
Monotonic chunkwise read-only profile 😂
Moscow, Russia
Joined October 2021
- Tweets 365
- Following 66
- Followers 6
- Likes 89
d k retweeted

New @AIatMeta paper explains when a smaller, curated dataset beats using everything.
Standard training wastes effort because many examples are redundant or wrong.
They formalize a label generator, a pruning oracle, and a learner.
From this, they derive exact error laws and sharp regime switches.
With a strong generator and plenty of data, keeping hard examples works best.
With a weak generator or small data, keeping easy examples or keeping more helps.
They analyze 2 modes, label agnostic by features and label aware that first filters wrong labels.
ImageNet and LLM math results match the theory, and pruning also prevents collapse in self training.
----
Paper – arxiv. org/abs/2511.03492
Paper Title: "Why Less is More (Sometimes): A Theory of Data Curation"

d k retweeted

Can we run RL to train LLMs on hard-to-verify or open-ended tasks? Even when tasks are verifiable, it is often impossible to check every design detail or catch all mistakes.. We can go prompt-tune LLM judges, but is that really the answer?
Our new paper introduces RLAC: a procedure that also trains the judge/critic dynamically during RL. The critic finds just one most likely mistake in response, the generator fixes it, and now the critic updates itself to find new mistakes... this adversarial training procedure does really well!

d k retweeted

For many agent tasks:
(1) you don't need a full physical simulators to know what's gonna happen;
(2) many share abstract structures rooted in similar environments that can be learned more generally.
So we wondered: why not train a model that:
(1) predicts what happens given the current agent action (as reward/feedback), and
(2) guides the agent through a curriculum of tasks, from easy to hard?
That's 𝗗𝗿𝗲𝗮𝗺𝗚𝘆𝗺, a new paradigm combining 𝘳𝘦𝘢𝘴𝘰𝘯𝘪𝘯𝘨 𝘦𝘹𝘱𝘦𝘳𝘪𝘦𝘯𝘤𝘦 𝘮𝘰𝘥𝘦𝘭 + 𝘳𝘦𝘱𝘭𝘢𝘺 𝘣𝘶𝘧𝘧𝘦𝘳 for consistent on-policy agent training without needing to build environments.
No more "RL-ready" or "non-RL-ready." We're seeing 30%+ gains over baselines.
📄 Check out details in our paper: arxiv.org/pdf/2511.03773
P.S. Felt like a homecoming to work with @ZRChen_AISafety again!

Scaling Agent Learning via Experience Synthesis
📝: arxiv.org/abs/2511.03773
Scaling training environments for RL by simulating them with reasoning LLMs!
Environment models + Replay-buffer + New tasks = cheap RL for any environments!
- Strong improvements over non-RL-ready environments and multiple model families!
- Works better in sim-2-real RL settings → Warm-start for high-cost environments
🧵1/7

d k retweeted

grad's tweets are full of alpha! highly recommend to read this one.


d k retweeted

I gave a talk on the Era of Real-World Human Interaction @Google
It's great to see frontier AI labs like Google taking a strong interest in understanding users and evolving their models through user interaction.
Yes, while today's AI can win gold at the IMO, it often struggles with meeting daily user needs and adapting to personal preferences.
The challenge: how can we bridge the gap between training data and real user demands? How can AI get smarter through every conversation?
In this talk, I argue for moving beyond expert-annotated data → learning from real user conversations. Our method, Reinforcement Learning from Human Interaction (RLHI), offers a simple, concrete approach.
RLHI learns directly from in-the-wild conversations:
(1) User-Guided Rewrites – revises unsatisfactory model outputs based on users' natural-language follow-up responses;
(2) User-Based Rewards – learns via a reward model conditioned on knowledge of the user's long-term interaction history (termed persona).
Together, they link long-term user personas to turn-level preferences via persona-conditioned preference optimization. Trained on WildChat, RLHI outperforms RLHF in personalization and instruction-following.
Thanks @maximillianc_ for the invite!

