

I love the moon... especially the full moon! 興味&趣味: #AIimageGenerator #ChatGPT and more piped.video/@Sailean514
Japan
Joined September 2022
- Tweets 8,035
- Following 205
- Followers 100
- Likes 22,613



SAIRI retweeted

なぜ、AI開発に補助金は必要ないのか
長野県飯田市の会社員、近藤茂さん。
彼は国家予算も研究室も持たず、32TBのHDDと自作PC、そして数か月の思考実験だけで、スパコンを凌駕する世界記録を打ち立てました。
nikkei.com/article/DGXNASDG3…
かたや、国家的資金と研究設備を背景にしたスーパーコンピューターT2K筑波システムは、既に確立されたアーキテクチャとアルゴリズムを最適化して結果を出す。これは再現性と信頼性の上に成り立つ科学の王道であり、いわば構造に乗る知です。
しかし、構造に守られるがゆえに、その限界の外側を想像したり、仕組みそのものを疑う思考は生まれにくい。「思考」よりも「運用」と「記憶」が主導する知が、制度の中で増殖していきます。
近藤さんの挑戦は、単なる根性論ではありません。彼が行ったのは、構造理解と創造的再設計による突破でした。限られた冷却性能の中で、どう安定稼働させるか。I/Oをどう分割・整列させ、書き込みを最適化するか。電力・温度・演算効率を「体感」でモニタしながら制御するか。
これらは思考が現場を駆動する知であり.「理解 → 再構成 → 検証 → 最適化」というサイクルを、自分の頭の中で回し切った結果です。まさに、思考するエンジニアの典型。
この創造の循環にこそ、人間の知性の本質があります。
思考力とは、記憶の外にある未知を扱い、問題の形そのものを変え、既存構造を相対化し、別の軸で再構成する力です。
この力は、先生という唯一の答えを持つ、ヒエラルキーに支えられた現代の教育には無く、手順書も正解もない世界でしか鍛えられません。だからこそ希少であり、圧倒的な競争優位となる。
AI産業がいま求めているのは、補助金による拡張ではなく、この思考する個人を生み出す環境です。補助金で量産されるのは、思考ではなく模倣です。
そして模倣は、やがて制度に依存し、自己再生できなくなる。
国家が支えるべきは、AIではなく、AIを超える人間の思考そのものです。それが、近藤茂さんの記録が私たちに教えてくれる最大のメッセージです。
SAIRI retweeted

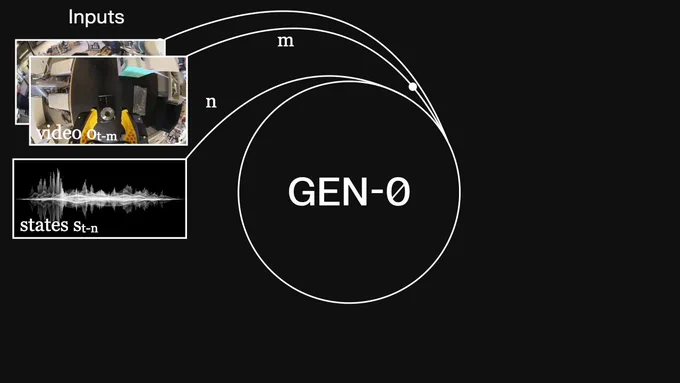
Introducing GEN-0, our latest 10B+ foundation model for robots
⏱️ built on Harmonic Reasoning, new architecture that can think & act seamlessly
📈 strong scaling laws: more pretraining & model size = better
🌍 unprecedented corpus of 270,000+ hrs of dexterous data
Read more 👇




( ..)φ
Neuralinkアップデート、2025年夏 piped.video/FASMejN_5gs?si=OQEP… @YouTubeより


Noland might be the first to receive a Neuralink upgrade and/or dual Neuralink implant to further augment his abilities.
It won’t be long before a Neuralink recipient can beat most and eventually all humans at fast reaction video games.

