
Pinned Tweet

If you're interested in how to keep challenging neural networks throughout training, check out our latest preprint!
#sample_efficiency #scaling_laws


🚀 New Paper Alert!
Can we generate informative synthetic data that truly helps a downstream learner?
Introducing Deliberate Practice for Synthetic Data (DP)—a dynamic framework that focuses on where the model struggles most to generate useful synthetic training examples.
🔥 On ImageNet-1k, DP reduces dataset size by 55 million examples while outperforming prior synthetic benchmarks!
📄Paper: arxiv.org/pdf/2502.15588
🧵Key takeaways ⬇️

Mohammad Pezeshki retweeted

New @AIatMeta paper explains when a smaller, curated dataset beats using everything.
Standard training wastes effort because many examples are redundant or wrong.
They formalize a label generator, a pruning oracle, and a learner.
From this, they derive exact error laws and sharp regime switches.
With a strong generator and plenty of data, keeping hard examples works best.
With a weak generator or small data, keeping easy examples or keeping more helps.
They analyze 2 modes, label agnostic by features and label aware that first filters wrong labels.
ImageNet and LLM math results match the theory, and pruning also prevents collapse in self training.
----
Paper – arxiv. org/abs/2511.03492
Paper Title: "Why Less is More (Sometimes): A Theory of Data Curation"

We show a phase transition for optimal data curation: For strong models, concentrating on difficult samples drives further improvement (LIMO). In contrast, weaker models benefit from the conventional "More is More" where broad data exposure is essential to learn core capabilities


Mohammad Pezeshki retweeted

After nearly 3 years since our NeurIPS paper, SOTA architectures are now adopting NoPE. Kimi Linear uses NoPE for all full-attention layers (not a RoPE hybrid).

The brilliant Kimi Linear paper.
It's a hybrid attention that beats full attention while cutting memory by up to 75% and keeping 1M token decoding up to 6x faster.
It cuts the key value cache by up to 75% and delivers up to 6x faster decoding at 1M context.
Full attention is slow because it compares every token with every other token and stores all past keys and values.
Kimi Linear speeds this up by keeping a small fixed memory per head and updating it step by step like a running summary, so compute and memory stop growing with length.
Their new Kimi Delta Attention adds a per channel forget gate, which means each feature can separately decide what to keep and what to fade, so useful details remain and clutter goes away.
They also add a tiny corrective update on every step, which nudges the memory toward the right mapping between keys and values instead of just piling on more data.
The model stacks 3 of these fast KDA layers then 1 full attention layer, so it still gets occasional global mixing while cutting the key value cache roughly by 75%.
Full attention layers run with no positional encoding, and KDA learns order and recency itself, which simplifies the stack and helps at long ranges.
Under the hood, a chunkwise algorithm plus a constrained diagonal plus low rank design removes unstable divisions and drops several big matrix multiplies, so the kernels run much faster on GPUs.
With the same training setup, it scores higher on common tests, long context retrieval, and math reinforcement learning, while staying fast even at 1M tokens.
It drops into existing systems, saves memory, scales to 1M tokens, and improves accuracy without serving changes.
----
Paper – arxiv. org/abs/2510.26692
Paper Title: "Kimi Linear: An Expressive, Efficient Attention Architecture"

Mohammad Pezeshki retweeted

Tiny Recursion Models 🔁 meet Amortized Learners 🧠
After @jm_alexia’s great talk, realized our framework mirrors it: recursion (Nₛᵤₚ=steps, n,T=1), detach grads but new obs each step → amortizing over long context
Works across generative models, neural processes, & beyond


My prediction is that next-token prediction loss will not last the test of time, and the next frontier models will need richer loss functions. In this paper, we take a step towards that, shifting from predicting a single token to predicting a summary of the future.

[1/9] While pretraining data might be hitting a wall, novel methods for modeling it are just getting started!
We introduce future summary prediction (FSP), where the model predicts future sequence embeddings to reduce teacher forcing & shortcut learning.
📌Predict a learned embedding of the future sequence, not the tokens themselves
Alleviating long context issues:
Iterative Amortized Inference (IAI) refines solutions step-by-step over mini-batches, just like stochastic optimization.
IAI merges:
- Scalability of stochastic opt. (SGD).
- Expressivity of forward-pass amortization (ICL in LLMs).
A notable work on Red Flag Tokens for LLM safety.