d k retweeted

Wow Quantization-enhanced Reinforcement Learning using vLLM! Great job by @yukangchen_ 😃

We open-sourced QeRL — Quantization-enhanced Reinforcement Learning !
🧠 4-bit quantized RL training
💪 Train a 32B LLM on a single H100 GPU
⚙️ 1.7× faster overall training
🎯 Accuracy on par with bfloat16-level accuracy
🔥 Supports NVFP4 quantization format
Moreover, we show that quantization helps exploration in RL training.
Paper: huggingface.co/papers/2510.1…
Code: github.com/NVlabs/QeRL
#NVIDIA #AIResearch #ReinforcementLearning #Quantization #LLM #EfficientAI

d k retweeted

Say you want to use multi-turn RL to train an LLM to interact with a user more effectively, but you can't afford to collect real human data. You might try using another LLM to simulate the human user.
Problem: LLMs kinda suck at this. They are often pretty poor and inconsistent simulations of real users.
In our recent NeurIPS paper, we formulate a multi-turn RL objective for training LLMs to more consistently simulate users during conversations.

Large Language Models (LLMs) are increasingly used to simulate human users in interactive settings. However, they often drift from their assigned personas, contradict earlier statements, or abandon role-appropriate behavior. We introduce a framework for evaluating and improving persona consistency in LLM-generated dialogue with multi-turn RL, defining three automatic metrics and validating each against human annotations. More below 👇

d k retweeted

Our work will be at #NeurIPS2025 in San Diego!
In collaboration with @rm_rf_ryan donovanclay @timalthoff @svlevine @natashajaques
Code: github.com/abdulhaim/consist…
Project Page: sites.google.com/view/consis…
arxiv.org/abs/2511.00222

d k retweeted

wrote a relatively-lengthy post on the different types of parallelism in LLMs
worthy read if you wanna understand what's going on under the hood
and why hardware configurations are complicated

