
NLP and speech researcher in iflytek
Joined March 2016
- Tweets 826
- Following 794
- Followers 29
- Likes 325
how retweeted

🚨 This might be the most mind-bending AI breakthrough yet.
China just built an AI that doesn’t just explain how the universe works it actually understands why.
Most of science is a black box of conclusions. We know the “what,” but the logic that connects everything the “why” is missing. Researchers call it the dark matter of knowledge: the invisible reasoning web linking every idea in existence.
Their solution is unreal.
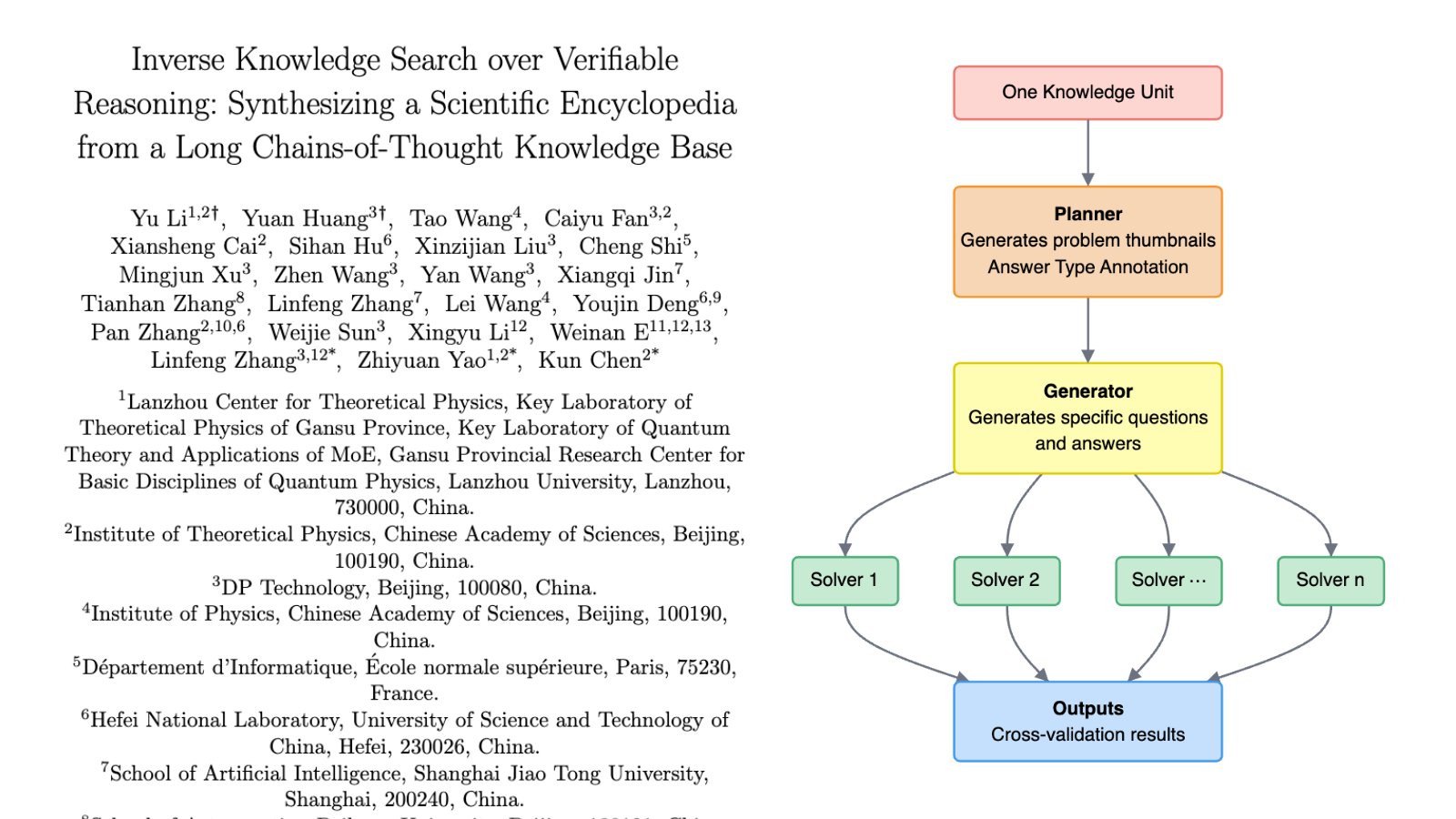
A Socrates AI Agent that generates 3 million first-principles questions across 200 fields, each one answered by multiple LLMs and cross-checked for logical accuracy.
What it creates is a Long Chain-of-Thought (LCoT) knowledge base—where every concept in science can be traced back to its fundamental truths.
Then they went further.
They built a Brainstorm Search Engine for inverse knowledge discovery.
Instead of asking “What is an Instanton?”, you can explore how it emerges through reasoning paths that connect quantum tunneling, Hawking radiation, and 4D manifolds.
They call it:
“The dark matter of knowledge, finally made visible.”
The project SciencePedia already maps 200K verified scientific entries across physics, math, chemistry, and biology.
It shows 50% fewer hallucinations, denser reasoning than GPT-4, and traceable logic behind every answer.
This isn’t just better search.
It’s the first AI that exposes the hidden logic of science itself.
Comment “Send” and I’ll DM you the paper.
how retweeted