📃 New Paper Alert! ✨
A Generative Approach to LLM Harmfulness Mitigation with Red Flag Tokens🚩
What do you think are some major limitations in current safety training approaches?
➡️ We think it's in their design: they rely on completely changing the model's distribution by refusing responses when content seems harmful ("Sorry, I can't answer that"). That hard switch is often brittle, leads to overrefusals, and doesn’t allow recovery from the decision if the prompt was actually benign.
🔥 We propose a post-training method to improve safety while having minimal impact on the generated distribution of natural language. Our method generates a special token excluded from the user’s vocabulary, which we call a red flag🚩token, to signal when conversations with an LLM turn harmful.
🚀 Why this helps?
Cleaner eval: detecting🚩is objective, no judge required.
Built-in generalization: works with in-context learning and transfers to other languages.
Flexible use: we explore using🚩tokens as a hard filter or a soft trigger for safety reasoning. Check out the demo below 👇
See the 🧵 for a deep dive!
🔗 Paper: arxiv.org/pdf/2502.16366

A very nice read. Fixed chunks make ultra-long reasoning feasible. Very nice visualizations too! Congrats to the authors!

Mohammad Pezeshki retweeted

Long reasoning without the quadratic tax: The Markovian Thinker makes LLMs reason in chunks with a bounded state → linear compute, constant memory and it keeps scaling beyond the training limit.
1/6
Mohammad Pezeshki retweeted
It’s clear next-gen reasoning LLMs will run for millions of tokens. RL at 1M needs ~100× compute than 128K. Our Markovian Thinking keeps compute scaling linear instead. Check out Milad’s thread; some of my perspectives below:



Mohammad Pezeshki retweeted

Excited to share that our work has been accepted to #COLM2025!
We're presenting our poster at Poster Session 2 , Tuesday, Oct 7, 4:30–6:30 pm (Poster #68).
If you’re in Montreal for @COLM_conf, I’d love to chat about generalization in LLMs and their underlying biases!

