

Joined July 2013
- Tweets 4,497
- Following 107
- Followers 1,556
- Likes 2,973

Cerebras code powered by open source GLM model


Interesting trend on strong competing alternatives to NVIDIA

Jensen is getting desperate. China is shutting off a major src of demand for Nvidia chips, transshipment to Chinese SOE DCs.
I have pretty solid src that just 6000 out of 100k racks in Meta's Hyperion DC will be Nvidia cards. Google TPUs are supplying most of its future demand.
Same w/ Amazon & Trainium.
I've said this many times now. The absolute compute per card should not be overvalued. You can achieve same w/ compute w/ more lower cost cards & get better performance through more memory + faster interconnect.
On top of that, US data build out is facing logjam due to energy & supply chain issues. You can check the lead time on diesel generators & gas turbine. I overstated optical transceiver issues since the big time has hit supply chain constraint b4 we even got there.
Jensen knows Nvidia is facing an upcoming cliff.
Altman sees the same issue. Hence all the begging for govt help.
At end of the day, Chinese AI labs have shown you can do leading models w/o having unlimited compute, so why do we need to keep proclaiming build out speed that's not achievable?

Interesting GEO opportunities

The Most Cited Websites by AI Models (citation frequency):
1. reddit - 40.1%
2. wikipedia - 26.3%
3. youtube - 23.5%
4. google - 23.3%
5. yelp - 21.0%
6. facebook - 20.0%
7. amazon - 18.7%
8. tripadvisor - 12.5%
9. mapbox - 11.3%
10. openstreetmap - 11.3%
11. instagram - 10.9%
12. mapquest - 9.8%
13. walmart - 9.3%
14. ebay - 7.7%
15. linkedin - 5.9%
16. quora - 4.6%
17. homedepot - 4.6%
18. yahoo - 4.4%
19. target - 4.3%
20. pinterest - 4.2%
Source: Semrush, as of June 2025.
Interesting perspective on the weight tensors of LLMs

LLMs memorize a lot of training data, but memorization is poorly understood.
Where does it live inside models? How is it stored? How much is it involved in different tasks?
@jack_merullo_ & @srihita_raju's new paper examines all of these questions using loss curvature! (1/7)

Continual learning via nested optimisation

Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI
@GoogleAI

SOTA for Kimi K2 Thinking - not just open source SOTA

MoonshotAI has released Kimi K2 Thinking, a new reasoning variant of Kimi K2 that achieves #1 in the Tau2 Bench Telecom agentic benchmark and is potentially the new leading open weights model
Kimi K2 Thinking is one of the largest open weights models ever, at 1T total parameters with 32B active. K2 Thinking is the first reasoning model release within @Kimi_Moonshot's Kimi K2 model family, following non-reasoning Kimi K2 Instruct models released previously in July and September 2025.
Key takeaways:
➤ Strong performance on agentic tasks: Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
➤ Reasoning variant of Kimi K2 Instruct: The model, as per its naming, is a reasoning variant of Kimi K2 Instruct. The model has the same architecture and same number of parameters (though different precision) as Kimi K2 Instruct and like K2 Instruct only supports text as an input (and output) modality
➤ 1T parameters but INT4 instead of FP8: Unlike Moonshot’s prior Kimi K2 Instruct releases that used FP8 precision, this model has been released natively in INT4 precision. Moonshot used quantization aware training in the post-training phase to achieve this. The impact of this is that K2 Thinking is only ~594GB, compared to just over 1TB for K2 Instruct and K2 Instruct 0905 - which translates into efficiency gains for inference and training. A potential reason for INT4 is that pre-Blackwell NVIDIA GPUs do not have support for FP4, making INT4 more suitable for achieving efficiency gains on earlier hardware.
Our full set of Artificial Analysis Intelligence Index benchmarks are in progress and we will provide an update as soon as they are complete.

