

Joined January 2022
- Tweets 1,723
- Following 1,620
- Followers 117
- Likes 11,950
👨💻 MRTISTER🃏🎲 retweeted

🚨 Google’s new approach makes AI learn, adapt, and remember more like a human brain.
TLDR:
Google Research has introduced a new ML paradigm called Nested Learning, designed to help models learn new tasks without forgetting old ones.
- A proof-of-concept model called “Hope” was built using this approach
- Hope shows better long-context memory and language modeling performance than standard transformers
- The framework introduces “continuum memory systems,” where memory updates occur at different frequency rates
- Experiments show Hope achieves lower perplexity and higher accuracy on reasoning and long-context tasks
- Nested Learning aims to reduce catastrophic forgetting and bring AI closer to human-like continual learning


Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI
@GoogleAI

👨💻 MRTISTER🃏🎲 retweeted

New book from @PacktDataML >>
"Building AI Agents with LLMs, RAG, and Knowledge Graphs — A practical guide to autonomous and modern AI agents"
See it at amzn.to/4622k2h

👨💻 MRTISTER🃏🎲 retweeted

day 100/100 of GPU Programming
Didn't write a kernel today. I spent the day reflecting.
100 days writing kernels and I didn't miss a single day, not one. On some days, I learnt to write new ones, some days I practiced kernels I've written before. I took on something my younger self would never have imagined taking on. In learning how to write kernels, I learnt how to learn.
When I first heard about this challenge from @hkproj, I had zero knowledge about GPU Programming, I barely knew how a GPU looked or worked. I had no experience whatsoever with C/C++. GPU resources were scattered and scarce. And aside from that, my biggest challenge was being GPU poor.
But that didn't stop me, I still decided to take on the challenge. I had no definitive path.
If there's something I've witnessed is that If you solely decide to take something head on, resources will come your way. You don't have to have a very clear path, just get started. You'll get to see the road ahead as you go.
I went from writing and profiling CUDA kernels on Google Colab to finding out about @LeetGPU which accelerated my progress exponentially because I now had some kind of definitive path writing and learning specific types of kernels.
These past 100 days have been my best in terms of Programming. Through this journey, I made friends, got haters, got job offers and learnt so much. X is the best place to be, if you consistently put yourself out there, alike people will show up.
100 days ago I couldn't even write a vector add, fast forward 99 days later, I'm writing FP16 Matrix Multiplication Kernels via WMMA APIs.
There are those who felt going on an 100 day challenge was obnoxious and performative. I didn't find that so, I pushed myself to the limit. I wrote kernels on days I felt burnt-out and depressed. I wrote kernels when I was busy with school and life, some days I didn't play football just so I can get a kernel done. In the process, I learnt to be consistent. I didn't do this for anybody by myself. Before @ludwigABAP and @0xmer_ noticed me and put me out there, I was basically showing my progress to myself(I had about 200 followers). Having more people inspired by my work made it even more fulfilling for me because I had people looking up to me.
So for anyone who want to take on the challenge on study something for 100 days straight, I encourage you and for the people already in the process, keep going.
Put your head down, ignore the voices and accelerate.
You really can just do things!






👨💻 MRTISTER🃏🎲 retweeted

Missing
Norbert Wiener
Alan Turing
Stafford Beer
Ludwig von Bertalanffy
Claude Shannon


👨💻 MRTISTER🃏🎲 retweeted

Can’t believe it — our Princeton AI^2 postdoc Shilong Liu @atasteoff re-built DeepSeek-OCR from scratch in just two weeks 😳 — and open-sourced it. This is how research should be done 🙌 #AI #LLM #DeepSeek #MachineLearning #Princeton @omarsar0 @PrincetonAInews @akshay_pachaar


Discover DeepOCR: a fully open-source reproduction of DeepSeek-OCR, complete with training & evaluation code! #DeepLearning #OCR
👨💻 MRTISTER🃏🎲 retweeted