the kimi k2 creative writing RL rubric clamps down on qualifiers and justifications, making it “confident and assertive, even in contexts involving ambiguity or subjectivity.”
helps explain k2's muscular writing style / aesthetic risk taking
@dbreunig on subjective rubrics:

how retweeted

And the article I mentioned in the talk, the one I promised to write as a follow-up, is this one: magazine.sebastianraschka.co…


how retweeted

New @AIatMeta paper explains when a smaller, curated dataset beats using everything.
Standard training wastes effort because many examples are redundant or wrong.
They formalize a label generator, a pruning oracle, and a learner.
From this, they derive exact error laws and sharp regime switches.
With a strong generator and plenty of data, keeping hard examples works best.
With a weak generator or small data, keeping easy examples or keeping more helps.
They analyze 2 modes, label agnostic by features and label aware that first filters wrong labels.
ImageNet and LLM math results match the theory, and pruning also prevents collapse in self training.
----
Paper – arxiv. org/abs/2511.03492
Paper Title: "Why Less is More (Sometimes): A Theory of Data Curation"

how retweeted

This author shows that grokking can arise purely from an initial and quick overfitting of data followed by a movement on the zero-loss region guided purely by weight decay.
🔗arxiv.org/abs/2511.01938





.@MiniMax__AI M2 uses "interleaved thinking" - instead of one thinking block at the start, you get multiple thinking blocks throughout a single request.
The model re-evaluates its approach as it goes, adapting based on tool outputs and new information. You'll see these thinking blocks appear in the UI showing its reasoning process in real-time.
Available free in Cline until November 7!




A core ingredient in scaling RL and self-improvement is a stream of good tasks. Where do they come from?
🌿NaturalReasoning (arxiv.org/abs/2502.13124) explored using LLMs to curate diverse tasks at scale based on human-written tasks.
🤖Self Challenging Agent (arxiv.org/abs/2506.01716), demonstrated that LLMs can propose useful tasks after interacting with the environment and tools.
🌶️Our new work SPICE combines insights from both: it creates an automatic curriculum proposing and solving tasks. New tasks are created optimizing for learnability. I'm excited about scaling synthetic tasks in self-improvement to complement other scaling dimensions!

