


sangkilpark retweeted

Pre-training Objectives for LLMs
✓ Pre-training is the foundational stage in developing Large Language Models (LLMs).
✓ It involves exposing the model to massive text datasets and training it to learn grammar, structure, meaning, and reasoning before it is fine-tuned for specific tasks.
✓ The objective functions used during pre-training determine how effectively the model learns language representations.
→ Why Pre-training Matters
✓ Teaches the model general linguistic and world knowledge.
✓ Builds a base understanding of syntax, semantics, and logic.
✓ Reduces data requirements during later fine-tuning.
✓ Enables the model to generalize across multiple domains and tasks.
→ Main Pre-training Objectives
1. Causal Language Modeling (CLM)
✓ Also known as Autoregressive Training, used by models like GPT.
✓ Objective → Predict the next token given all previous tokens.
✓ Example:
→ Input: “The sky is” → Target: “blue”
✓ The model learns word sequences and context flow — ideal for text generation and completion.
✓ Formula (simplified):
→ Maximize P(w₁, w₂, ..., wₙ) = Π P(wᵢ | w₁, ..., wᵢ₋₁)
2. Masked Language Modeling (MLM)
✓ Introduced with BERT, a bidirectional training objective.
✓ Objective → Predict missing words randomly masked in a sentence.
✓ Example:
→ Input: “The [MASK] is blue.” → Target: “sky”
✓ Allows the model to see context from both left and right, capturing deeper semantic relationships.
✓ Formula (simplified):
→ Maximize P(masked_token | visible_tokens)
3. Denoising Autoencoding
✓ Used by models like BART and T5.
✓ Objective → Corrupt the input text (e.g., mask, shuffle, or remove parts) and train the model to reconstruct the original sentence.
✓ Encourages robust understanding and recovery of meaning from noisy or incomplete inputs.
✓ Example:
→ Input: “The cat ___ on the mat.” → Target: “The cat sat on the mat.”
4. Next Sentence Prediction (NSP)
✓ Used alongside MLM in early BERT training.
✓ Objective → Predict whether one sentence logically follows another.
✓ Example:
→ Sentence A: “He opened the door.”
→ Sentence B: “He entered the room.” → Label: True
✓ Helps the model learn coherence and discourse-level relationships.
5. Permutation Language Modeling (PLM)
✓ Used by XLNet, combining autoregressive and bidirectional learning.
✓ Objective → Predict tokens in random order rather than fixed left-to-right.
✓ Enables the model to capture broader context and dependencies without masking.
6. Contrastive Learning Objectives
✓ Used in multimodal and instruction-based pretraining.
✓ Objective → Maximize similarity between semantically related pairs (e.g., a caption and its image) and minimize similarity between unrelated pairs.
✓ Builds robust cross-modal and conceptual understanding.
→ Modern Combined Objectives
✓ Modern LLMs often merge multiple pre-training objectives for richer learning.
✓ Example:
→ T5 uses denoising + text-to-text generation.
→ GPT-4 expands causal modeling with instruction-tuned objectives and reinforcement learning (RLHF).
✓ These hybrid objectives enable models to perform a wide range of generative and comprehension tasks effectively.
→ Quick tip
✓ Pre-training objectives teach LLMs how to predict, reconstruct, and reason over text.
✓ CLM → next-word prediction.
✓ MLM → masked token recovery.
✓ Denoising & NSP → structure and coherence.
✓ Contrastive → cross-domain learning.
✓ Together, they form the foundation for the deep understanding and fluency that define modern LLMs.
📘 Grab this ebook to Master LLMs :
codewithdhanian.gumroad.com/…