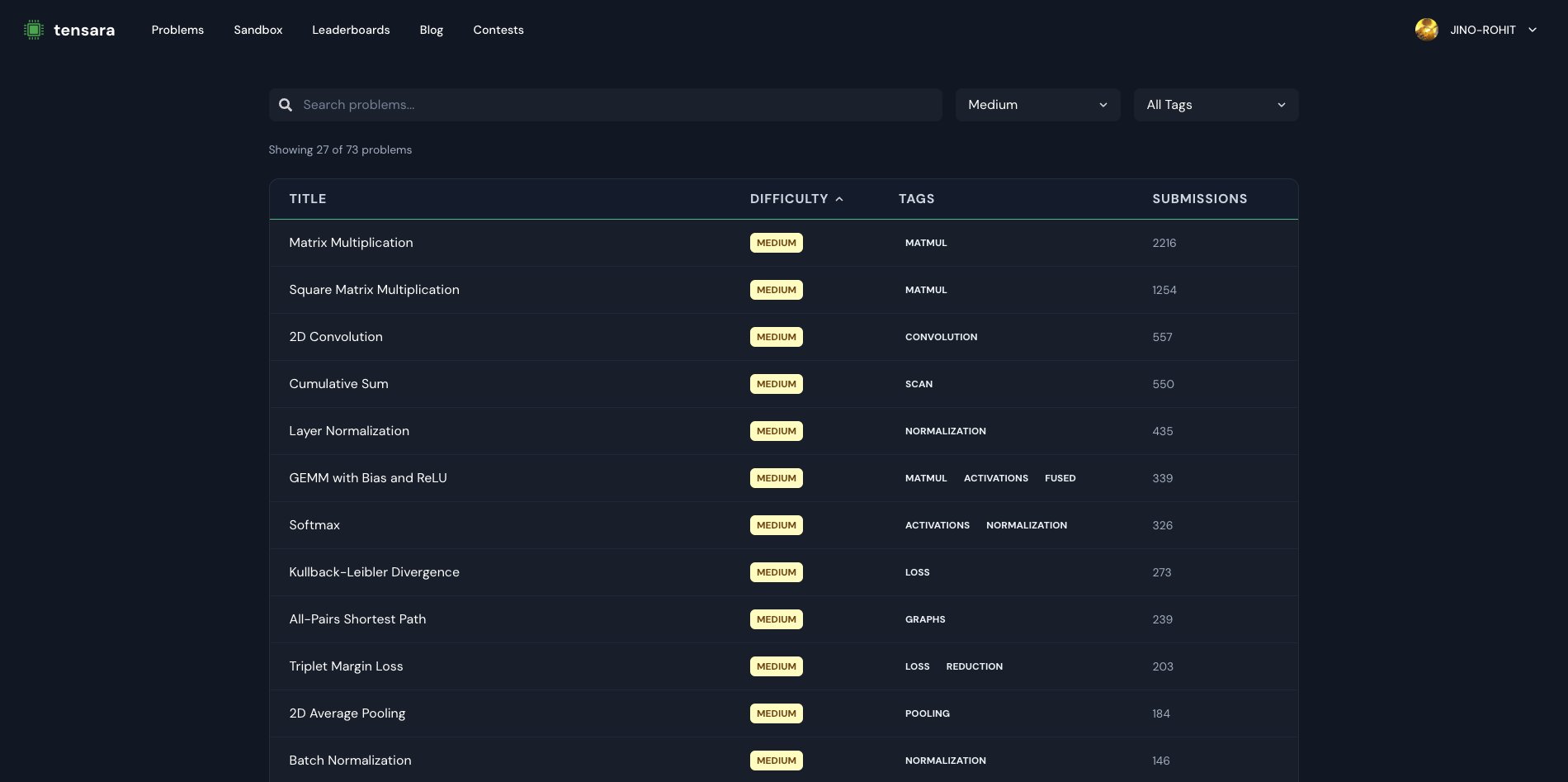
You don't need to buy a GPU to master CUDA.
> Make an account on Tensara.
> Get access to GPUs like H100, A100 for free.
> Practice some of the impactful kernels on the platform.
All you need is a learning mindset.
👨💻 MRTISTER🃏🎲 retweeted

RAG - Retrieval Augmented Generation
Here’s how it works in practice
Knowledge Sources → PDFs, Docs, Databases
Embeddings → your data broken into chunks & vectorized
Vector Database → stores everything for quick retrieval
Retrieval → finds the most relevant context (top-k results)
Augmentation → query + context = stronger prompt
Generation → delivers accurate, context-driven responses
Why it matters?
Because answers backed by your own data are always more reliable, relevant, and trusted.




👨💻 MRTISTER🃏🎲 retweeted

The plug-n-play framework to build MCP Agents (open-source)!
DeepMCPAgent provides dynamic MCP tool discovery to build MCP-powered Agents over LangChain/LangGraph.
You can bring your own model and quickly build production-ready agents.