- you are
- a person neck-deep in LLMs, wading through a sea of jargon
- “shards,” “experts,” “layers across nodes,” “tensor parallelism,”
- “pipeline parallelism,” “data parallelism”
- you keep hearing epic claims like
- “8 million tokens/sec on 1024 GPUs”
- and wonder, what the hell does that even look like on real hardware?
- we'll start with what “layers” even are,
- then walk the five parallelism axes,
- and then show how they combine
- is every GPU running a full copy of the model?
- or are the weights sharded across the cluster?
- are layers sliced up? what are “layers” to begin with?
- a “layer” = attention + MLP + residual glue
- ≈ a transformer block; then we stack 24 to 160 of them
- more on that below
- do whole blocks migrate to different nodes?
- does the batch get carved into pieces?
- is the context length split? or both?
- when do all these devices need to chat with each other?
- and what are they sending?
- what’s an “expert” in a Mixture-of-Experts model?
- and why do people make it sound like air-traffic control for tokens?
- as LLMs got bigger, nothing fit on one GPU
- so parallelism became the only way out
- but the word “parallelism” hides a zoo of strategies
- each one optimized for a different kind of problem
- sometimes you duplicate the model for raw throughput
- data parallelism
- sometimes you break each giant matrix multiply across devices
- tensor/model parallelism
- sometimes you hand off entire layers to the next GPU
- pipeline parallelism
- sometimes you dispatch tokens to “experts” scattered all over
- expert parallelism
- and sometimes, when the context is massive
- you even split the sequence itself
inference vs training? whole different beast
- inference:
- cares about context length
- key/value cache (KV cache) size
- serving tons of requests with minimal idle time
- prefill vs decode become separate bottlenecks
- training:
- wants big batches
- needs fast gradient sync
- huge memory for activations
- relentless all-reduce ops
so, when you see those monster numbers and wild claims, ask:
- what’s split?
- what’s duplicated?
- what’s just being pipelined through?
- who’s doing all the talking?
- GPUs?
- CPUs?
- or the people writing the framework hacks?
parallelism 101 isn’t just for LLM nerds
- it’s survival for anyone who wants to
- train
- fine-tune
- or serve
- models bigger than a single graphics card
- and we’re gonna break it all down, once and for all
first, a quick recap of how LLMs work
- llms are giant next-token guessers
- feed in tokens, model returns probabilities for what comes next
- this is conditional modeling: p(x_{t+1} | x_{1:t}); all "reasoning" is just maximizing next-token prediction over long contexts
- parallelism pressure: high accuracy means bigger models, longer contexts; both shatter single-device limits
- inference: just a loop
- sample → append → feed back in; repeat until done
- really two stages: prefill (encode the prompt, attention-heavy) and decode (one token at a time, cache-heavy)
- parallelism pressure: prefill wants maximum compute in parallel; decode needs memory bandwidth and batching
- training: minimizes how wrong those guesses are
- cross-entropy loss between predicted and actual token
- scale up data, parameters, context → better loss, but optimizer states and gradients balloon memory usage
- parallelism pressure: gradient sync and optimizer memory dominate; communication overhead becomes a first-class problem
- inside the model: a tall stack of transformer blocks
- each processes a sequence of vectors (tokens → embeddings)
- all blocks edit a shared “residual stream”
- parallelism hint: deep? pipeline split; wide? tensor split
- each block does two things
- self-attention: mix info across tokens (global context)
- mlp: rewrite each token’s vector (local transform)
- this global-then-local alternates for dozens to hundreds of layers
- parallelism hint: attention is sequence-bottlenecked, MLPs are flop-bottlenecked; each wants its own split
- layernorm + residuals keep things stable
- helps gradients flow; most use pre-norm
- deep stacks become trainable, but activations stay huge
- parallelism hint: activation memory = batch × seq × hidden; target for sequence/context sharding and activation checkpointing
- self-attention = queries, keys, values
- dot-products score “who attends to whom”; softmax makes weights; multi-heads see different relationships
- compute is O(L²) during prefill, O(L) per token in decode
- parallelism hint: quadratic prefill drives context parallelism; big KV drives KV sharding
- to scale: GQA / MQA (grouped/multi-query attention)
- fewer key/value sets per head, saves bandwidth/memory
- tiny quality hit, huge efficiency win (at ≤128 k context; when tuned)
- smaller KV → more requests/longer contexts per GPU
- rough rule: every extra 65k tokens at 70B costs ~2 GB/GPU even with GQA—yes, that adds up fast
- parallelism hint: makes tensor/data parallel more efficient with fixed memory
- position info: added or rotated
- learned embeddings or rotary encodings (RoPE)
- lets models generalize to longer sequences; RoPE directly encodes relative position in attention
- parallelism hint: long contexts make context/sequence parallelism indispensable
- mlp is the heavy lifter
- expand → activate → project down
- MoE = many mlps, only a few active per token; scale params without scaling compute, but adds network overhead
- dense MLPs dominate FLOPs; MoE swaps dense compute for routing and all-to-all comms
- parallelism hint: dense → tensor/pipeline, MoE → expert parallel + token shuffling
- top of the model: one last layernorm, then lm head
- maps hidden states to vocab logits; often reuses input embedding weights
- weight tying helps parameter and cache efficiency
- parallelism hint: LM head is another big matmul; follows tensor/pipeline split of previous layers
- decoding: pick a sampler
- greedy, temp, top-k/p, beam, speculative; just ways to choose the next token
- speculative/batch schedulers keep GPUs busy
- parallelism hint: data parallel absorbs throughput, tensor/context sharding fights latency for long prompts
- alignment (rlhf, dpo, etc.): guide preferences
- tweaks outputs, core compute is unchanged
- fine-tunes shift sampling tendencies, not compute graph
- parallelism hint: training still needs gradient sync, same memory/comm bottlenecks
- systems view: 95% is big matrix multiplies (gemms)
- rest is cheap elementwise ops
- hardware lives or dies by gemm performance
- memory bandwidth, interconnect, and collectives (all-reduce/all-to-all) are the real ceilings
- parallelism hint: pick the axis that minimizes your dominant comms pattern
- two compute phases:
- prefill: quadratic attention, load whole prompt
- decode: one token at a time, kv cache is bottleneck
- kv cache per layer ≈ (B × L × 2 × n_kv × d_head × bytes); multiply by layers = why memory vanishes
- parallelism hint: prefill likes context/sequence sharding, decode likes batching and kv sharding
- why split the model at all? simple concept, ugly in practice:
- VRAM runs out
- bandwidth bottlenecks
- FLOPS max out
- only way out: parallelism
- weights, work, and state are each huge; but for different reasons
- and each one pushes you toward a different split axis
parallelism 101
- single GPU:
- can’t hold the weights
- can’t fit the KV cache
- doesn’t have enough compute
- doesn’t scale to real LLMs
- goal:
- break up the compute
- split the memory
- keep every GPU doing something useful
- avoid idle cycles and bottlenecks
tensor parallelism (TP)
- step up: model is too big, so shard within layers (split big matmuls/attn heads across GPUs)
- for inference:
- single prompt can use all TP devices; shard weights and KV cache across GPUs
- unlocks longer context/one-shot mega-prompts (because each GPU only needs its chunk)
- minimal latency penalty; comms are per-token and per-layer, but hidden in GEMM (if intra-node NVLink)
- first thing you do when the model won’t fit in one GPU but you want max single-query performance
- for training:
- you split GEMMs (e.g., QKV/MLP) across N devices; everyone computes a slice, then you all-reduce at the end of the layer
- comms: ~2 all-reduce ops per layer forward/backward
- all math, no waiting for whole layers to finish
- works best when all GPUs on fast local links (NVLink/NVSwitch), otherwise, you’re bottlenecked
- pair with “sequence parallelism” (SP): shard along sequence axis for even bigger speedups/memory wins
- rule: TP is your go-to for splitting big layers/weights/KV; always keep it intra-node if you can
pipeline parallelism (PP)
- think “assembly line”: split the model by layers into stages, put each stage on a GPU (or group)
- for inference:
- each token passes through the pipeline (latency = num_stages × per-stage time)
- adds overhead for low concurrency (pipeline bubbles)
- but: lets you split very tall models across more GPUs (and multiple nodes)
- often combined with TP (per stage) + DP (across nodes)
- for training:
- feed microbatches in like cars on a factory line
- early GPUs start on batch N+1 while late GPUs are still finishing batch N
- scheduling: “1F1B” (one-forward-one-backward) is classic, interleaved is better (reduces bubbles, keeps more cards hot)
- comms: point-to-point; just send activations/gradients to the next/prev stage
- fills/drains pipeline at start/end, so latency is worse for small batches
- rule: use PP when model depth > what fits per device/group; throughput wins, single-token latency suffers
data parallelism (DP)
- start simple: every GPU/node gets a full copy of the model
- for inference: each replica can serve requests independently; easy throughput scaling, zero comms
- but: each replica needs its own KV cache; you burn VRAM linearly with batch count
- for training: each works on a different chunk of the data, then they sync gradients (all-reduce)
- memory: each replica has full weights, grads, optimizer state
- comms: one big all-reduce per step (bottleneck: slow interconnect or huge models)
- modern fix: ZeRO/FSDP; shard optimizer states, grads, even params across devices
- ZeRO-3: sharded everything; now any one GPU sees a fraction of the model/optimizer
- lets you squeeze 100B+ params onto commodity hardware
- rule: DP is how you get more throughput; for bigger models, combine with model parallelism
expert parallelism (EP, MoE)
- Mixture of Experts (MoE): only some parameters get used per token; rest sleep, save FLOPs
- for inference:
- tokens routed to experts (ideally local); all-to-all overhead dominates small batch serving unless you get smart with locality/routing
- top-1 routing + local experts is the new meta; keeps network from killing tail latency
- MoE good for “big brain, small budget”; huge capacity, modest compute, but only if you nail the routing and don’t bottleneck network
- for training:
- “experts” (sub-MLPs) spread across GPUs; router sends each token to top-1/2/4 experts
- comms: two big all-to-all shuffles per MoE layer (tokens to experts, then back)
- modern tricks: Expert-Choice, dropless routing, hierarchical shuffles; less network pain, better load balance
- only the selected experts do work, so you scale parameter count without scaling compute linearly
- parallelize: TED = Tensor × Expert × Data (often add Pipeline for 4D grid)
- rule: use EP to unlock parameter scaling beyond dense; just mind the network, and tune routing for your hardware
sequence/context parallelism (SP/CP)
- the bonus round: split the sequence axis, not just layers or weights
- why: LLMs with 128k, 1M, or more context tokens = “KV cache and attention matrices are the new bottleneck”
- for inference/training:
- shard activations/KV cache across sequence positions (instead of model dims or layers)
- Megatron Context Parallelism, DeepSpeed-Ulysses, Ring-Attention: new tricks for linear scaling with context size
- pairs well with TP/PP/EP, especially for long-context, high-concurrency serving
- rule: add SP/CP when context/KV cache eats your VRAM, or you want fast prefill for million-token prompts
putting it together: real-world layouts
- serving LLMs (inference)
- model fits on one GPU? just use DP, batch requests, done
- model too big? add TP (intra-node, 2-4 GPUs, shard weights/KV)
- still too big? PP (split layers), then DP for multi-node throughput
- long contexts? CP/SP (shard sequence/KV), paged attention, GQA/MQA to shrink KV
- MoE? use EP, but always fight for local experts and top-1 routing
- training LLMs
- start with DP (and ZeRO/FSDP) for throughput/memory relief
- model too wide? add TP
- model too deep? add PP, interleave for less pipeline bubble
- MoE? grid up: TED (+ PP), tune batch/expert per device for best balance
- context too big? SP/CP and activation checkpointing
- always checkpoint activations if memory is tight; mix and match as needed
a quick bridge to parallelism (what each axis “fixes”):
- data parallelism (dp)
- replicate the whole model, split the batches
- fixes throughput and gradient noise, but not per-replica memory
- unless you also shard optimizer/params (e.g. ZeRO, FSDP)
- tensor (or model) parallelism (tp)
- shard within layers (split big matmuls/attn)
- fixes single-layer width/weight size and per-token compute;
- introduces per-layer collective ops
- pipeline parallelism (pp)
- shard across layers (depth)
- fixes total weight memory by spreading blocks across stages;
- introduces pipeline bubbles; hide with micro-batching
- expert parallelism (ep)
- shard MoE experts across devices, route tokens to a few experts
- fixes param count without dense compute;
- introduces all-to-all comms and load-balancing.
- sequence/context parallelism (sp/cp)
- shard along the sequence axis
- fixes long-context prefill and kv memory by splitting tokens/devices;
- pairs well with tp and paged kv caches
systems cheat sheet: when to use what
- DP: for throughput and data sharding; ZeRO/FSDP to cut memory; inference just replicas
- TP: for single-model multi-GPU (shard big layers, weights, KV); keep within fast local links
- PP: for tall models (split by layer); more stages = more bubble, but necessary for true giants
- EP (MoE): for max params at fixed compute; tune routing and batch; network is the limiter
- SP/CP: for ultra-long context or when KV cache dominates; essential for 128k+ or high concurrency
- Combine: 3D, 4D, even 5D grids (e.g., TP×EP×DP×PP×SP) for trillion-param monsters
modern tricks
- paged attention, continuous batching (vLLM, TensorRT-LLM): unlock huge batch + context + utilization
- GQA/MQA: shrink KV cache and bandwidth, scale to long prompts
- context parallelism: finally scales prefill to dozens of GPUs for million-token demos
- interleaved pipelines: +10% throughput, almost free
- MoE: top-1 routing + expert-choice/hierarchical shuffling = practical at scale
keep this map in mind: always ask; what’s your bottleneck?
- weights, work, or state?
- the right parallelism makes the big thing smaller,
- without making communication the new bottleneck
- you made it to the end
- now you know: every parallelism axis is a lever, not a panacea
- the real move is combining axes for your exact bottleneck; fit, throughput, context, or tail latency
- next time you see “we train at 8M tokens/sec on 1024 GPUs,” read between the lines: it’s all about how they split the problem
tl;dr: llms are simple, just brutal at scale
- hardware-aware optimization is survival
- the real skill is matching bottleneck to the right parallelism; otherwise you’re just moving the problem
d k retweeted