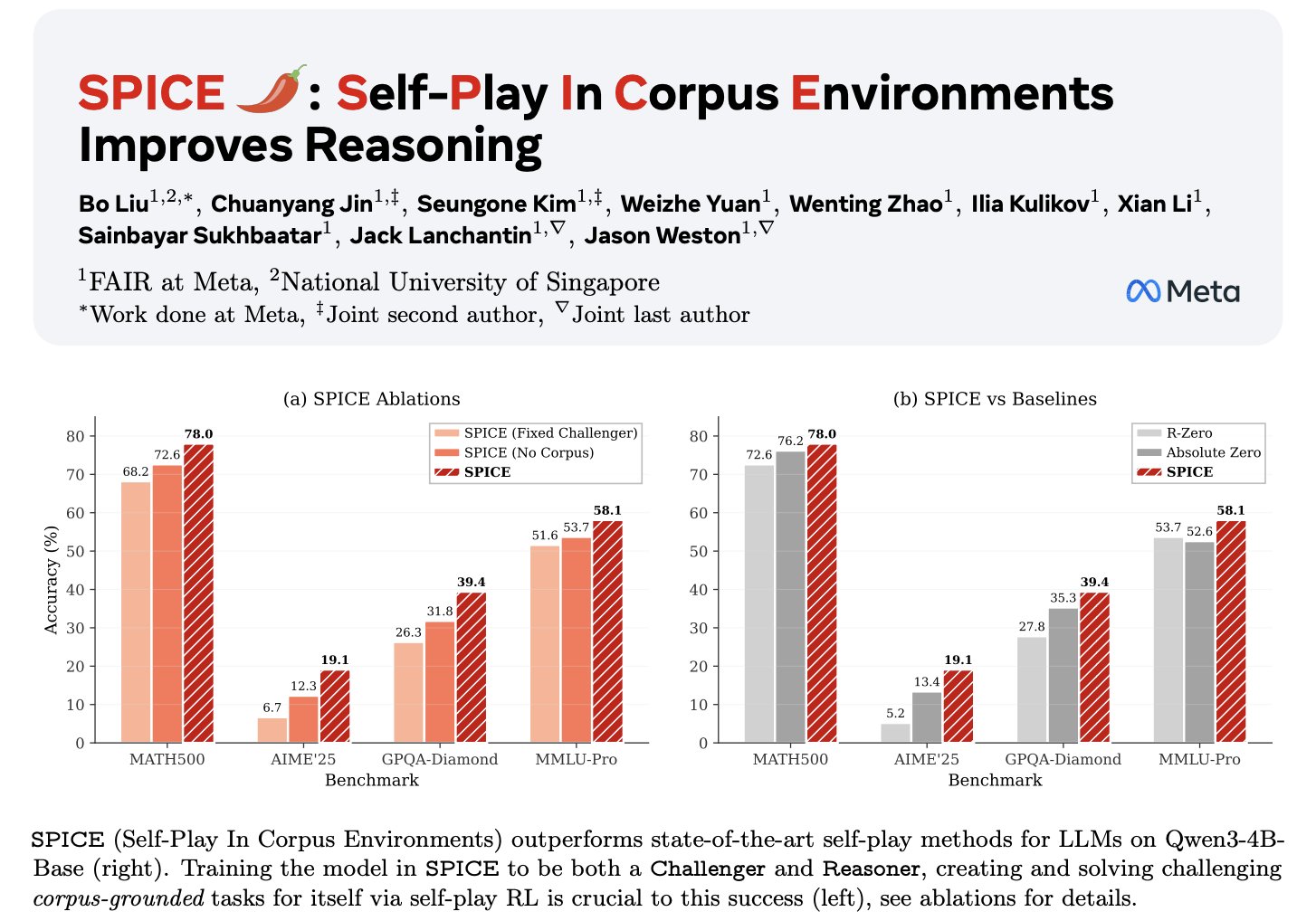
🌶️SPICE: Self-Play in Corpus Environments🌶️
📝: arxiv.org/abs/2510.24684
- Challenger creates tasks based on *corpora*
- Reasoner solves them
- Both trained together ⚔️ -> automatic curriculum!
🔥 Outperforms standard (ungrounded) self-play
Grounding fixes hallucination & lack of diversity
🧵1/6
how retweeted

The "Reasoning Pattern": The One Thing Your LLM Is Missing
AI companies are spending millions on a huge, expensive mistake.
They're paying armies of people to teach AI how to "think," step-by-step.
A new paper reveals there's a way to get the same results for a fraction of the cost, and it's brilliantly simple.
🧵…
Imagine teaching a student to solve a specific type of math problem.
The standard AI training method is like giving them 10,000 solved examples, written out by expensive tutors. The hope is that the student eventually learns the process.
This is called "rationale annotation."
This process is a massive bottleneck. It's slow, costs a fortune, and operates on the assumption that "more data is always better."
But a new paper, "Reasoning Pattern Matters," decided to question that very assumption.
The researchers asked: What's more important? The thousands of human-written examples, or the underlying pattern of thinking they demonstrate?
To find out, they ran a couple of experiments.
First, they took the training data and threw 90% of it away. They trained an AI on just 1,000 examples instead of 10,000.
The result? The AI performed almost identically.
The sheer volume of examples didn't seem to matter.
But that's not even the craziest part.
Next, they took that small dataset and had an AI intentionally corrupt 25% of the reasoning steps to be wrong.
The final model's performance barely dropped.
How is this possible?
Because the model wasn't memorizing the content of the examples. It was learning the structural PATTERN of reasoning.
It was learning the recipe, not memorizing thousands of finished cakes.
This insight led to their breakthrough framework: PARO (Pattern-Aware Rationale Annotators).
Instead of paying humans to write 10,000 examples, they just wrote down the thinking pattern once, like a simple checklist for a specific task.
They gave this checklist to a powerful AI and said:
"Here's a problem and the final answer. Now, generate the step-by-step reasoning that follows this exact pattern."
It became an automatic, cheap, rationale-writing machine.
The punchline:
The AI trained on these cheap, machine-generated rationales performed just as well as the one trained on the huge, expensive, human-annotated dataset.
They effectively replaced 10,000 human examples with 1 human-written pattern.
This gives us a new mental model for AI.
Effective reasoning isn't about having a giant library of answers. It's about having a small, versatile toolbox of thinking procedures.
Quality of instruction beats quantity of data.
This is a huge deal. It means developing powerful, reasoning AI could become dramatically cheaper and faster.
It shifts human effort from doing repetitive annotation work to the more creative task of defining how we want an AI to think.
Ultimately, the paper proves a profound point that applies far beyond AI.
The most effective way to teach isn't to show the answer a thousand times. It's to clearly explain the method once.
The goal isn't to teach what to think, but how to think.
If you're into AI, this is a must-read. It's practical, brilliant, and could change how the next generation of models are built.
Paper: "Reasoning Pattern Matters: Learning to Reason without Human Rationales" by Chaoxu Pang, Yixuan Cao, & Ping Luo.

