets/Serv…
🌐uivision.github.io/




Jiaqi Deng retweeted
🎉 UI-TARS-1.5 is now live on Computer Agent Arena!
Currently the SOTA model across multiple GUI benchmarks, showcasing leading performance in computer use, browser use, and even gameplay.
Want to try the most intelligent CUA so far? Go to arena.xlang.ai.


Introducing UI-TARS-1.5, a vision-language model that beats OpenAI Operator and Claude 3.7 on GUI Agent and Game Agent tasks.
We've open-sourced a small-size version model for research purposes, more details can be found in our blog.
TARS learns solely from a screen, but generalizes beyond a screen!
Blog: seed-tars.com/1.5
Model: github.com/bytedance/UI-TARS
App: github.com/bytedance/UI-TARS…

Jiaqi Deng retweeted
🚀 Meet Kimi-VL and Kimi-VL-Thinking! 🌟 Our latest open source lightweight yet powerful Vision-Language Model with reasoning capability.
✨ Key Highlights:
💡 An MoE VLM and an MoE Reasoning VLM with only ~3B activated parameters
🧠 Strong multimodal reasoning (36.8% on MathVision, on par with 10x larger models) and agent skills (34.5% on ScreenSpot-Pro)
🖼️ Handles high-res visuals natively with MoonViT (867 on OCRBench)
🧾 Supports long context windows up to 128K (35.1% on MMLongBench-Doc, 64.5% on LongVideoBench)
🏆 Outperforms larger models like GPT-4o on key benchmarks
📜 Paper: github.com/MoonshotAI/Kimi-V…
🤗 Huggingface: huggingface.co/collections/m…
🌱 While this release marks just one small step, we're excited to see how the community builds upon it.




Jiaqi Deng retweeted

🎮 Computer Use Agent Arena is LIVE! 🚀
🔥 Easiest way to test computer-use agents in the wild without any setup
🌟 Compare top VLMs: OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 vl and more
🕹️ Test agents on 100+ real apps & webs with one-click config
🔒 Safe & free access on cloud-hosted machines
Page: arena.xlang.ai
Leaderboard (tentative): arena.xlang.ai/leaderboard
Blog: arena.xlang.ai/blog/computer…
Data & Code (coming soon): github.com/xlang-ai/computer…
⭐️Why Computer Agent Arena?
1️⃣Beyond Static Benchmarks: We use computers to perform enormous tasks and workflows every day, and AI agents have the potential to automate these tasks. However, existing benchmarks are very limited (e.g., only 369 tasks in OSWorld and 812 tasks in WebArena). To better measure their capabilities, we introduce Computer Agent Arena for users to easily compare & test AI agents on all kinds of crowdsourced real-world computer use tasks.
2️⃣Cloud Testing, Simplified: As agents like OpenAI’s Operator and Claude 3.7 sonnet release, users face configuration challenges and privacy hurdles to deploy on their own computers. Our platform integrates these agents with cloud-hosted machines, providing users with quick and secure access.
3️⃣Unified Embodied Digital Environment: Unlike Chatbot Arena, we provide users with a real embodied environment—computers—where all agents are grounded in real computer tasks and environments.
Led by @XLANG_Lab [1/🧵]
