

Joined October 2014
- Tweets 27,734
- Following 379
- Followers 166
- Likes 66,992
Toni Migliato🇧🇷🇮🇹 retweeted

0% de IA utilizado
100% um cara apaixonado pelo produto que estava criando 🤝
Toni Migliato🇧🇷🇮🇹 retweeted

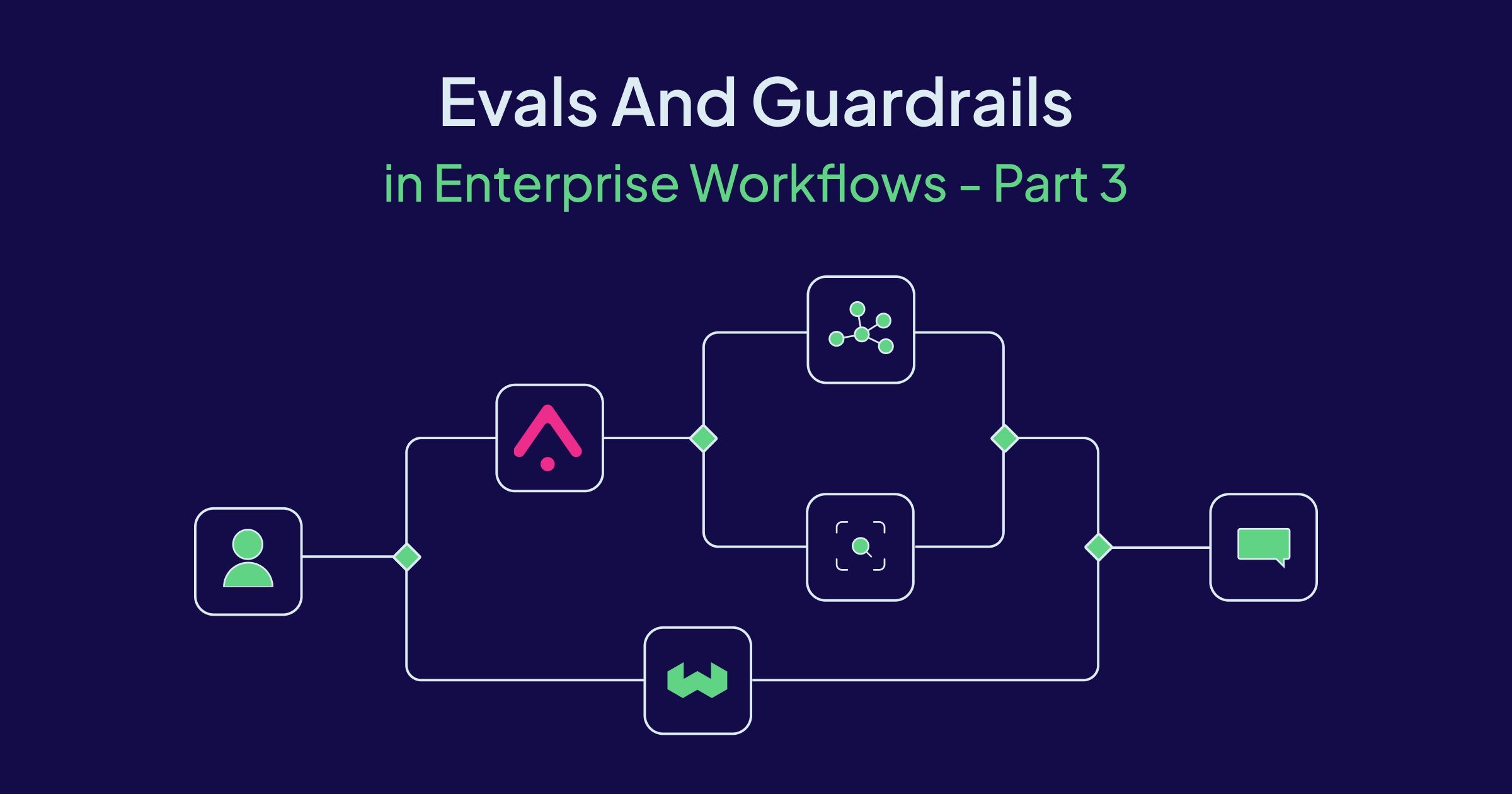
𝗦𝗲𝗹𝗳-𝗰𝗼𝗿𝗿𝗲𝗰𝘁𝗶𝗻𝗴 𝗥𝗔𝗚 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝗮𝗿𝗲 𝘁𝗵𝗲 𝗳𝘂𝘁𝘂𝗿𝗲.
Here's how to build one that automatically detects and fixes hallucinations:
Part 3 of our Enterprise AI series explores behavior shaping: a pattern where your RAG system automatically catches hallucinations, generates corrective feedback, and retries with an improved prompt before the response reaches users.
The post includes a complete implementation using 𝗪𝗲𝗮𝘃𝗶𝗮𝘁𝗲 for RAG and @arizeai for evaluation, with working code you can run today.
Learn how to build self-correcting AI systems that adapt to errors instead of just logging them.
Read the full post: weaviate.io/blog/evals-enter…
Toni Migliato🇧🇷🇮🇹 retweeted