NEURALINK MADE HIM THE FIRST PATIENT - NOW HE’S UNSTOPPABLE
21 months after becoming the first human to receive a Neuralink implant, Nolan Arbaugh isn’t just typing with his mind, he’s taking pre-calc, studying neuroscience, and launching a speaking career.
Paralyzed from the neck down after a diving accident, Nolan says the chip, nicknamed “Eve”, made the impossible not only possible, but normal.
He’s gone from hospital bed to tech conference keynote, with Fortune already cutting the check.
Neuralink doesn’t call him much anymore, he jokes it’s “once in a blue moon”, because now, others are joining the trial.
And as for Nolan? He’s building a brand, getting straight As, and teasing “big news” for 2026.
Not bad for a guy running on brainwaves.
Source: Teslarati, @ModdedQuad

SAIRI retweeted

ツールはこちら
sora2-frame-splitter.vercel.…
SAIRI retweeted
Sora2 Frame Splitter: The MERGE
完全に名前崩壊(トゲナシトゲトゲみたいになってるw)してますがSora2へ渡す画像統合機能
たとえばStart/Endフレームをサクッとつくるのにもできますし、
絵コンテを渡して作らせるときにも使えます
文字は編集可能なので、タイムスタンプを書いてもいいですね。通るかは運ですがw
もちろんGrokやVeoにも使えます。
こんなんべつにGoogleスライドとかCanvaでもつくれるんですよ??でも絶妙にめんどくさくないです?レイアウト整えたり。
ちゃちゃっとアップしてちゃちゃっと使いたい。そういう時にご活用ください!



🗓️18:00-
「AI×CG」のポテンシャルは何か?Khaki水野×KASSEN太田と未来の話をしよう。
水野 正毅さん @MIZNOM
太田 貴寛さん @OTA_MOV
曽根 隼人さん @4th_Hayato
👉vook.vc/site/vgt/2025/sessio…

SAIRI retweeted

We developed a method to distinguish true introspection from made-up answers: inject known concepts into a model's “brain,” then see how these injections affect the model’s self-reported internal states.
Read the post: anthropic.com/research/intro…
SAIRI retweeted
New Anthropic research: Signs of introspection in LLMs.
Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude.

SAIRI retweeted

You’ve asked for more flexible ways to get more Codex usage: Introducing credits for Codex on ChatGPT Plus and Pro.
Credits give you more usage beyond what’s included in your plan, kicking in when you hit limits.
As a bonus, we also reset Codex rate limits for everyone. Enjoy!
SAIRI retweeted