how retweeted

Holy shit… Meta might’ve just solved self-improving AI 🤯
Their new paper SPICE (Self-Play in Corpus Environments) basically turns a language model into its own teacher no humans, no labels, no datasets just the internet as its training ground.
Here’s the twist: one copy of the model becomes a Challenger that digs through real documents to create hard, fact-grounded reasoning problems. Another copy becomes the Reasoner, trying to solve them without access to the source.
They compete, learn, and evolve together an automatic curriculum with real-world grounding so it never collapses into hallucinations.
The results are nuts:
+9.1% on reasoning benchmarks with Qwen3-4B
+11.9% with OctoThinker-8B
and it beats every prior self-play method like R-Zero and Absolute Zero.
This flips the script on AI self-improvement.
Instead of looping on synthetic junk, SPICE grows by mining real knowledge a closed-loop system with open-world intelligence.
If this scales, we might be staring at the blueprint for autonomous, self-evolving reasoning models.

how retweeted
With the release of the Kimi Linear LLM last week, we can definitely see that efficient, linear attention variants have seen a resurgence in recent months. Here's a brief summary of what happened.
First, linear attention variants have been around for a long time, and I remember seeing tons of papers in the 2020s.
I don't want to dwell too long on these older attempts. But the bottom line was that they reduced both time and memory complexity from O(n^2) to O(n) to making attention much more efficient for long sequences.
However, they never really gained traction as they degraded the model accuracy, and I have never really seen one of these variants applied in an open-weight state-of-the-art LLM.
In the second half of this year, there was a bit of a revival of linear attention variants. The first notable model was MiniMax-M1 with lightning attention, a 456B parameter mixture-of-experts (MoE) model with 46B active parameters, which came out back in June.
Then, in August, the Qwen3 team followed up with Qwen3-Next, which I discussed in more detail above. Then, in September, the DeepSeek Team announced DeepSeek V3.2 with sparse attention.
All three models (MiniMax-M1, Qwen3-Next, DeepSeek V3.2) replace the traditional quadratic attention variants in most or all of their layers with efficient linear variants. (DeepSeek's sparse attention it's not strictly linear but still subquadratic).
Interestingly, there was a recent plot twist, where the MiniMax team released their new 230B parameter M2 model (discussed in section 13) without linear attention, going back to regular attention. The team stated that linear attention is tricky in production LLMs. It seemed to work fine with regular prompts, but it had pure accuracy in reasoning and multi-turn tasks, which are not only important for regular chat sessions but also agentic applications.
This could have been a turning point where linear attention may not be worth pursuing after all. However, it gets more interesting. Last week, the Kimi team released their new Kimi Linear model with linear attention. The tag line is that compared to regular, full attention, it has a 75% KV cache reduction and up to 6x decoding throughput.
Kimi Linear shares several structural similarities with Qwen3-Next. Both models rely on a hybrid attention strategy. Concretely, they combine lightweight linear attention with heavier full attention layers. Specifically, both use a 3:1 ratio, meaning for every three transformer blocks employing the linear Gated DeltaNet variant, there's one block that uses full attention as shown in the figure below.
However, Kimi Linear modifies the linear attention mechanism of Qwen3-Next by the Kimi Delta Attention (KDA) mechanism, which is essentially a refinement of Gated DeltaNet. Interestingly, it also replaces the standard full attention module by multi-head latent attention.
There's no direct comparison to Qwen3-Next in the Kimi Linear paper, but compared to the Gated DeltaNet-H1 model from the Gated DeltaNet paper (which is essentially Gated DeltaNet with sliding-window attention), Kimi Linear achieves higher modeling accuracy while maintaining the same token-generation speed.
Of course, I couldn't resist and added it to my The Big LLM Architecture Comparison article, which has grown to >10,000 words now (basically becoming book!?).

how retweeted

Thrilled to release new paper: “Scaling Latent Reasoning via Looped Language Models.”
TLDR: We scale up loop language models to 2.6 billion parameters, and pretrained on > 7 trillion tokens. The resulting model is on par with SOTA language models of 2 to 3x size.

how retweeted

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
thinkingmachines.ai/blog/on-…


how retweeted

🚨 This is wild.
A new paper from the Ling team just dropped "Every Attention Matters" and it quietly rewrites how long-context reasoning works in LLMs.
Their new Ring-linear architecture mixes Softmax and Linear Attention, cutting inference cost by 10x while keeping SOTA accuracy up to 128K tokens.
Even crazier:
• Training efficiency +50%
• Inference speed +90%
• Stable RL optimization over ultra-long sequences
Basically, they solved long-context scaling without trillion-parameter overkill.
The future isn’t bigger models. It’s smarter attention.

how retweeted

There are many (valid) critics about RL these days:
- RL training w/ scalar reward (eg GRPO): repetitive sampling + scalar reward has extremely low signal/noise ratio;
- Test-time RL w/ language feedback (reflection/agent scaffold/prompt-opt): rich information, faster learning, but no param update --- limited capability, easily saturated after a few rounds.
How to escape these dead zones? Maybe we should stop treating them as separate and parallel RL mechanisms!
🫶Introducing LANPO, Language And Numerical Policy Optimization that combines the best of both worlds:
1/ repetitive sampling -> sampling w/ experience & language feedback: the language RL learner can cultivate past (relevant) trajectories and use language reflection to explore the solution space much more efficiently;
2/ the numerical RL learner can train on the successful rollouts from the language learner, so the updated policy is stronger at driving the language learner.
3/ at test time, the LANPO model would natively support the ability to cultivate past experience and language feedback for solving hard problems!
However, the path is not easy. Even though each works well alone, combining them together can be surprisingly frustrating(!). Language feedback can often introduce information leakage or behavior collapse in the RL training loop. We detailed the pains and gains in the paper.
With our final recipe, RL learns from both language and numerical feedback within one update, turning their weaknesses into strengths — language feedback gains model updates, and numerical feedback gains richer exploration.
LANPO improves both zero-shot and experience-driven generation, and is particularly effective on hard reasoning tasks — achieving +4% over GRPO on AIME’25 with a 7B model and +8% with a 14B model, all under the same training setup. Interestingly, larger models, which better leverage language feedback, can benefit even more from LANPO.
Paper link: arxiv.org/abs/2510.16552
Huge kudos to Ang, the first author, for bravely taking on this idea during his internship at ByteDance Seed and turning it into reality despite many setbacks!

how retweeted

Can LLMs reason beyond context limits? 🤔
Introducing Knowledge Flow, a training-free method that helped gpt-oss-120b & Qwen3-235B achieve 100% on the AIME-25, no tools.
How? like human deliberation, for LLMs.
📝 Blog: yufanzhuang.notion.site/know…
💻 Code: github.com/EvanZhuang/knowle…


【中文复刻版】Andrej Karpathy 2小时访谈:未来十年,没有 AGI,只有 Agent xiaoyuzhoufm.com/episode/68f…
how retweeted

btw I might need to cover this lesser known gem that karpathy is referring to in a paper review livestream
it’s well done research


The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!

how retweeted
This paper shows a simple way to boost LLM reasoning by scaling prompts, not data.
It uses 90 seed math problems and expands them at test time to create many reasoning contexts.
The method:
Each problem is rewritten several times using different “instruction frames.” For example, one version says “You’ll get a reward for the correct answer,” another says “You’ll be penalized if wrong,” another says “Be careful to be correct,” and another says “Solve step by step.”
These small changes don’t alter the problem itself but change how the model thinks about solving it.
The model (a stronger “teacher” LLM) is then asked to solve all these rewritten prompts. Each answer it gives, along with its reasoning steps, becomes a new training example.
This creates a large and diverse dataset built from just 90 seeds.
Finally, a smaller “student” model like Qwen2.5 (7B, 14B, or 32B) is fine-tuned on all these generated reasoning traces.
Because the student sees so many different ways of thinking about the same problems, it learns to reason more flexibly and performs as well as models trained on much bigger datasets
With 900 examples, the 32B model matches or beats 1K-shot baselines on common reasoning tests.
The key idea is that exploring prompt variety is a stronger lever than adding fixed examples.
----
Paper – arxiv. org/abs/2510.09599
Paper Title: "Prompting Test-Time Scaling Is A Strong LLM Reasoning Data Augmentation"