Computer Science is not science, and it's not about computers. Got reminded about this gem from MIT the other day

Toni Migliato🇧🇷🇮🇹 retweeted

Postman's latest Guidebook on building AI-ready APIs is one of the most important documents you can read today as a developer!
We are headed into an era where every website must be "Agent-ready".
- Agents will make purchases, not humans.
- Agents will find the best options, not humans.
- Agents will fill out job applications, not humans.
The same applies to APIs.
89% of devs use AI daily, but shockingly, only 24% design APIs with AI agents in mind.
Addressing this is crucial because while human devs can hustle through poor docs and broken endpoints, most Agents can’t.
They need:
- Predictable structures
- Machine-readable metadata
- Standardized behavior
The fix starts with machine-readable documentation that stays in sync with your schema.
Here's one idea I really like from @getpostman's AI-ready APIs playbook about automating the documentation generation process.
If a human dev faces issues with docs, they can search the web, open Stack Overflow, and more.
But Agents can’t use what they don’t even understand.
Thus, APIs must be well-documented so that Agents can easily learn everything about them and establish an entry point.
Otherwise, they will have no reliable way to discover what endpoints exist, what parameters to pass, what data to expect in return, or how to recover from an error.
Postman’s Agent Mode automatically generates detailed, contextual documentation for APIs based on your request/response examples and usage patterns.
This video showcases its usage to generate machine-readable documentation.
This makes it simple to turn any collection into interactive docs that are always up-to-date for Agents.
On a side note, Agent Mode can do a lot more. This is Postman’s AI-powered platform to explore, debug, and build APIs using natural language.
Also, there’s a lot more in the AI-ready APIs Playbook that I haven’t covered here, but the core takeaway stays the same: Agents using APIs should NOT be guessing.
Document everything in a way that both humans and machines can understand.
Because every time an agent has to infer how your API works, you introduce friction, inconsistency, and potential errors.
Postman makes it trivial to design → document → publish → monitor APIs that both humans and agents can use reliably.
I have shared the Playbook in the replies.
Thanks to Postman for partnering today!
Toni Migliato🇧🇷🇮🇹 retweeted

My lecture at MIT!✨
From Physics to Linear Algebra & Machine learning, I have learned a lot from MIT!
Yesterday, I had the honour of delivering a guest lecture on The state of AI Engineering, exploring:
- Prompt Engineering
- Retrieval Augmented Generation.
- Fine-Tuning Large Language Models.
- And, how LLMs are bringing a paradigm shift
Thank you @RoyShilkrot for the invitation! 🙏
Grateful for the opportunity to engage with such brilliant minds!
If you are interested AI Engineering, I write a free weekly newsletter → @ML_Spring

Toni Migliato🇧🇷🇮🇹 retweeted

Everyone's talking about agentic AI, but are we all talking about the same thing?
I've noticed people using "agentic architectures" and "agentic workflows" interchangeably.
But they're actually quite different concepts that work together.
Here's the distinction:
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝘄𝗼𝗿𝗸𝗳𝗹𝗼𝘄𝘀 = The series of steps an agent takes to achieve a goal
Think of it as the "what" - the actual process
These steps might include:
• Using LLMs to create a plan
• Breaking down tasks into subtasks
• Using tools like internet search
• Reflecting on outcomes and adjusting the plan
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀 = The technical framework and system design
Think of it as the "how" - the underlying structure
These always contain:
• At least one agent with decision-making capabilities
• Tools the agent can use
• Systems for short and long-term memory
Why does this matter?
Because the same workflow can be implemented using different architectures. It's like having multiple ways to build the same recipe - the steps remain similar, but the kitchen setup varies.
For example, an agentic RAG workflow (breaking down queries, retrieving information, evaluating relevance) could be built with a single-agent router architecture or a multi-agent system. Same workflow, different architecture.
Understanding this distinction helps you:
• Design more flexible systems
• Choose the right architecture for your specific workflow
• Communicate more clearly about what you're actually building
What agentic workflows are you most excited about implementing?
Resources:
📌 Agentic Architectures free Ebook: weaviate.io/ebooks/agentic-a…
📌 Agentic Workflows blog post: weaviate.io/ebooks/advanced-…