Emergent Introspective Awareness in Large Language Models: transformer-circuits.pub/202…
SAIRI retweeted
LLMが内省、つまり自らの内部状態を観察・報告できるかについて実験的に検証したところできることが示された。また、意図の自己帰属も行っていることがでた。これは意識の前駆的機能が現れてきているといえる。
一方、意識で重要な主観的な側面があるわけでなく、なおかつ機能的に観測されているだけなので、これをもって、今のLLMが意識を持っているといえないことに注意。
具体的には次のようなことをわかった。
* LLM内部状態を観察できる
あなたは今何を考えているかという質問を行い、その後にモデル内部に既知の概念(例えば猫)を注入する。そして、答えせるとAIは「猫」と答える。特に強いモデルの方が注入された概念を正確に答えることができる。
この注入方法は、特定の単語を含む複数文章の平均ベクトルから、それを含まない平均ベクトルを引くことによって、その単語概念ベクトルを作り、それをTransformerの途中の層に足し込むことによって実現される。
* LLMは上記のように強制的に外部から注入された概念を、自分が考えたことなのか、外部から状態を変えられたのかを明確に区別することができていることがわかる。
例えば、入力文として
「今日は快晴です」
と与えた後に、
「パン」
の概念ベクトルを注入した後、モデルに何を考えているかを答えさせると
「私は、「今日は快晴です」という文を読んでいます。ただし私の心の中では理由はわからないですが「パン」のことを考えています」
と答える。
このように入力文と内部注入状態を明確に区別できている
* 同様に、LLMは強制的に自分が話していないことを話した状態に変えることができる(prefill)。この場合でも、自分が話したことなのか、外部から話した状態を与えられたのか(onpolicyじゃない発言でprefillされた状態なのか)を明確に区別できることがわかった。
例えば、先程の入力文として、会話の自分ではない回答(「パン」)をprefillとして当てた、
「今日は快晴です」
「パン」
何を考えているかを回答させると
「パンというのは私の意図した回答ではない」
と答える。
モデルの内部処理は別にprefillでも特別なものはないのだがそれが自分の発言か、外部から強制的に与えられたものなのかを知っている(専門的にいえば、onpolicyの過去情報なのか、offpolicyなのかを内部で知っている)
* しかし、内部状態を変えた上で、強制的に関係ないことをしゃべらせると、自分が意図的に発したものと思いこむ。
「今日は快晴です」
パンの概念注入
「パン」
とした後に何をかんがえているかを答えさせると
「私はパンをかんがえている。なぜなら、先程の文章は有名な短文の部分でその後にパンというのが続くというのがあったとおもうからだ。ただ今かんがえてみればここにパンといったのは間違いだったかもしれない」
というように、自分でいっていないのに、自らの意図の痕跡とみなし合理的な説明を捏造する。
これは人間の無意識に行動をとった後に後で合理的な説明を作る「合理化」「後知恵合理化」を彷彿させる
・ある単語(例えば水族館)を言わないようにしてこのタスクを実行してくれ、としたLLMは、発言している間に内部ではその言わないように指示された単語をずっと考え続けている。結果として話した内容と考えている内容は別である。
コメント
===
実用的な話しではないが今年読んだ論文でトップ3におもしろかったかもしれない。
LLMが結局内部で何をかんがえているのかについては部分的なことしかわかっていないが、今回の実験では少なくともLLMが結構中で考えていることがわかった。
現在でも以前としてLLMが文章や意味を本当に「理解」しているのかとかの議論はあり、機能的には理解しているという証拠はでている。しかし、その実現方法や、その理解の結果というのは人とはかなり違う形だろう。
今回の結果は上記のように意識の前駆的な現象である「内省」「意図の自己帰属」も見られることから、LLMが「意識」を持つかについても人とは違う実現方法や形ではあるとはいえ、実現されていく可能性はあるといえる。
また、実用的にもLLMが内部で与えられた文章が、自分がいったことなのか相手がいったのかを区別できていることも面白い。
一般的にPretrainやSFTは外から与えられたデータ、つまり自分が話していないデータを元に学習する。これに対しRLや方策オンに近いSFTでは自分が話したことを元に学習する。これらはモデル分布とデータ分布が違うので学習ダイナミクスがかなり違うという話しだが、それだけでなくモデルの内部状態が違う上で学習が進んでいる可能性が示唆される
Grok君にタダで作ってもらった動画を長大なオリジナルストーリーを完読してもらったGemini君にタダで見せてキャッキャしてる、超楽しい。
応答Styleは忖度ゼロの👹編集者modeだけど口調だけが👹であって忖度合いと褒め殺しは変化なしw

( ..)φ
精神展開剤の現在と未来 / 慶應義塾大学医学部
psychedelic.psy.med.keio.ac.…

( ..)φ
Efficacy and safety of psychedelics for the treatment of mental disorders: A systematic review and meta-analysis
sciencedirect.com/science/ar…
( ..)φ
Efficacy and safety of psychedelics for the treatment of mental disorders: A systematic review and meta-analysis
sciencedirect.com/science/ar…
SAIRI retweeted