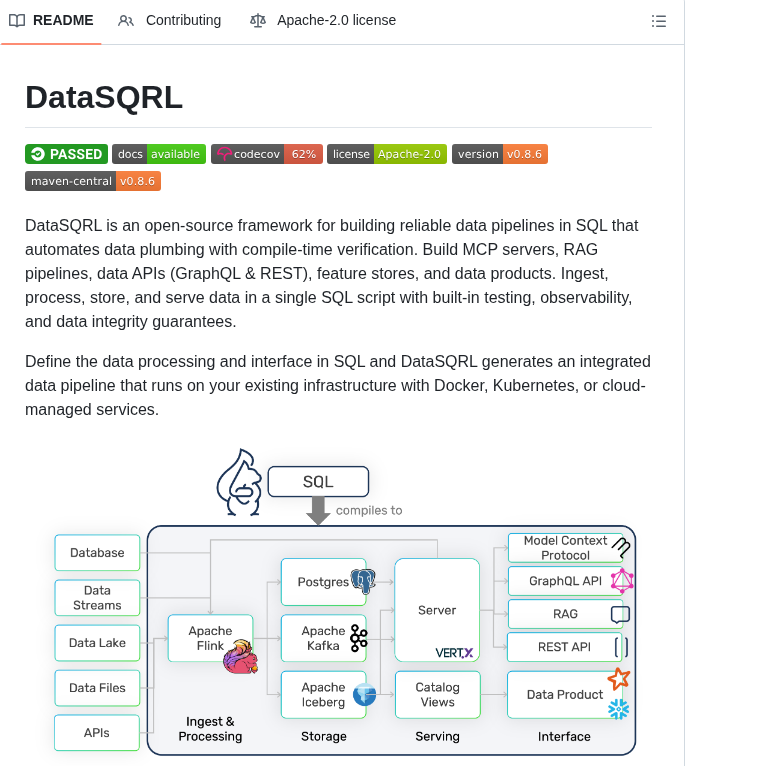
sangkilpark retweeted

A simple trick cuts your LLM costs by 50%!
Just stop using JSON and use this instead:
TOON (Token-Oriented Object Notation) slashes your LLM token usage in half while keeping data perfectly readable.
Here's why it works:
TOON's sweet spot: uniform arrays with consistent fields per row. It merges YAML's indentation and CSV's tabular structure, optimized for minimal tokens.
Look at the example below.
JSON:
{
"𝘂𝘀𝗲𝗿𝘀": [
{ "𝗶𝗱": 𝟭, "𝗻𝗮𝗺𝗲": "𝗔𝗹𝗶𝗰𝗲", "𝗿𝗼𝗹𝗲": "𝗮𝗱𝗺𝗶𝗻" },
{ "𝗶𝗱": 𝟮, "𝗻𝗮𝗺𝗲": "𝗕𝗼𝗯", "𝗿𝗼𝗹𝗲": "𝘂𝘀𝗲𝗿" }
]
}
Toon:
𝘂𝘀𝗲𝗿𝘀[𝟮]{𝗶𝗱,𝗻𝗮𝗺𝗲,𝗿𝗼𝗹𝗲}:
𝟭,𝗔𝗹𝗶𝗰𝗲,𝗮𝗱𝗺𝗶𝗻
𝟮,𝗕𝗼𝗯,𝘂𝘀𝗲𝗿
It's obvious how few tokens are being used to represent the same information!
To summarise, here are the key features:
💸 30–60% fewer tokens than JSON
🔄 Borrows the best from YAML & CSV
🤿 Built-in validation with explicit lengths & fields
🍱 Minimal syntax (no redundant braces, brackets, etc.)
IMPORTANT!!
That said, for deeply nested or non-uniform data, JSON might be more efficient.
In the next tweet, I've shared some benchmark results demonstrating the effectiveness of this technique in reducing the number of tokens and improving retrieval accuracy with popular LLM providers.
Where do you think this could be effective in your existing workflows?
Find the relevant links in the next tweet!

sangkilpark retweeted

Scaling Agent Learning via Experience Synthesis
📝: arxiv.org/abs/2511.03773
Scaling training environments for RL by simulating them with reasoning LLMs!
Environment models + Replay-buffer + New tasks = cheap RL for any environments!
- Strong improvements over non-RL-ready environments and multiple model families!
- Works better in sim-2-real RL settings → Warm-start for high-cost environments
🧵1/7