This is actually a very common problem with the architecture. Lack of coordination with the agents sometimes happens because of the orchestrator's understanding of how to use the subagents. It helps to be careful with the definitions/instructions for each subagent. Not too loose or too rigid usually works best. I suspect the sub-agents might be underspecified or might be compacting information in a suboptimal way (see brevity bias in the agentic context engineering paper). Another issue in that paper that's common with the orchestrator agent is "context collapse"; this actually happens a lot with this design, too. Better initial planning helps, too. Those are some issues that come to mind that might help. arxiv.org/abs/2510.04618


Toni Migliato🇧🇷🇮🇹 retweeted

I've just finished building the ultimate n8n automation library, and it’s a game-changer.
My team sifted through thousands of scattered workflows, cleaned the junk, and handpicked the best.
Now it's a fully organized vault of 1,500+ plug-and-play automations.
You’ll find:
- my most popular n8n builds (WhatsApp agent, scraper agent, TikTok VEO 3 automation, n8n assistant, and more)
- 1,500‑flow n8n template index (tagged by growth, ops, creative) so you never start from scratch
- full vibe‑coding tutorial where I go from basic n8n backend to Bolt front‑end UI in 23 min
Everything’s pre-tested and production-ready.
Want the link to the vault?
LIKE + RETWEET + COMMENT “YES” & I’ll send you the FULL workflow + setup FREE!

Toni Migliato🇧🇷🇮🇹 retweeted
Fine-tune 100+ LLMs directly from a UI!
LLaMA-Factory lets you train and fine-tune open-source LLMs and VLMs without writing any code.
Supports 100+ models, multimodal fine-tuning, PPO, DPO, experiment tracking, and much more!
100% open-source, 57k stars!
Toni Migliato🇧🇷🇮🇹 retweeted

Classic usecase of rate limiting, we apply rate limiting on our backend, either on the userId or on the IP address but because this is for login page the user isn’t logged in so we add it for IP address.
Enable captchas for accessing login page this will stop the bots from spamming our login endpoint.
If we have the data available of the breached accounts, maybe block the login attempts for those accounts and email the user to unblock login they can click on a link on email hence they’re now informed about the credentials leak and you also temporarily block out the requests for the leaked accounts.

A new n8n cheat sheet is out.
After the great response to the one we shared a couple of weeks ago, here’s another one from our community, this time from Philip Thomas.
It’s available in both German and English:
mastodon.social/@philipthoma…
If you’ve got resources, guides, or tutorials that could help the n8n community, send them our way.
Also curious - what kinds of resources or tutorials would you like to see more of? 👀


The absolutely disappointing result of GPT-5 has shown that the time to build the LLM is over.
It's time to start building *with* an LLM, which means we are back to machine learning:
- data selection/creation/labeling
- model architecture selection
- hyperparameter tuning
- prediction post-processing
- performance optimization
- data drift handling
Great times ahead. The tools available to a machine learning engineer have never been as good as they are today!
I really like the cross-LM workflow. For example, you use o3 to suggest fixes, and then you copy o3's proposed fix, paste it into Gemini, and ask for a full implementation.
Once implemented by Gemini, you show the updated code to o3 (and also any feedback from the runtime) and ask to criticize, propose further fixes, or confirm that all is good.
Each model, used in isolation, eventually falls into self-repetition. By this back and forth with two models, I feel like I'm less stuck in such self-repetition loops.
And Gemini codes so much faster than others!
Toni Migliato🇧🇷🇮🇹 retweeted