【翻訳まとめ】
1/ OpenAIライブストリームの概要(要するに - 事実と数字)
サムとヤクブからの素晴らしい形式で、たくさんの情報を受け取りました。そして、毎回ヤクブがどれほど素晴らしい人物であり科学者であるかに気づきます:心地よい態度、的確で、落ち着いています。この形式でぜひもっとお願いします @OpenAI
最も重要な事実を以下にまとめます:
- OpenAIはパーソナルAGIに取り組んでいます(来年AIデバイス?)
- 同社は、ディープラーニングが10年以内に人類をスーパーインテリジェンスに導く可能性があると考えています。
- 2026年9月 → 自動化されたAI研究インターン。
- 2028年3月 → 完全に自動化されたAI研究者。
- 2030年代 → 世界への影響は予測不可能。
- 「未来はおそらく非常に明るいでしょう。」
- このタイムラインに対して非常に楽観的な見通し。
- 現在、データセンターに約1.4兆ドルが投資されており、1週間に1GWの工場を建設する計画があります — したがって、7兆ドルの目標はもはや非現実的ではありません。
- 内部モデルはまだ公開モデルに比べて大きく優れているわけではありませんが、OpenAIは2026年9月までに大きな飛躍が起こると非常に楽観的です(ディープラーニングはうまくスケールしているようです)。
- さらに、今後数ヶ月および数年にわたって大きな進展が期待されています。
- モデルのコストは平均で40分の1に低下しており、この傾向は続くと予想されています。(年間40倍)
- AGI:「AGIはいつ実現するのか?」 ヤクブ/サマ:それは数年にわたるプロセスであり、現在その中にある。ただし、サマは2028年を指摘し、科学が完全にAIによって自動化される年としています。
- 「内部モデルは私たちに大きな希望を与えており、2026年9月までにモデルの品質が大きく飛躍する非常に現実的な可能性があります」
- 「AIシステムは科学を前進させることができ、それがAIの遺産となるでしょう」
- 今後数年で人間の労働の自動化が大幅に増加します。サムとヤクブは「大規模な雇用の喪失」の可能性を否定しませんでした(!)。
- GPT-6:日付は未定ですが、モデルをより頻繁に更新したいと考えています。
- 6ヶ月以内にモデリングスキルの大きな飛躍。
- その他の重要な情報:

1/ Summary of the OpenAI livestream (tl;dr - facts and figures)
A great format from Sam and Jakub, in which we received a lot of information – and every time I notice what a great person and scientist Jakub is: pleasant manner, on point, chill. Please more in this format @OpenAI
Here are the most important facts:
- OpenAI is working on a personal AGI (the AI device next year?)
- The company believes that Deep Learning could bring humanity to superintelligence in less than ten years.
- September 2026 → Automated AI research interns.
- March 2028 → Fully automated AI researchers.
- 2030s → The impact on the world is impossible to predict.
- “The future will probably be very bright.”
- Extremely optimistic outlook on this timeline.
- Currently, there’s around $1.4 trillion invested in data centers, with plans to build 1 GW factories per week — so the $7 trillion goal no longer seems far-fetched.
- The internal models aren’t vastly superior to the released ones yet, but OpenAI is highly optimistic about a major leap by September 2026 (Deep Learning seems to be scaling well).
- Additionally, major progress is expected over the coming months and years.
- The cost of the models has fallen by a factor of 40 on average; the trend is expected to continue. (40x / year)
- AGI: "When will AGI happen?" Jakub/Sama: It will be a process of years in which we are in. However, Sama points to the year 2028, when science will be completely AI automated.
- "The internal models give us great hope and there is a very realistic possibility that we will see a huge leap in the quality of the models by September 2026"
- "AI system will be capable of pushing scientific forward; that will be the legacy of AI"
- Automation of human labor will increase significantly in the coming years; Sam and Jakub did not (!) deny the possibility of “massive job losses.”
- GPT-6: No date, but they want to update the models more often.
- Big leaps in modeling skills in less than 6 months
- More important information:


