


Behrooz Azarkhalili retweeted

bro created an entire 16-hour free youtube playlist on how to build a DeepSeek model from scratch. it goes over the papers, explains the theory, and implements the code.
Syllabus:
→ attention mechanism fully explained
→ multi-head latent attention
→ grouped query attention
→ everything about positional encodings
→ mixture of experts (MoE)
just start today with a laptop and motivation.
playlist: piped.video/playlist?list=PL…

Behrooz Azarkhalili retweeted

i built a claude skill that lets claude code reverse-engineer itself
it uses mitmproxy to inspect system prompts and tool definitions, debug slash commands and sub-agents, and more
batteries included: guided setup, scripts, and AskUserQuestion tool for simplified usage


The most effective AI Agents are built on these core ideas.
It's what powers Claude Code.
It's referred to as the Claude Agent SDK Loop, which is an agent framework to build all kinds of AI agents.
(bookmark it)
The loop involves three steps:
Gathering Context: Use subagents (parallelize them for task efficiency when possible), compact/maintain context, and leverage agentic/semantic search for retrieving relevant context for the AI agent. Hybrid search approaches work really well for domains like agentic coding.
Taking Action: Leverage tools, prebuilt MCP servers, bash/scripts (Skills have made it a lot easier), and generate code to take action and retrieve important feedback/context for the AI agent. Turns out you can also enhance MCP and token usage through code execution and routing, similar to how LLM routing increases efficiency in AI Agents.
Verifying Output: You can define rules to verify outputs, enable visual feedback (this becomes increasingly important in multimodal problems), and consider LLM-as-a-Judge to verify quality based on fuzzy rules. Some problems will require visual cues and other forms of input to perform well. Don't overcomplicate the workflow (eg, use computer-using agents when a simple Skill with clever scripts will do).
This is a clean, flexible, and solid framework for how to build and work with AI agents in all kinds of domains.

Behrooz Azarkhalili retweeted

3. tinker-cookbook
Post-training with Tinker
#Python
github.com/thinking-machines…


Behrooz Azarkhalili retweeted

Add this skill in Claude Code today:
/plugin marketplace add browserbase/agent-browse
/plugin install browser-automation@browser-tools
github.com/browserbase/agent…


Behrooz Azarkhalili retweeted
mcps are changing
turns out designing mcps to load every tool definition into the model prompt was a bad idea
anthropic’s nov 4 blog post suggests a new pattern
treat each mcp server like a normal code library, e.g. typescript modules or files, and let the agent write and run small programs that do two things:
discover only what is needed, list a servers directory to see what exists, open just the specific tool files, import only those functions
process data locally, call mcp tools from code, then filter, join, and aggregate inside a sandboxed runner so only the small final bits go back to the model
doing this dramatically cuts tokens
anthropic shows a typical case dropping from 150k tokens down to ~2k (98.7% savings)
below a viz showing before/after

Behrooz Azarkhalili retweeted

THIS IS CRAZY....
I've been using Claude and its a monster when it comes to tasks automation and acting like a real assistant.
Here are 10 prompts I use in Claude to automate my boring tasks:
(Comment "Send" and I'll DM you an automation file too for free)


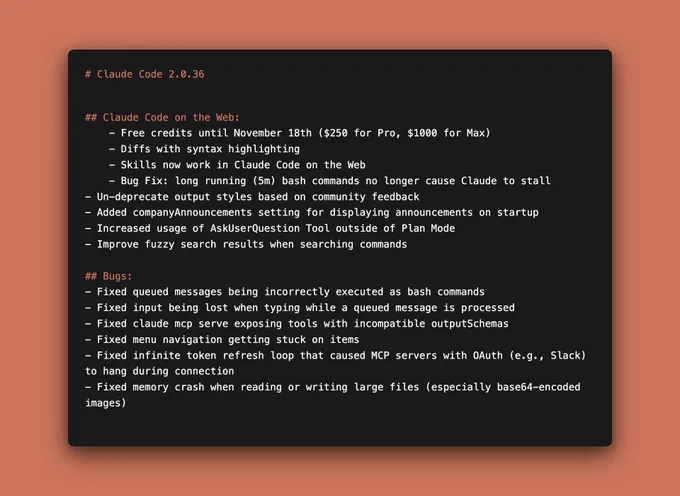
Claude Code Weekly Roundup
This week we rolled out a new promo for free credits on Claude Code on the web along with beautiful diffs and support for skills.
In the CLI we improved fuzzy search, did a slew of bug fixes & improved triggering for interactive questions.