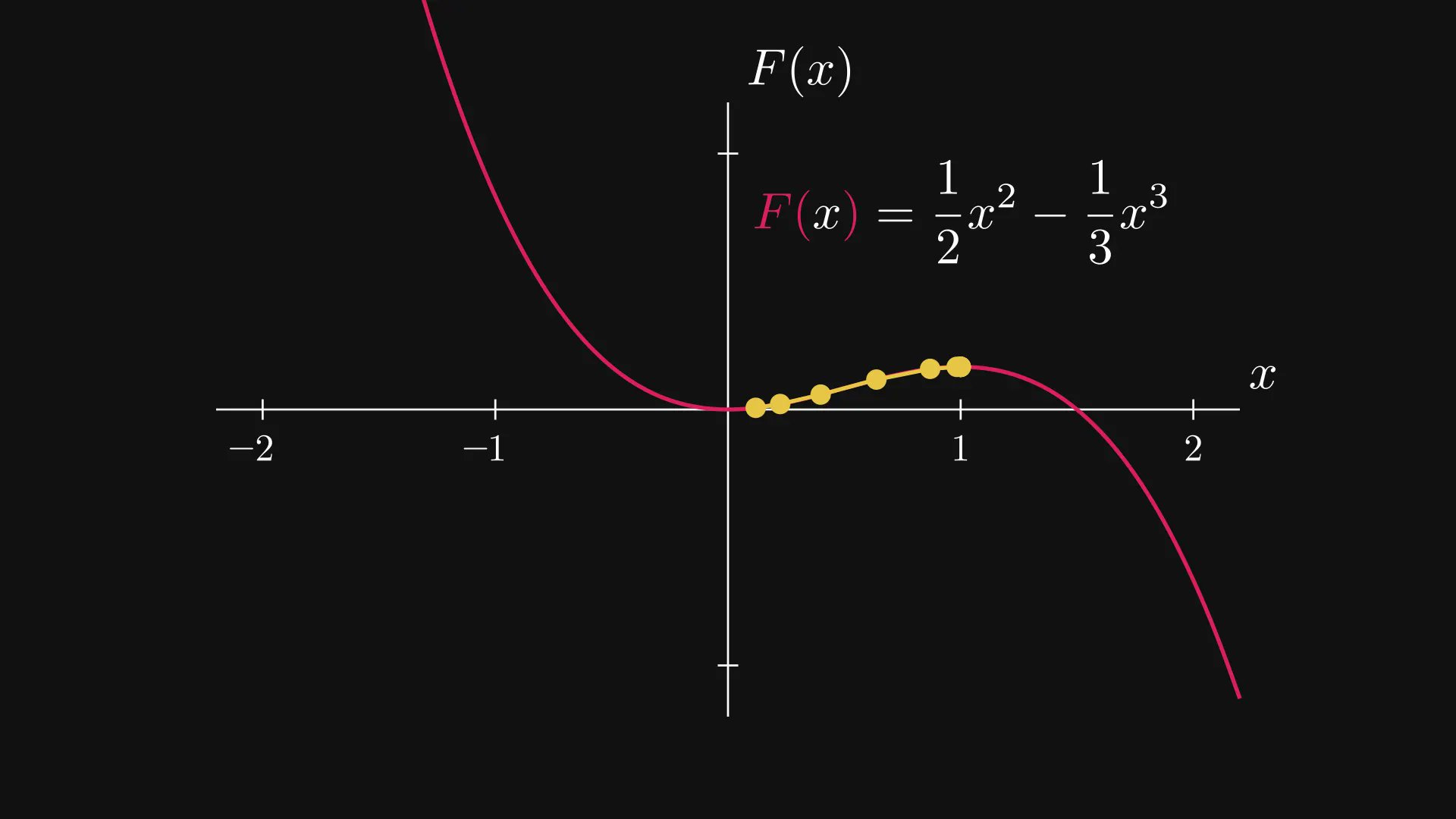
In machine learning, we take gradient descent for granted.
We rarely question why it works.
What's usually told is the mountain-climbing analogue: to find the valley, step towards the steepest descent.
But why does this work so well? Read on.
Toni Migliato🇧🇷🇮🇹 retweeted
The single most undervalued fact of linear algebra: matrices are graphs, and graphs are matrices.
Encoding matrices as graphs is a cheat code, making complex behavior simple to study.
Let me show you how!

Toni Migliato🇧🇷🇮🇹 retweeted

What makes a real app work?
1) Users can sign up, log in, log out (auth)
2) Data is saved safely (database)
3) People can pay you (payments)
4) Emails & notifications keep them engaged
5) The app is fast, looks good, works on any device (frontend)
6) Handles logic & tasks behind the scenes (backend)
7) Tracks usage to learn and improve (analytics)
8) Protected against hacks & errors (security)
This is the difference between a side project and a real business.
Toni Migliato🇧🇷🇮🇹 retweeted
All you need to launch a real product:
1. Auth (signup, login, logout)
2. Database (store user actions)
3. Payments (get paid)
4. Security (protect your data)
5. Frontend (UI/UX)
6. Backend (APIs and logic)
7. Notifications (email, push)
8. Analytics (track usage)
This is the groundwork. Don’t skip it.
