

Simplifying LLMs, AI Agents, RAG, and Machine Learning for you! • Co-founder @dailydoseofds_• BITS Pilani • 3 Patents • ex-AI Engineer @ LightningAI
Learn AI Engineering 👉
Joined July 2012
- Tweets 19,634
- Following 461
- Followers 233,836
- Likes 21,498

Fine-tune DeepSeek-OCR on your own language!
(100% local)
DeepSeek-OCR is a 3B-parameter vision model that achieves 97% precision while using 10× fewer vision tokens than text-based LLMs.
It handles tables, papers, and handwriting without killing your GPU or budget.
Why it matters:
Most vision models treat documents as massive sequences of tokens, making long-context processing expensive and slow.
DeepSeek-OCR uses context optical compression to convert 2D layouts into vision tokens, enabling efficient processing of complex documents.
The best part?
You can easily fine-tune it for your specific use case on a single GPU.
I used Unsloth to run this experiment on Persian text and saw an 88.26% improvement in character error rate.
↳ Base model: 149% character error rate (CER)
↳ Fine-tuned model: 60% CER (57% more accurate)
↳ Training time: 60 steps on a single GPU
Persian was just the test case. You can swap in your own dataset for any language, document type, or specific domain you're working with.
I've shared the complete guide in the next tweet - all the code, notebooks, and environment setup ready to run with a single click.
Everything is 100% open-source!

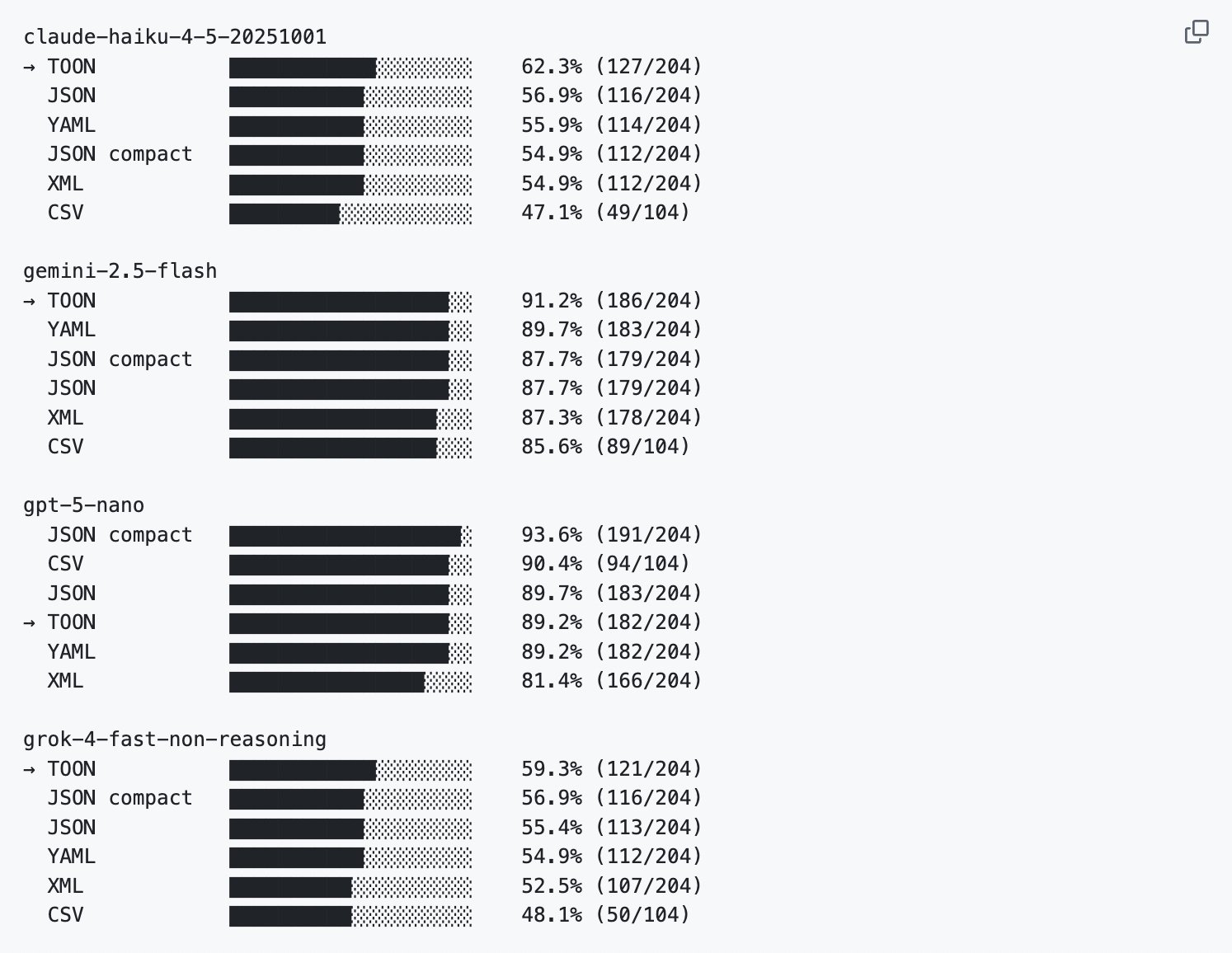
Here are the benchmarks for token efficiency and retrieval accuracy as provided by the Toon team.
You can find the same information in their GitHub repo: github.com/toon-format/toon