Autonomous agent for data science
DS-STAR is a state-of-the-art data science agent designed to autonomously solve complex data science problems. It automates tasks from analysis to data wrangling across diverse data types to achieve top performance on challenging benchmarks. Learn more:
goo.gle/3WHBMNS

SOTA DS Agent
DS-STAR is a state-of-the-art data science agent designed to autonomously solve complex data science problems. It automates tasks from analysis to data wrangling across diverse data types to achieve top performance on challenging benchmarks. Learn more:
goo.gle/3WHBMNS
Learning lesson on IP bandwidth bottleneck

Fixed the token generation speed on platform.moonshot.ai & OpenRouter!
Shocking plot twist: The bottleneck was IP bandwidth, NOT GPU count 😱 We threw compute at the problem. The answer was thicker pipes, not more cards.
Lesson: When serving LLMs, check your network limits before your GPU count 🔥
New Kimi model
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai

Kimi K2 thinking model release
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai
Good to know my bills will keep going down

LLM token prices are collapsing fast, and the collapse is steepest at the top end.
The least "intelligent" models get about 9× cheaper per year, mid-tier models drop about 40× per year, and the most capable models fall about 900× per year.
Was same with "Moore’s Law, the best contemporary example of Jevons paradox. This extraordinary collapse in computing costs – a billionfold improvement – did not lead to modest, proportional increases in computer use. It triggered an explosion of applications that would have been unthinkable at earlier price points. "
---
a16z .substack.com/p/why-ac-is-cheap-but-ac-repair-is

KV cache communication over natural language for agents talking to one another
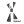
Wow, language models can talk without words.
A new framework, Cache-to-Cache (C2C), lets multiple LLMs communicate directly through their KV-caches instead of text, transferring deep semantics without token-by-token generation.
It fuses cache representations via a neural projector and gating mechanism for efficient inter-model exchange.
The payoff: up to 10% higher accuracy, 3–5% gains over text-based communication, and 2× faster responses.
Cache-to-Cache: Direct Semantic Communication Between Large Language Models
Code: github.com/thu-nics/C2C
Project: github.com/thu-nics
Paper: arxiv.org/abs/2510.03215
Our report: mp.weixin.qq.com/s/tjDq99VrE…
📬 #PapersAccepted by Jiqizhixin

Agents to agents talking to one another through KV cache instead of text
Wow, language models can talk without words.
A new framework, Cache-to-Cache (C2C), lets multiple LLMs communicate directly through their KV-caches instead of text, transferring deep semantics without token-by-token generation.
It fuses cache representations via a neural projector and gating mechanism for efficient inter-model exchange.
The payoff: up to 10% higher accuracy, 3–5% gains over text-based communication, and 2× faster responses.
Cache-to-Cache: Direct Semantic Communication Between Large Language Models
Code: github.com/thu-nics/C2C
Project: github.com/thu-nics
Paper: arxiv.org/abs/2510.03215
Our report: mp.weixin.qq.com/s/tjDq99VrE…
📬 #PapersAccepted by Jiqizhixin
Interesting, no need for dedicated azure landing zone just for openai if you’re on AWS

New multi-year, strategic partnership with @OpenAI will provide our industry-leading infrastructure for them to run and scale ChatGPT inference, training, and agentic AI workloads.
Allows OpenAI to leverage our unusual experience running large-scale AI infrastructure securely, reliably, and at scale.
OpenAI will start using AWS’s infrastructure immediately and we expect to have all of the capacity deployed before end of next year-- with the ability to expand in 2027 and beyond. aboutamazon.com/news/aws/aws…

Interesting relationship between language and programming aptitude

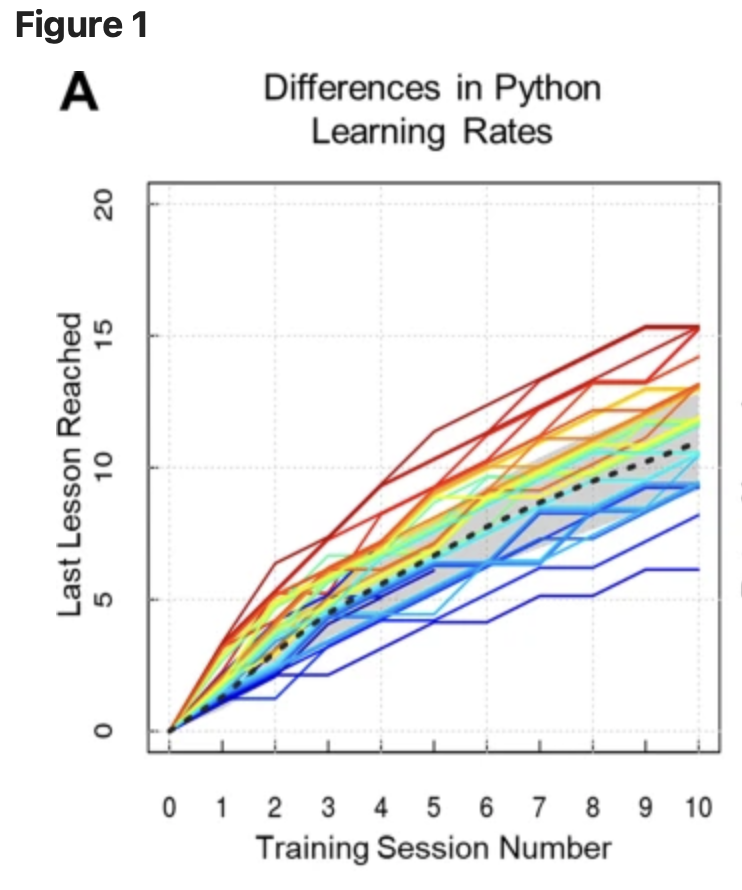



New low latency MMLM

🔥 LongCat-Flash-Omni: Multimodal + Low-Latency
🏆 Leading Performance among Open-Source Omni-modal Models
☎️ Real-time Spoken Interaction: Millisecond-level E2E latency
🕒 128K context + Supports > 8min real-time AV interaction
🎥 Multimodal I/O: Arbitrary Combination of Text/Image/Audio/Video Input → Text/Speech Output (w/ LongCat-Audio-Codec)
⚙ ScMoE architecture on LongCat-Flash: 560B Parameters, 27B Active
🧠 Training: Novel Early-Fusion Omni-modal training paradigm -> No Single Modality Left Behind
🚀 Efficient Infrastructure: With optimized modality-decoupled parallel training, Omni sustains >90% throughput of text-only training efficiency
🤗 Model open-sourced:
【Hugging Face】huggingface.co/meituan-longc…
【GitHub】github.com/meituan-longcat/L…
📱 LongCat APP is here—available for both iOS and Android! Scan the QR code to quickly try its awesome voice interaction features!
💻For the PC experience, you can click on LongCat.AI for a free trial!
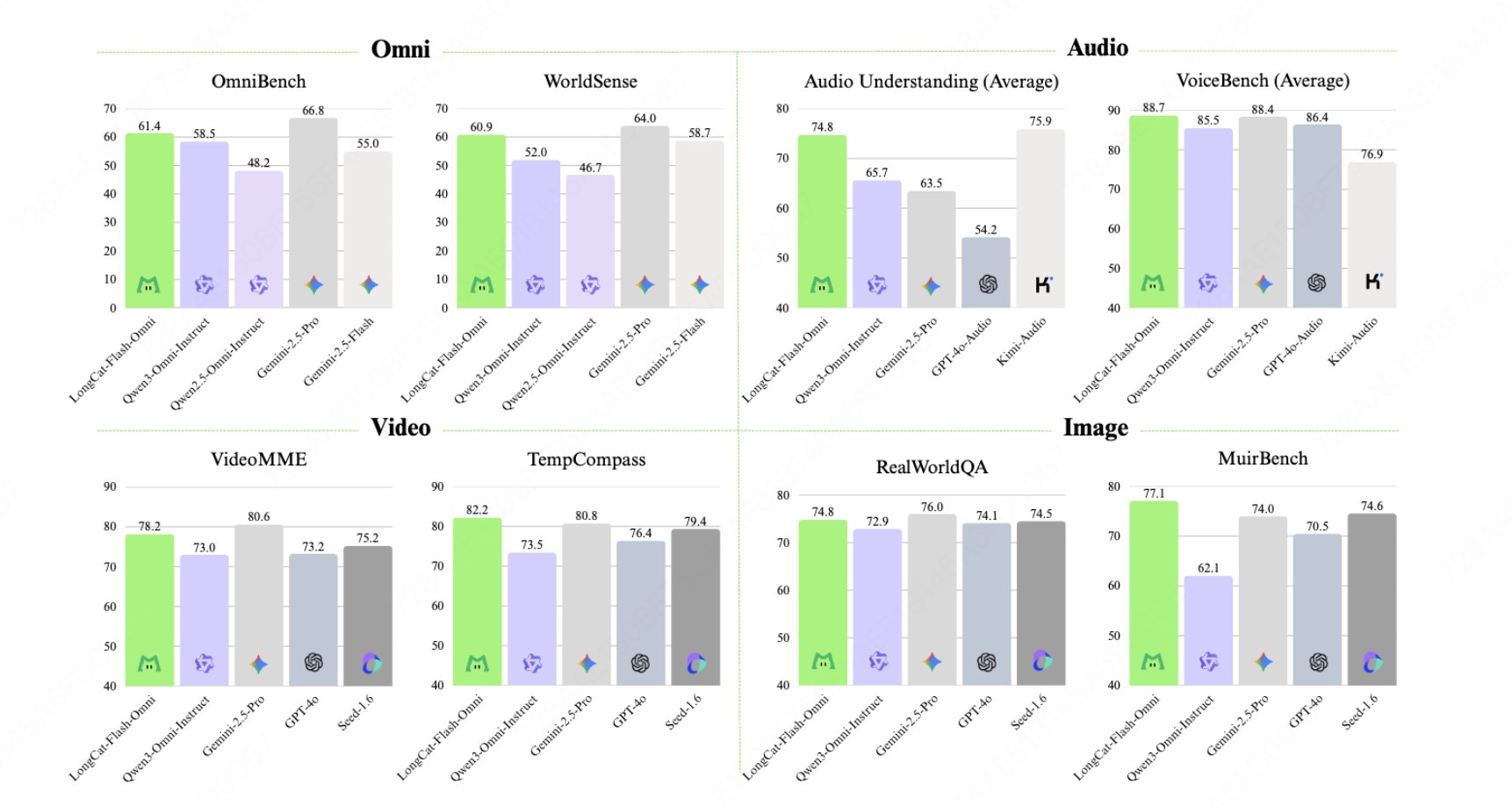

New open source MMLM by a food delivery company - pretty good
🔥 LongCat-Flash-Omni: Multimodal + Low-Latency
🏆 Leading Performance among Open-Source Omni-modal Models
☎️ Real-time Spoken Interaction: Millisecond-level E2E latency
🕒 128K context + Supports > 8min real-time AV interaction
🎥 Multimodal I/O: Arbitrary Combination of Text/Image/Audio/Video Input → Text/Speech Output (w/ LongCat-Audio-Codec)
⚙ ScMoE architecture on LongCat-Flash: 560B Parameters, 27B Active
🧠 Training: Novel Early-Fusion Omni-modal training paradigm -> No Single Modality Left Behind
🚀 Efficient Infrastructure: With optimized modality-decoupled parallel training, Omni sustains >90% throughput of text-only training efficiency
🤗 Model open-sourced:
【Hugging Face】huggingface.co/meituan-longc…
【GitHub】github.com/meituan-longcat/L…
📱 LongCat APP is here—available for both iOS and Android! Scan the QR code to quickly try its awesome voice interaction features!
💻For the PC experience, you can click on LongCat.AI for a free trial!