This work has been accepted to #COLM2025 . If you are in Montreal this week for @COLM_conf and would like to chat about this (or anything related to discovery / exploration / RL), drop me a note!
Poster session 2: Tuesday Oct 7, 4:30-6:30pm
Poster number 68
Mohammad Pezeshki retweeted
Introducing RSA 🌀 (Recursive Self-Aggregation): unlocking deep thinking with test-time scaling
🔥 Qwen3-4B + RSA > DeepSeek-R1
📈 Gains across Qwen, Nemo, GPT-OSS
🏆 Benchmarks: Math • Reasoning Gym • Code
⚡ Aggregation-aware RL lets Qwen3-4B surpass o3-mini 🚀
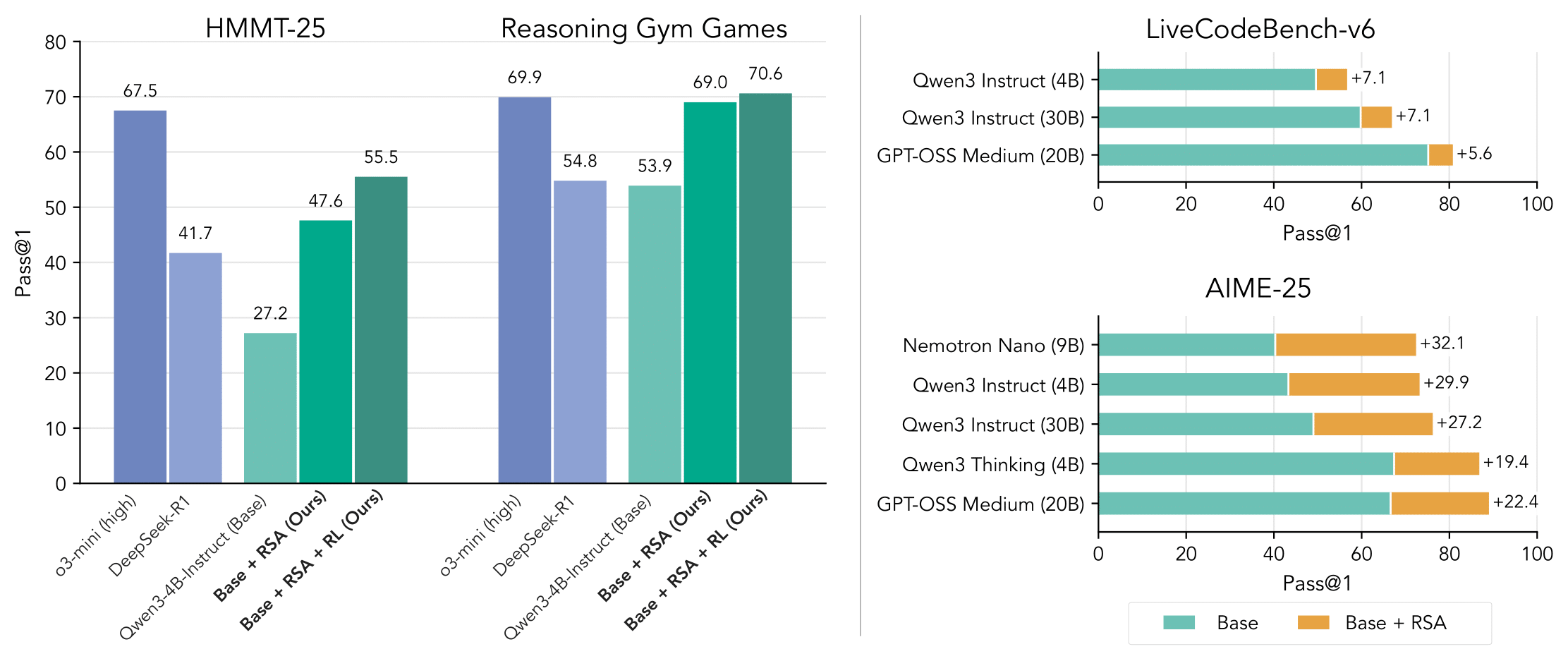
Mohammad Pezeshki retweeted

Thrilled to share recent progress on LLM reasoning methods: generating multiple candidate reasoning traces and recursively refine them. RSA* implements the perfect "brain storm" within single models. Super team from @Mila_Quebec
Probably the first negative results on distillation! Very interesting findings!


Mohammad Pezeshki retweeted

Today I'll teach my very first class at @Concordia. The course is COMP 6321 (Machine Learning). Looking forward to it!
Mohammad Pezeshki retweeted

LLMs are great at single-shot problems, but in the era of experience, interactive environments are key 🔑
Introducing * Multi-Turn Puzzles (MTP) * , a new benchmark to test multi-turn reasoning and strategizing
🔗 Paper: huggingface.co/papers/2508.1…
🫙Data: huggingface.co/datasets/aria…



Today at #ICML2025, we present Deliberate Practice: an approach to improve sample-efficiency by generating harder, not more, examples.
- Oral talk at 10:45
- West Ballroom B | Orals 3C: Data-Centric ML
Join us to discuss principled approaches to more efficient learning.

Excited to present our work "Improving the scaling laws of synthetic data with deliberate practice", tomorrow at #ICML2025
📢 Oral: Wed. 10:45 AM
📍 West Ballroom B (Oral 3C Data-Centric ML)
🖼️ Poster:
🕚 11:00 AM – 1:30 PM
📍 East Exhibition Hall A-B (Poster Session 3 East)
Mohammad Pezeshki retweeted
📄 New Paper Alert! ✨
🚀Mixture of Recursions (MoR): Smaller models • Higher accuracy • Greater throughput
Across 135 M–1.7 B params, MoR carves a new Pareto frontier: equal training FLOPs yet lower perplexity, higher few‑shot accuracy, and more than 2x throughput.
Let’s break it down! 🧵👇