A simple trick cuts your LLM costs by 50%!
Just stop using JSON and use this instead:
TOON (Token-Oriented Object Notation) slashes your LLM token usage in half while keeping data perfectly readable.
Here's why it works:
TOON's sweet spot: uniform arrays with consistent fields per row. It merges YAML's indentation and CSV's tabular structure, optimized for minimal tokens.
Look at the example below.
JSON:
{
"𝘂𝘀𝗲𝗿𝘀": [
{ "𝗶𝗱": 𝟭, "𝗻𝗮𝗺𝗲": "𝗔𝗹𝗶𝗰𝗲", "𝗿𝗼𝗹𝗲": "𝗮𝗱𝗺𝗶𝗻" },
{ "𝗶𝗱": 𝟮, "𝗻𝗮𝗺𝗲": "𝗕𝗼𝗯", "𝗿𝗼𝗹𝗲": "𝘂𝘀𝗲𝗿" }
]
}
Toon:
𝘂𝘀𝗲𝗿𝘀[𝟮]{𝗶𝗱,𝗻𝗮𝗺𝗲,𝗿𝗼𝗹𝗲}:
𝟭,𝗔𝗹𝗶𝗰𝗲,𝗮𝗱𝗺𝗶𝗻
𝟮,𝗕𝗼𝗯,𝘂𝘀𝗲𝗿
It's obvious how few tokens are being used to represent the same information!
To summarise, here are the key features:
💸 30–60% fewer tokens than JSON
🔄 Borrows the best from YAML & CSV
🤿 Built-in validation with explicit lengths & fields
🍱 Minimal syntax (no redundant braces, brackets, etc.)
IMPORTANT!!
That said, for deeply nested or non-uniform data, JSON might be more efficient.
In the next tweet, I've shared some benchmark results demonstrating the effectiveness of this technique in reducing the number of tokens and improving retrieval accuracy with popular LLM providers.
Where do you think this could be effective in your existing workflows?
Find the relevant links in the next tweet!

ReAct is really popular. Here's an example from CrewAI, which uses ReAct to let LLM think through problems and use tools to act on the world.


As usual, Anthropic just published another banger.
This one is on building efficient agents that handle more tools while using fewer tokens.
Agents scale better by writing code to call tools and the article explains how to use MCP to execute this code.
A must-read for AI devs!

XBOW raised $117M to build AI hacking agents.
Now someone just open-sourced it for FREE.
Strix deploys autonomous AI agents that act like real hackers - they run your code dynamically, find vulnerabilities, and validate them through actual proof-of-concepts.
Why it matters:
The biggest problem with traditional security testing is that it doesn't keep up with development speed.
Strix solves this by integrating directly into your workflow:
↳ Run it in CI/CD to catch vulnerabilities before production
↳ Get real proof-of-concepts, not false positives from static analysis
↳ Test everything: injection attacks, access control, business logic flaws
The best part?
You don't need to be a security expert. Strix includes a complete hacker toolkit - HTTP proxy, browser automation, and Python runtime for exploit development.
It's like having a security team that works at the speed of your CI/CD pipeline.
The best part is that the tool runs locally in Docker containers, so your code never leaves your environment.
Getting started is simple:
- pipx install strix-agent
- Point it at your codebase (app, repo, or directory)
Everything is 100% open-source!
I've shared link to the GitHub repo in the replies!

RAG vs. CAG, clearly explained!
RAG is great, but it has a major problem:
Every query hits the vector database. Even for static information that hasn't changed in months.
This is expensive, slow, and unnecessary.
Cache-Augmented Generation (CAG) addresses this issue by enabling the model to "remember" static information directly in its key-value (KV) memory.
Even better? You can combine RAG and CAG for the best of both worlds.
Here's how it works:
RAG + CAG splits your knowledge into two layers:
↳ Static data (policies, documentation) gets cached once in the model's KV memory
↳ Dynamic data (recent updates, live documents) gets fetched via retrieval
The result? Faster inference, lower costs, less redundancy.
The trick is being selective about what you cache.
Only cache static, high-value knowledge that rarely changes. If you cache everything, you'll hit context limits. Separating "cold" (cacheable) and "hot" (retrievable) data keeps this system reliable.
You can start today. OpenAI and Anthropic already support prompt caching in their APIs.
I have shared a link to OpenAI's prompt caching guide in the replies.
Have you tried CAG in production yet?