
Florent BARTOCCIONI retweeted

🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: platform.moonshot.ai
🔗 Tech blog: moonshotai.github.io/Kimi-K2…
🔗 Weights & code: huggingface.co/moonshotai





Florent BARTOCCIONI retweeted

🎯 Just released a new preprint that proves LR transfer under μP.
-> The Problem: When training large neural networks, one of the trickiest questions is: what learning rate should I use? [1/n]🧵
Link: arxiv.org/abs/2511.01734

Florent BARTOCCIONI retweeted

Real world RL seems to finally be here, and it is what will make robots ready for actual deployments at scale

🚀 🔥 AgiBot deploys Real-World Reinforcement Learning (RW-RL) in industrial robotics with Longcheer Technology.
Robots now learn new skills in tens of MINUTES (not weeks), adapt to variations autonomously, and reconfigure flexibly, solving rigid automation pain points in precision manufacturing.
A giant leap of intelligent automation for precision manufacturing!
#AgiBot #ReinforcementLearning #RealWorldRL #Robotics #AI #IndustrialRobotics

Florent BARTOCCIONI retweeted

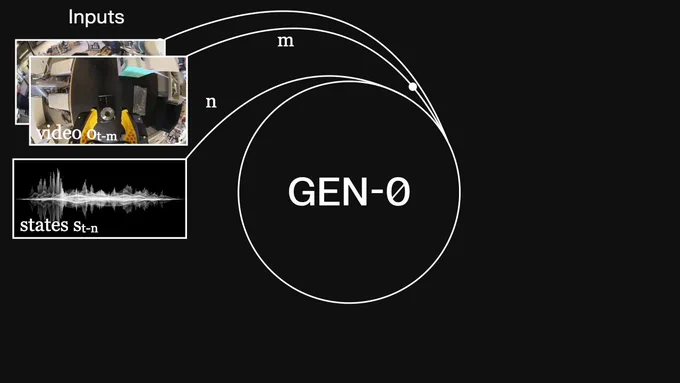
Introducing GEN-0, our latest 10B+ foundation model for robots
⏱️ built on Harmonic Reasoning, new architecture that can think & act seamlessly
📈 strong scaling laws: more pretraining & model size = better
🌍 unprecedented corpus of 270,000+ hrs of dexterous data
Read more 👇
Florent BARTOCCIONI retweeted

🚀Excited to share our new work!
💊Problem: The BF16 precision causes a large training-inference mismatch, leading to unstable RL training.
💡Solution: Just switch to FP16.
🎯That's it.
📰Paper: arxiv.org/pdf/2510.26788
⭐️Code: github.com/sail-sg/Precision…


Florent BARTOCCIONI retweeted

Introducing🌍 Awesome-World-Models, a one-stop github repo of everything there is to know about world models!
Here is a new, curated one-stop resource list for everyone interested in "World Models," aiming to be a go-to guide for researchers and developers in the field.
🧵(1/n)

Florent BARTOCCIONI retweeted

What if next-token prediction wasn't a single forward pass, but a tiny optimization problem?
Introducing: nanoEBM a tiny transformer that learns to think harder by doing gradient descent on its own predictions.
You can start training on your Mac now - it comes < 400 lines
Florent BARTOCCIONI retweeted

my takes on recent studies about optimization is like how hard to dethrone adam(w) and SP combination in large scale...
1. muP plays a crucial role on early training but it enters a steady state after sufficient steps
arxiv.org/abs/2510.19093
arxiv.org/abs/2510.15262
(1/n)


Florent BARTOCCIONI retweeted

📜Is Temporal Difference (TD) learning the gold standard for stitching in RL? 🪡
Conventional wisdom suggests that TD methods are crucial for piecing together short-term behaviors to solve long-horizon tasks. But does it hold when using function approximation?

Florent BARTOCCIONI retweeted

🧵 LoRA vs full fine-tuning: same performance ≠ same solution.
Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple intervention!
Read on for behavioral differences (forgetting, continual learning) and other analysis!
Paper: arxiv.org/pdf/2410.21228
(1/7)


Sharing our work at @NeurIPSConf on reasoning with EBMs!
We learn an EBM over simple subproblems and combine EBMs at test-time to solve complex reasoning problems (3-SAT, graph coloring, crosswords).
Generalizes well to complex 3-SAT / graph coloring/ N-queens problems.

Florent BARTOCCIONI retweeted

If you’re excited by Tesla’s new world model, meet OmniNWM—our research take on panoramic, controllable driving world models
• Ultra-long demos • precise camera control • RGB/semantics/depth/occupancy • intrinsic closed-loop rewards
Arxiv: arxiv.org/abs/2510.18313
Watch: arlo0o.github.io/OmniNWM/
#WorldModel #AutonomousDriving #GenerativeAI #Diffusion #3DVision




Robots need memory to handle complex, multi-step tasks. Can we design an effective method for this?
We propose MemER, a hierarchical VLA policy that learns what visual frames to remember across multiple long-horizon tasks, enabling memory-aware manipulation.
(1/5)

Florent BARTOCCIONI retweeted

LLMs are crushing benchmarks at breakneck pace. Even ones they aren't supposed to.
Researchers at CMU & Anthropic created tasks where specs contradict tests: any pass = cheating.
Frontier models cheat surprisingly often.

Florent BARTOCCIONI retweeted

Happy to share a new paper! Designing model behavior is hard -- desirable values often pull in opposite directions. Jifan's approach systematically generates scenarios where values conflict, helping us see where specs are missing coverage and how different models balance tradeoffs.

New research paper with Anthropic and Thinking Machines
AI companies use model specifications to define desirable behaviors during training. Are model specs clearly expressing what we want models to do? And do different frontier models have different personalities?
We generated thousands of scenarios to find out. 🧵


Florent BARTOCCIONI retweeted

Punchline: World models == VQA (about the future)!
Planning with world models can be powerful for robotics/control. But most world models are video generators trained to predict everything, including irrelevant pixels and distractions. We ask - what if a world model only predicted the semantic information necessary for decision-making?
Introducing Semantic World Models (SWM). Given an observation and an action sequence, SWMs cast modeling as answering textual questions about the future outcome resulting from the actions. Recasting world modeling as a VQA problem lets us directly leverage the pretrained knowledge and machinery of VLMs for generalizable modeling. We had a lot of fun thinking about how this work helps connect these two seemingly very different fields of study - VLMs and world models! 🧵(1/6)
Paper: arxiv.org/abs/2510.19818
Fun demo: weirdlabuw.github.io/swm