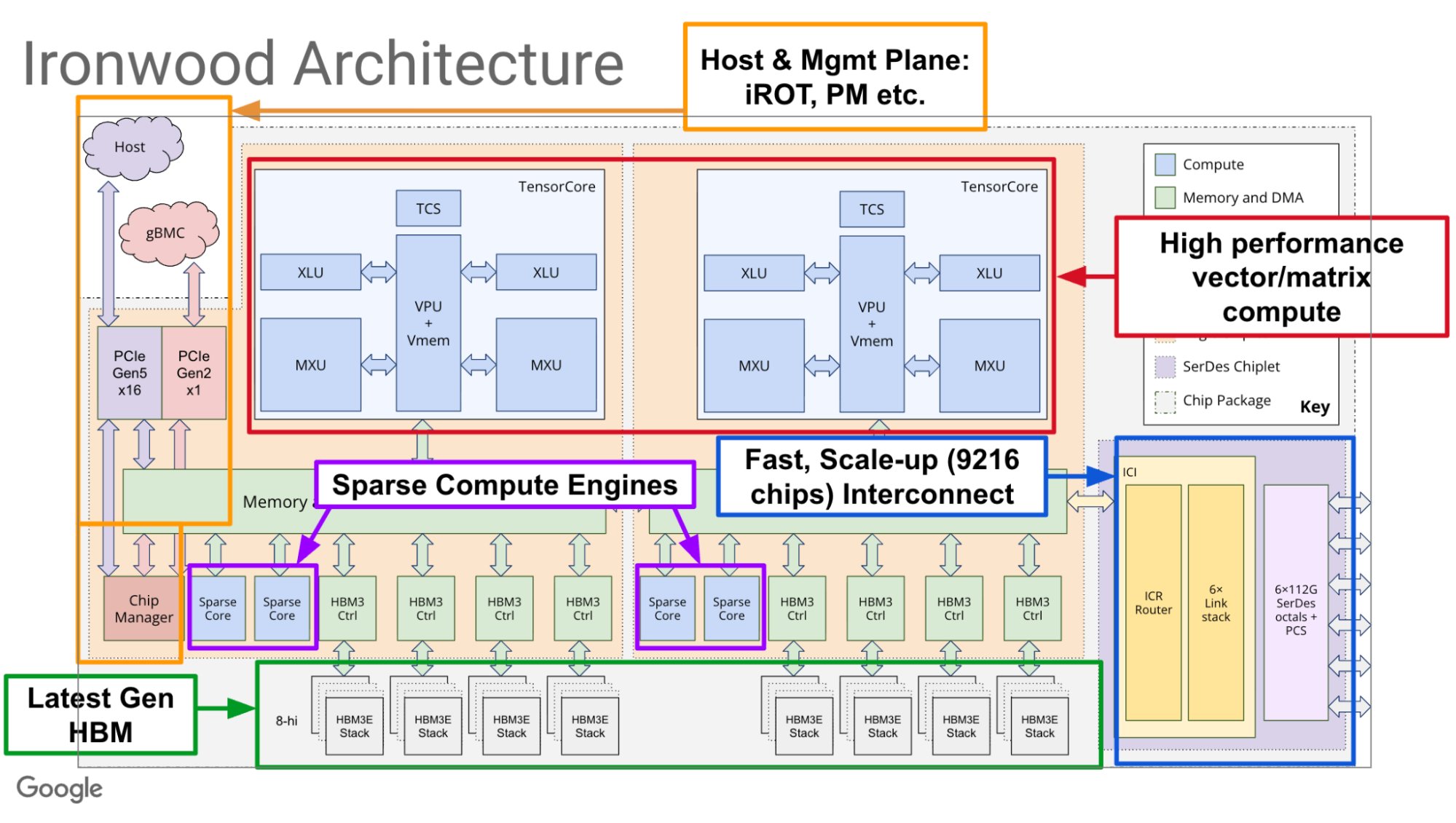
sangkilpark retweeted

From silicon to software, here's a deep dive into Ironwood TPU’s co-designed AI stack → goo.gle/3LoTrHM

sangkilpark retweeted

What happens when you INSERT a row in Postgres?
Postgres needs to ensure that data is durable while maintaining good write performance + crash recovery ability. The key is in the Write-Ahead Log (WAL).
(1) Postgres receives the query and determines what data page to place it in. This could already be in memory (buffer pool), or it may have to load one from disk, or even create a new one.
(2) The new record is written to this page in memory only. The page is marked as “dirty” meaning it needs to get flushed to disk in the future, but not immediately.
(3) A new record is inserted into the memory buffer for the WAL. It contains all the information needed to reconstruct the insert.
(4) The WAL is flushed to disk (via fsync or similar) to ensure the data resides in durable storage. After this succeeds, Postgres return success to the client.
When you get a success at the client, the data has definitely been written to the sequential WAL (good write performance) but not necessarily to the table data file (less predictable I/O patterns). The latter happens later on via checkpointing, background jobs, or forced flushes due to memory page eviction. If a server crash happens before the data is flushed, the log is replayed to restore committed data.
The WAL is the key to all of this! It facilitates high-performance I/O and crash recovery.

sangkilpark retweeted

CamCloneMaster: replicating camera movements from reference videos without needing camera parameters; based on Wan2.1-1.3B; built using a large-scale Camera Clone Dataset. Solid results.
camclonemaster.github.io/


sangkilpark retweeted

KubeDiagrams reads Kubernetes manifests, Helm charts, helmfiles or live cluster state and produces visual architecture diagrams (DOT, SVG, PNG, PDF, etc.), with support for custom resources, clustering, and interactive views
➤ ku.bz/kJ7zQXF13







sangkilpark retweeted

🤖 Deep Agents JS
Deep Agents is now available in JS! Written on top of LangChain and LangGraph 1.0, this brings the power of agents harnesses to the JS ecosystem
Comes with planning tools, subagents, and filesystem access
Try it out now: npm i deepagents
Repo: github.com/langchain-ai/deep…
Docs: docs.langchain.com/oss/javas…