Sharing the MEAP link to this book as it's no longer Manning's Deal of the Day:
hubs.la/Q03Q0h4p0
Behrooz Azarkhalili retweeted

A simple trick cuts your LLM costs by 50%!
Just stop using JSON and use this instead:
TOON (Token-Oriented Object Notation) slashes your LLM token usage in half while keeping data perfectly readable.
Here's why it works:
TOON's sweet spot: uniform arrays with consistent fields per row. It merges YAML's indentation and CSV's tabular structure, optimized for minimal tokens.
Look at the example below.
JSON:
{
"𝘂𝘀𝗲𝗿𝘀": [
{ "𝗶𝗱": 𝟭, "𝗻𝗮𝗺𝗲": "𝗔𝗹𝗶𝗰𝗲", "𝗿𝗼𝗹𝗲": "𝗮𝗱𝗺𝗶𝗻" },
{ "𝗶𝗱": 𝟮, "𝗻𝗮𝗺𝗲": "𝗕𝗼𝗯", "𝗿𝗼𝗹𝗲": "𝘂𝘀𝗲𝗿" }
]
}
Toon:
𝘂𝘀𝗲𝗿𝘀[𝟮]{𝗶𝗱,𝗻𝗮𝗺𝗲,𝗿𝗼𝗹𝗲}:
𝟭,𝗔𝗹𝗶𝗰𝗲,𝗮𝗱𝗺𝗶𝗻
𝟮,𝗕𝗼𝗯,𝘂𝘀𝗲𝗿
It's obvious how few tokens are being used to represent the same information!
To summarise, here are the key features:
💸 30–60% fewer tokens than JSON
🔄 Borrows the best from YAML & CSV
🤿 Built-in validation with explicit lengths & fields
🍱 Minimal syntax (no redundant braces, brackets, etc.)
IMPORTANT!!
That said, for deeply nested or non-uniform data, JSON might be more efficient.
In the next tweet, I've shared some benchmark results demonstrating the effectiveness of this technique in reducing the number of tokens and improving retrieval accuracy with popular LLM providers.
Where do you think this could be effective in your existing workflows?
Find the relevant links in the next tweet!


Multimodal LLMs aren’t magic -just a projector layer, a translator, turning images/audio into tokens.
The latest AI Newsletter shows how to run them with Docker Model Runner (plus demos): bit.ly/4owXosC
#Docker #ModelRunner #AI #LLM #Multimodal
Behrooz Azarkhalili retweeted

Claude Code just added a new environment variable yesterday 😨
CLAUDE_CODE_EXIT_AFTER_STOP_DELAY - auto-exits SDK mode after idle duration. Useful for CI/CD and automated workflows.
Wrote up a complete reference covering all 40+ variables (auth, models, performance, cloud integration)
Link: medium.com/@dan.avila7/claud…


Running Claude Code isn’t just about opening the terminal and typing the perfect prompt.
(Bookmark this post for later)
There are environment variables that can influence how Claude Code runs, connects to models, and even how its interface behaves.
🧵 Here’s a thread with all of them organized by category:
Behrooz Azarkhalili retweeted

You can now get any website branding via 1 API call
Use it to power your onboarding flows, create apps based on your design language and even clone other websites to inspire your new creations
Feed the result to an LLM and watch the magic happen


Behrooz Azarkhalili retweeted

@DSPyOSS signatures + TOON 🔥🚀

DSPy Signatures anchor your app in a world where everything changes—prompting techniques, model families, even serialization formats.
vicentereig.github.io/dspy.r…
Pair TOON with @boundaryML's BAML and BOOM! Drop tokens in half.



You can now add prompt-based stop hooks to Claude Code.
Prompt hooks are great for encouraging Claude to work for longer periods of time, doing clean up work like removing extra files, writing tests or keeping track of what work is being done.