Surprising properties of low-precision floating point numbers are in the news again!
These numerical formats are ubiquitous in large NNs but new to most programmers.
So I worked with @klyap_ last week to put together this little visualizer: quant.exposed.

d k retweeted
Amazing work by @RidgerZhu and the ByteDance Seed team — Scaling Latent Reasoning via Looped LMs introduces looped reasoning as a new scaling dimension.
🔥 The Ouro model is now runnable on vLLM (nightly version) — bringing efficient inference to this new paradigm of latent reasoning.



A core ingredient in scaling RL and self-improvement is a stream of good tasks. Where do they come from?
🌿NaturalReasoning (arxiv.org/abs/2502.13124) explored using LLMs to curate diverse tasks at scale based on human-written tasks.
🤖Self Challenging Agent (arxiv.org/abs/2506.01716), demonstrated that LLMs can propose useful tasks after interacting with the environment and tools.
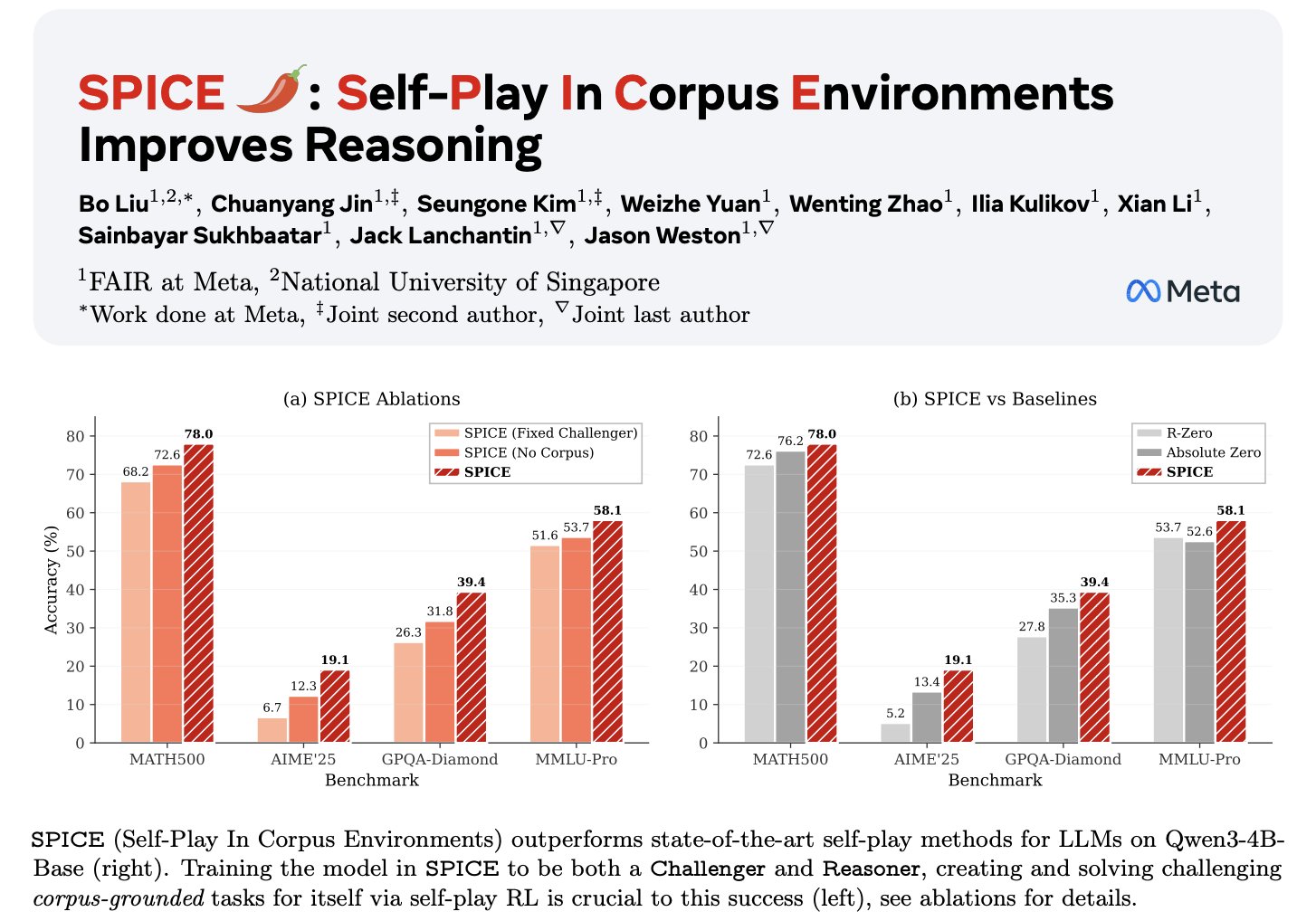
🌶️Our new work SPICE combines insights from both: it creates an automatic curriculum proposing and solving tasks. New tasks are created optimizing for learnability. I'm excited about scaling synthetic tasks in self-improvement to complement other scaling dimensions!
🌶️SPICE: Self-Play in Corpus Environments🌶️
📝: arxiv.org/abs/2510.24684
- Challenger creates tasks based on *corpora*
- Reasoner solves them
- Both trained together ⚔️ -> automatic curriculum!
🔥 Outperforms standard (ungrounded) self-play
Grounding fixes hallucination & lack of diversity
🧵1/6

DataRater: can you automatically+continuously learn which examples will help the model the most?
Fun working on this w/ awesome set of co-authors: @luisa_zintgraf, @dancalian, @greg_far, @iurii_kemae, @matteohessel, @shar_jeremy, @junh_oh, András György, Tom Schaul, @hado, & David Silver.
⬇️

Excited to share our new paper, "DataRater: Meta-Learned Dataset Curation"!
We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models?
Paper: arxiv.org/pdf/2505.17895 to appear @NeurIPSConf
Thread 👇
d k retweeted

In-flight weight updates have gone from a “weird trick” to a must to train LLMs with RL in the last few weeks. If you want to understand the on-policy and throughput benefits here’s the CoLM talk @DBahdanau and I gave: piped.video/Z1uEuRKACRs
d k retweeted

📚The Smol-Training-Playbook tinyurl.com/mr37y2a9 by @huggingface is the definitive guide for building prod-grade LLMs, full of dedicated craftsmanship, Good Job! 🥳
😃Ling team's practice was extensively featured in the MoE session! Quite a delight to help the practitioners!




d k retweeted

You shouldn't do RL on small model.
Distilling from large models works better. And you can now do it even when tokenizers don't match.

On-policy distillation is a promising way to train small models, but it’s usually limited to teacher–student pairs sharing the same tokenizer.
With our GOLD method, you can now distill across different model families and even outperform GRPO!
huggingface.co/spaces/Huggin…

d k retweeted

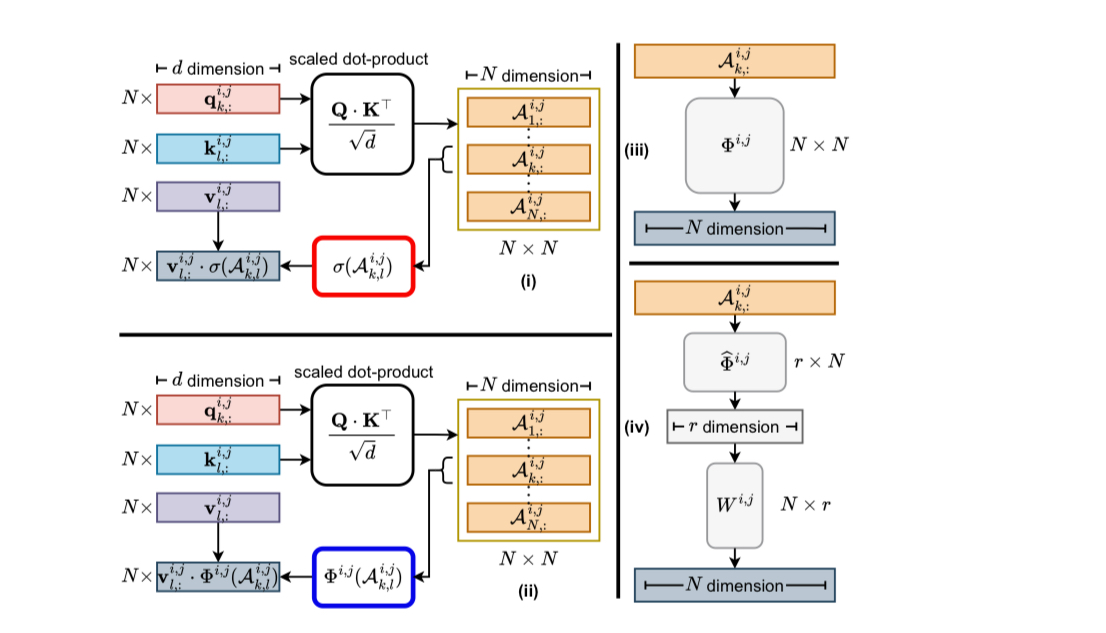
Kolmogorov Arnold Attention is all one needs
🧠🔍 KArAt: Learnable (and more explainable) Attention
This paper swaps the fixed softmax for Kolmogorov-Arnold Attention (KArAt)—a learnable operator.
Why care:
• Clearer attention maps: heads often lock onto whole objects, aiding audits.
• Interpretability: per-head basis coefficients are inspectable—see how interactions are shaped.
• Practicality: low-rank/modular variants curb memory; accuracy often matches or beats softmax on smaller ViTs, with mixed results on larger/hierarchical models.
Net: a strong proof-of-concept for transparent, learnable attention—not yet an efficiency play, but promising.
Paper: arxiv.org/pdf/2503.10632
#explainableAI #transformers #attention #deeplearning #MLresearch
d k retweeted

How do you do this if teacher/student tokenizers dont match

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost.
thinkingmachines.ai/blog/on-…

d k retweeted

💡Some fun facts about Minimax M2:
1. Minimax uses GPT-OSS-like structure, i.e., Full Attention interleaved with Sliding Window Attention (SWA).
2. It uses QK Norm, and every single attention head has its own unique, learnable RMSNorm.
3. The full attention and SWA parts don't even share settings: they each get their own RoPE theta config.
One more thing... Someone may ask why not use linear attention (additive rule or delta rule arxiv.org/abs/2102.11174)?
⚡️The answer is clear: FlashAttention (Dao et al.) is so effective, supporting low-precision training and inference (FP8/FP4), whereas Linear Attention does not work under low precision!
Glad to see more and more AI Labs are doing real science, instead of Pride and Prejudice! 😃



