













invest in good design.
buy objects that make you pause.
every well-designed thing carries compressed intelligence; geometry, ergonomics, philosophy, material science; all distilled into form.
a good chair teaches balance.
a good pen teaches flow.
a good interface teaches empathy.
the more you surround yourself with great design, the sharper your design sense becomes; until you start seeing structure and beauty everywhere.






Wuggyan retweeted

Anthropic 是在将 agent 从Claude Code 推广到 business 应用时发现这个问题的
实际上对于我们一直深耕商业场景(营销,销售、客服)的厂商来说,这几乎是第一个发现:控制面和数据面要分离 ,特别是数据面要在 LLM context 之外实现
实践中有许多做法,写一个决定性的逻辑意味着控制面里只有工具参数是模型要做的决策,数据面完全可以大规模简化。 用写代码完成任务等于用图灵机的纸带完成数据面,控制面只要写出图灵机的操作程序。
目前我们探索的一些折衷方案是给一些数据面的 schema, 外加 markdown. 其实走来走去 可能又回到了一些都是 CRM 物件这种领域特定的抽象。

这篇总结也很好:
x.com/omarsar0/status/198609…
Anthropic 又发布了一篇神级指南。
这次的主题是:如何构建更高效的 AI 智能体 (AI Agent),让它们能更聪明地使用工具,并且极大地节省 Token 。
如果你是 AI 开发者,这篇文章绝对不容错过!
它主要解决了 AI 智能体在调用工具时遇到的三大难题:Token 成本、延迟 (latency) 和工具组合的效率。
怎么做到的?简单来说,它把“代码执行”和“模型编写的代码” (MCP, Model-Written Code) 结合了起来。它不再让 AI 智能体直接去“调用工具”,而是把这些工具“伪装”成代码 API,让 AI 智能体像程序员一样通过写代码来使用它们。
以下是这篇指南的核心干货:
1. Token 效率的“黑洞”:想象一下,如果 AI 智能体一上来就把所有可能用到的工具定义全塞进大脑(上下文窗口 (context window)),并且在执行任务时,每一步的中间结果都塞回去。这样会导致 Token 开销大到爆炸,一个复杂的多工具任务跑下来,有时会超过 15 万个 Token。
2. “代码即 API” 策略:新方法是,不直接调用工具,而是把这些“模型编写的代码” (MCP) 工具包打包成代码 API(比如 TypeScript 模块)。AI 智能体可以像程序员一样“导入” (import) 并通过编程来调用它们。效果立竿见影:一个 15 万 Token 的任务,瞬间被压缩到了 2000 个 Token,节省了 98.7%!
3. 工具的“渐进式发现”:不再一股脑加载所有工具。AI 智能体学会了“按需取用”,通过搜索文件系统或调用 search_tools(搜索工具)函数,只在需要时才加载当前任务相关的工具定义。这完美解决了“上下文臃肿” (context rot) 和 Token 过载的问题。
4. “数据本地处理”:在把结果喂给大语言模型 (LLM) 之前,先在代码执行环境里把数据处理好(比如筛选、转换、汇总)。举个例子:AI 智能体不需要查看 1 万行的表格,代码环境会先帮它筛选出那 5 行最重要的,再交给它。
5. 更优的控制流 (Control Flow):与其让 AI 智能体一步步地“指挥”工具(比如“做完A,再做B”),不如直接用代码原生的循环 (loops)、条件判断 (conditionals) 和错误处理来管理流程。这样做,既减少了延迟,也省了 Token。
6. 隐私保护:敏感数据可以在整个工作流中传递,而完全不进入大模型的“视野”(上下文)。只有那些被明确指定“返回”或“记录”的值才会被模型看到,还可以选择自动对个人身份信息 (PII) 进行脱敏。
7. 状态持久化 (State Persistence):AI 智能体可以把中间结果存成文件,“断点续传”。这样一来,它们就能处理那些需要跑很久的“大任务”,并且能跟踪进度。
8. 可复用的“技能包”:AI 智能体可以把写好的有效代码保存成“可复用函数”(并配上 SKILL .MD 文档),久而久之,它就能积累出一个强大的高级“技能库”。
这种方法虽然更复杂,也还不完美,但它绝对能全面提升你构建的 AI 智能体的效率和准确性。



我在MIT看到的Agent 新范式
今天在麻省理工学院的EmTech大会上,看到了一个让我重新思考整个AI agent领域的演示。
演示方是TinyFish,一家相当低调的公司。创始团队里有两位华人,获得了ICONIQ领投的近3.5亿元人民币融资,但在今天之前从未公开展示过他们的核心产品。
而他们正在做的事情,已经在为Google和DoorDash运行超过千万级别的web agent操作...
不是实验室demo,是真实的生产环境。
TinyFish产品能让 AI 能够像人类一样自动操作网页、完成企业级任务...
它可以在没有 API 的情况下,让 AI 自动跨网站读取、理解、操作网页,执行业务流程、采集数据、提交信息、监控变化。
从抓数据、比价格、做填表、查库存,到合规审查与动态定价,都能完成...
可以在几千个网站间实时操作、执行任务。
也就是可以以同时运行一千个ChatGPT Atlas ,然后不间断的,同样的答案运行一千万次...
一个被所有人忽视的事实
TinyFish的CEO Sudheesh在演示中分享了一个震撼的洞察:
现在市面上所有的AI agent,都只能操作5%的网络。
不是因为开发者技术不行,而是因为所有人都在基于搜索引擎构建agent。
而搜索这个范式,早就失效了。
搜索是怎么失效的?
我们来看一个最简单的例子:Amazon。
Amazon的每个产品页面都被Google完整索引,完全可以爬取。这是搜索引擎最理想的场景。
但当你在Amazon搜索"笔记本电脑"时会发生什么?
你会看到上万个结果。赞助商品、虚假评论、AI生成的描述铺天盖地。你翻了几页就放弃了,最后随便点一个"看起来还行"的,结账走人。
这不是Amazon的问题。这是搜索范式本身的问题:当数据量太大时,排名就失效了。
Google成功地索引了数百万Amazon页面,但这并没有让搜索变得更有用。Amazon自己建了搜索引擎,也没有解决问题。
网络变得太大了。即使是已经被索引的那部分,排名也已经无法工作。
搜索假设你想"找到"某样东西。但如果你需要"检查所有"东西呢?比较所有供应商?验证每一个选项?**
这时候,整个范式就崩溃了。
那剩下的95%呢?
更糟糕的是,刚才说的还只是那5%被索引的网络。
剩下95%的网络藏在哪里?
- 需要登录的供应商门户
- 有身份验证的医疗系统
- 只能通过表单提交访问的政府数据库
- 需要多步骤导航的竞争情报
搜索引擎根本接触不到这些。不是技术问题,是架构问题。你无法爬取需要交互才能访问的内容。
所以我们面临两个问题:
1. 被索引的5%网络因为太大而失效
2. 95%的重要数据根本没被索引
两个问题的根源都一样:搜索这个范式假设人类会手动评估结果。当你需要全面的情报而不是排名选项时,它就失效了。
为什么现有方案都解决不了
你可能会想:RAG呢?更好的embedding呢?Browser agents 呢?
它们都解决不了
因为它们都继承了搜索的核心局限:假设你想"找到"某样东西,而不是"检查所有"东西。
当一个采购团队需要检查200个供应商门户的竞争定价时,排名帮不了你。
当制药公司需要在数千个研究站点匹配临床试验的患者资格时,检索帮不了你。
这不是"这项工作很繁琐我们想自动化"的问题。这是"这种分析在我们需要的规模上根本不可能完成"的问题。
从可读Web到可执行Web
Sudheesh解释了他们的解决方案:
不是更好的搜索,而是操作性基础设施。
TinyFish构建的系统可以:
- 登录认证系统
- 导航多步骤工作流
- 提取结构化数据
- 同时运行数十万个并行会话
这就是从"可读Web"到"可执行Web"的转变。
浏览器代理(比如OpenAI的Atlas)帮助个人更快地导航网站:一次一个会话,一个浏览器。
TinyFish 的 Mino:
👉 就像一个“AI工厂”,让公司自己创建、部署和管理这些“网页机器人(Web Agents)”。
Mino可在基础设施规模上运行数十万个并行会话,在需要人类团队数周时间完成的复杂工作流中保持准确性。
这不是自行车和摩托车的区别。这是自行车和货运网络的区别。
规模化的证明
这不是理论
TinyFish已经在为ClassPass、Google、DoorDash等公司每月运行3000万次操作。
ClassPass的例子很典型:他们需要聚合数万家健身工作室的课程。大部分工作室没有API,只有手动更新的预订网站。课程安排每天变化,价格因时间、地点和等级而异。
传统方法全部失败:
- 人工录入:无法规模化,数据永远过时
- 爬虫:网站一改版就崩溃
- API对接:长尾永远不会开发集成
使用TinyFish后,他们的场馆覆盖率增加了3-4倍,成本降低了50%。
更具体的实际落地案例:
🏨 Google Hotels
日本许多酒店使用老旧系统,无法接入 Google 聚合平台
TinyFish 的代理能自动获取这些酒店的库存与价格;
无需 IT 改造,让 Google Hotels 实现实时更新。
实现 99% 的实时覆盖率
更新频率提升 20 倍
运行量超过 每月 1,000 万+ 操作
🛵 DoorDash
为每个城市部署 AI 代理,自动抓取竞争网站菜单、价格、促销
每小时更新、自动去重与异常检测;
与 DoorDash 内部数据系统自动对接。
每月收集数百万个定价变量;
用于动态调整价格、优化市场响应;
自动化 95% 市场数据采集;
提高预测模型精度 30%;
大幅降低人工调研成本(原来每月人工工时 1200+ 小时)。
这意味着什么
搜索在过去25年里运行得很好,因为网络足够小,人类可以手动评估排名结果。
现在网络太大了。即使是被索引的部分也变得无法管理。而95%的网络从来没被索引过。
接下来的范式不是更好的搜索或更智能的排名。而是能够在整个网络上导航、推理和提取的操作性基础设施:公开的和私密的,被索引的和未被索引的。
Agent功能的发展速度远超预期。短短36个月,我们就从"AI起草邮件"发展到了"AI运行完整工作流"。
TinyFish可能在企业规模的实际落地上已经领先了。
他们正在向开发者开放这个基础设施。如果你在构建需要大规模可靠性的agent产品,这可能是一个值得关注的早期信号。


Anthropic官方给出的【如何通过代码执行+MCP,来构建更高效的AI智能体】,把token消耗从15万降到了2千,时间/费用节省98%
随着连接工具的增多,直接工具调用方式导致的Token消耗过高、智能体效率降低问题
核心思想,把MCP服务器视为代码API,非直接的工具调用,让智能体编写代码来与MCP服务器交互
来增强智能体上下文效率、降低成本、减少延迟,也可以增强智能体处理复杂任务的能力,同时兼顾隐私
工具发现机制,把MCP工具组织成文件系统结构,比如,servers/google-drive/getDocument.ts,智能体可以通过探索文件系统来按需发现和加载所需的工具定义,无需一次性加载所有工具
代码编排,智能体不再直接调用工具,而是生成一段代码比如TypeScript,这段代码会调用封装好的函数来与MCP工具交互,比如说,将“从Google Drive下载会议记录并附加到Salesforce线索”的任务,转化为一段包含 gdrive.getDocument() 和 salesforce.updateRecord() 调用的代码
隐私保护上,中间结果默认保留在执行环境中,只有明确记录或返回的数据才会进入模型的上下文
对于敏感数据,比如个人身份信息 PII,MCP客户端可以在数据到达模型之前对其进行脱敏,并在需要时再进行反脱敏,确保敏感信息永远不会直接暴露给模型
#MCP #AIagent


New on the Anthropic Engineering blog: tips on how to build more efficient agents that handle more tools while using fewer tokens.
Code execution with the Model Context Protocol (MCP): anthropic.com/engineering/co…




Wuggyan retweeted

很多朋友留言说,怎么同一个提示词,效果差那么多?
如果你是用Nano Banana, 想要精准控图,就必须要用JSON prompt。(MJ相反,提示词过于复杂并不好)
关于人物“美不美”,这是一个很主观的标准,如果你通过"beautiful","stunning"等形容词来描述,其实不一定有效果
所以尝试给模型一些客观参考,比如让她的五官参考迪丽热巴、杨幂等等明星,效果会要好一些
P1为没有样貌参考,其它为有样貌参考
就用这张真实感拉满的图为例,外貌可以自己微调,咒语如下(包出的):
{
"scene": {
"description": "Young, attractive woman pausing mid-hike in a misty mountain forest, sweat beading on her skin.",
"environment": "Cloud forest with light fog; soft greenery and mossy rocks disappearing into haze.",
"mood": "Fresh, natural, energetic and charming."
},
"output": {
"aspect_ratio": "2:3 vertical EXACT",
"target_resolution": "3072x4608",
"safe_margins": "6–8% inner padding"
},
"aesthetic": {
"style": "Naturalistic outdoor portrait (DSLR look).",
"look": "Cool-neutral palette; gentle filmic contrast; realistic wet-skin highlights; fog-softened background."
},
"lighting": {
"description": "Overcast sky as giant softbox; key from high-front camera-left with wrap; very light fill from camera-right; micro-speculars on cheekbones, nose bridge and collarbone.",
"exposure": "Preserve highlight detail on moist skin; background ~0.7 stop darker for separation."
},
"subject": {
"demographics": {
"age": "18–25",
"gender": "female",
"ethnicity": "East Asian",
"beauty": "Youthful, healthy glow; balanced symmetry; refined features."
},
"appearance": {
"hair": "High ponytail; light, piecey bangs over the forehead that are ONLY slightly damp; a few wispy strands touch the cheek; slight humidity frizz.",
"skin": "Natural pores with peach-fuzz; visible sweat beads on face/shoulders/clavicle; subtle rosy cheeks.",
"makeup": "Minimal—hydrated base, soft lip tint, groomed brows.",
"likeness_guidance": "Facial character INSPIRED BY Dilraba Dilmurat (迪丽热巴) and Yang Mi (杨幂)—large bright almond eyes with long lashes, defined straight brows, refined high nasal bridge with gentle tip, heart/oval face with soft jawline, fuller natural lips—DO NOT exactly replicate any specific person."
},
"wardrobe": {
"top": "Graphite-grey sports bra with knit micro-texture and wide straps."
},
"accessories": {
"gear": "Subtle backpack strap or translucent rain shell edge along subject's left side.",
"jewelry": "None."
},
"pose": {
"type": "Chest-up close portrait (bust).",
"framing": "Crop just above navel; both shoulders in frame; head near upper third; negative space to the left for fog.",
"body_orientation": "Torso turned 15–20° toward camera-left; right shoulder slightly closer and lower by ~2–3 cm.",
"head_orientation": "Head turned 20° toward camera-left; tilt (roll) −3°.",
"gaze": "Eyes looking off-camera toward upper-left; relaxed expression.",
"mouth": "Lips relaxed, slightly parted.",
"hands": "Not visible."
}
},
"camera_lock": {
"camera_height": "Upper-chest (sternum), ~10–12 cm below chin.",
"camera_distance": "0.8–1.0 m from subject.",
"camera_angle": "Yaw 0°, pitch −2°, roll 0°.",
"lens": "50mm equivalent (acceptable 45–60mm).",
"depth_of_field": "f/2.8 look—eyes/lashes/hair strands sharp; background softly blurred."
},
"props_in_scene": {
"background": "Soft bokeh foliage and fog; no signage or text.",
"materials": "Moist skin, gently damp bangs, woven athletic fabric, fine fog particles."
},
"camera_technical": {
"requirements": "True facial proportions; crisp eyelashes and individual hair strands; readable sweat beads; no text/watermarks or AI glyphs.",
"capture": "ISO 200–640; 1/250 s; WB 5300–5600 K; EXACT 2:3 vertical."
},
"retouching": {
"notes": "Preserve pores, droplets and wispy bangs; remove only transient blemishes; avoid plastic smoothing.",
"grade": "Subtle cool-neutral grade; gentle S-curve; minimal vignette."
},
"avoid": [
"Over-wet bangs (must be only slightly damp)",
"Harsh flash or clipped highlights",
"Aged/tired look—must remain youthful and pretty",
"Pose/angle drift from locks",
"Text/logos/watermarks",
"Over-smoothing that erases texture"
]
}





#前女友来了
真人感无敌的一张,仔细看细节
咒语:
A natural grab shot of an alluring day-style woman hiking in the mountains, ponytail with bangs, flushed cheeks from exertion, in a sports bra top and leggings, pausing to look at the view, misty background with slight fog, captured mid-step for dynamic feel.

Wuggyan retweeted

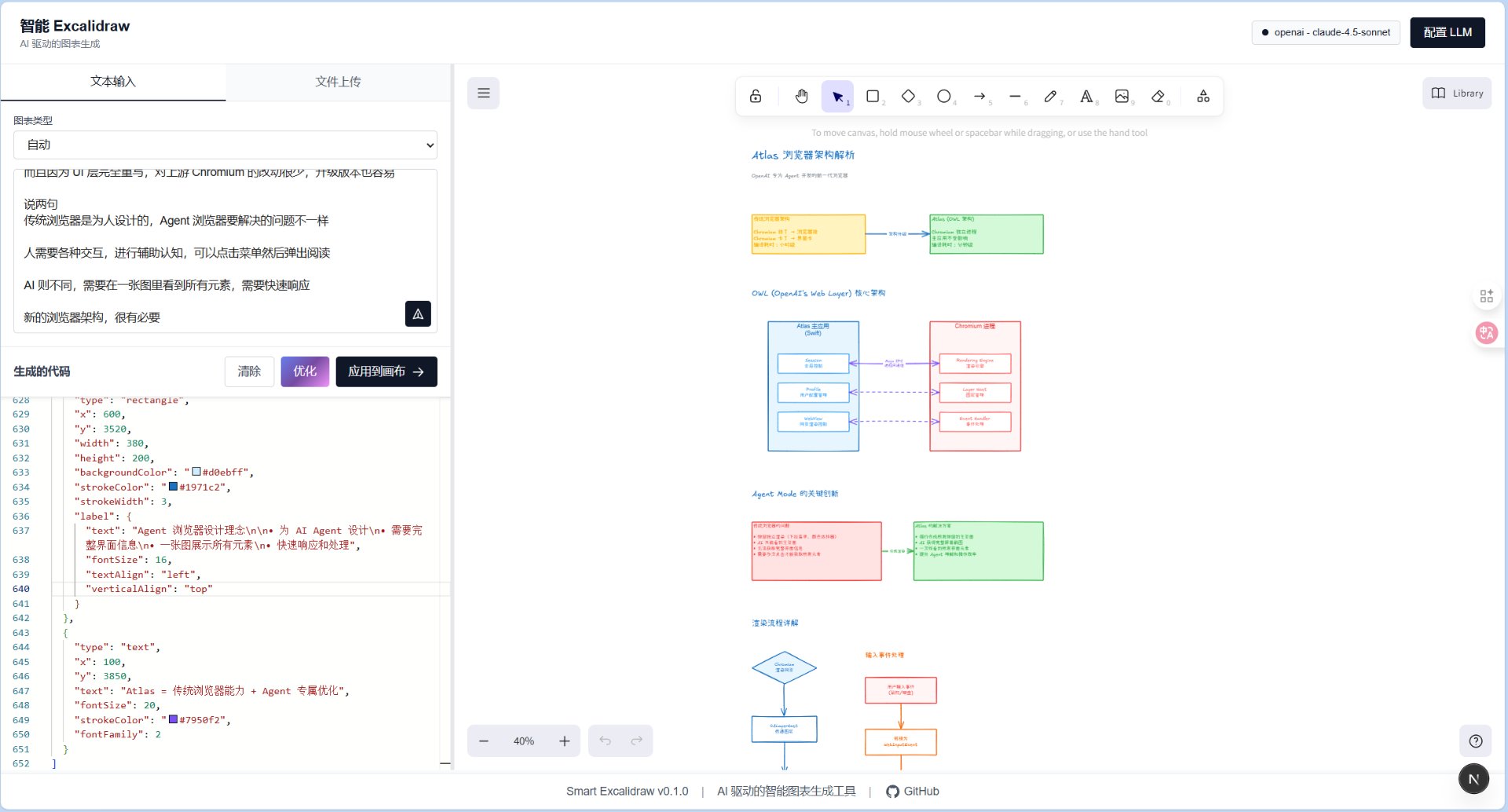
在写技术文档或梳理业务逻辑时,为了让大家更好地直观了解项目,通常会画各种流程图、架构图,但颇为耗时。
这时候,找到了 Smart Excalidraw 这款开源工具,允许我们用自然语言就能快速生成专业级、结构清晰的图表。
通过智能箭头优化算法,确保连线不交叉、布局不错乱,支持流程图、架构图、时序图、思维导图等 20 多种类型图表。
GitHub:github.com/liujuntao123/smar…
除此之外,还集成了 Excalidraw,在图表生成后可自由编辑样式和细节,所有数据保存在本地浏览器,隐私安全。
提供了在线演示网站,只需配置一个 AI API 密钥即可开始使用,建议用 Claude Sonnet 4.5 模型,也可以本地部署运行。








Wuggyan retweeted

How to get Claude code output top-tier UI?
👇 This is my 3-step process to turn Claude code into design mode

Wuggyan retweeted

WTF🤯 This is insane!
I just found a website that lets you create unlimited cool gradient videos for free.