👨💻 MRTISTER🃏🎲 retweeted

Microsoft.
Google.
AWS.
Everyone's solving the same problem for Agents:
How to build a real-time context layer for Agents across dozens of data sources?
Airweave is an open-source context retrieval layer that solves this!
Learn how this layer differs from RAG below:


You are in an AI engineer interview at Google.
The interviewer asks:
"Our data is spread across several sources (Gmail, Drive, etc.)
How would you build a unified query engine over it?"
You: "I'll embed everything in a vector DB and do RAG."
Interview over!
Here's what you missed:
Devs treat context retrieval like a weekend project.
Their mental model is simple: "Just embed the data, store them in vector DB, and call it a day."
This works beautifully for static sources.
But the problem is that no real-world workflow looks like this.
To understand better, consider this query:
"What's blocking the Chicago office project, and when's our next meeting about it?"
Answering this single query requires searching across sources like Linear (for blockers), Calendar (for meetings), Gmail (for emails), and Slack (for discussions).
No naive RAG setup with data dumped into a vector DB can answer this!
To actually solve this problem, you'd need to think of it as building an Agentic context retrieval system with three critical layers:
> Ingestion layer:
- Connect to apps without auth headaches.
- Process different data sources properly before embedding (email vs code vs calendar).
- Detect if a source is updated and refresh embeddings (ideally, without a full refresh).
> Retrieval layer:
- Expand vague queries to infer what users actually want.
- Direct queries to the correct data sources.
- Layer multiple search strategies like semantic-based, keyword-based, graph-based.
- Ensure retrieving only what users are authorized to see.
- Weigh old vs. new retrieved info (recent data matters more, but old context still counts).
> Generation layer:
- Provide a citation-backed LLM response.
That's months of engineering before your first query works.
It's definitely a tough problem to solve...
...but this is precisely how giants like Google (in Vertex AI Search), Microsoft (in M365 products), AWS (in Amazon Q Business), etc., are solving it.
If you want to see it in practice, this approach is actually implemented in Airweave, a recently trending 100% open-source framework that provides the context retrieval layer for AI agents across 30+ apps and databases.
It implements everything I mentioned above:
- How to handle authentication across apps.
- How to process different data sources.
- How to gather info from multiple tools.
- How to weigh old vs. new info.
- How to detect updates and do real-time sync.
- How to generate perplexity-like citation-backed responses, and more.
For instance, to detect updates and initiate a re-sync, one might do timestamp comparisons.
But this does not tell if the content actually changed (maybe only the permission was updated), and you might still re-embed everything unnecessarily.
Airweave handles this by implementing source-specific hashing techniques like entity-level hashing, file content hashing, cursor-based syncing, etc.
You can see the full implementation on GitHub and try it yourself.
But the core insight applies regardless of the framework you use:
Context retrieval for Agents is an infrastructure problem, not an embedding problem.
You need to build for continuous sync, intelligent chunking, and hybrid search from day one.
I have shared the Airweave repo in the replies!
👨💻 MRTISTER🃏🎲 retweeted

My article on RL fundamentals is now live! Thanks @TDataScience for featuring it in the Editor's pick section!
It goes over everything you need to know to understand research papers and implement RL algorithms. All the academic pre-reqs explained in a simple intuitive way.

👨💻 MRTISTER🃏🎲 retweeted

The paper explains how to make AI decisions clear and easy to audit.
It defines transparency as seeing how a system works and interpretability as understanding why one result happened.
Adds 2 practical ideas, marginal transparency and marginal interpretability, which say extra detail helps less over time.
It reviews simple add-on explainers for black-box models, like LIME for local behavior and SHAP for fair feature credit.
Also covers models that are already clear, like decision trees and purpose-built neural networks that highlight key inputs.
Organizes methods by when and what they explain, before training or after, local cases or global behavior.
Also warns that explanations can leak private data and lists privacy-preserving ways to share only safe signals.
mdpi. com/2673-2688/6/11/285

👨💻 MRTISTER🃏🎲 retweeted

Here's my beginner's lecture series for RAG, Vector Database, Agent, and Multi-Agents: Download slides: 👇
* RAG: byhand.ai/p/beginners-guide-…
* Agents: byhand.ai/p/beginners-guide-…
* Vector Database: byhand.ai/p/beginners-guide-…
* Multi-Agents: byhand.ai/p/beginners-guide-…
---
100% original, made by hand ✍️
Join 47K+ readers of my newsletter: byhand.ai

👨💻 MRTISTER🃏🎲 retweeted
NEW RELEASE from @PacktDataML at amzn.to/4njfsVM
"Learn Model Context Protocol [MCP] with Python: Build agentic systems in Python with the new standard for AI capabilities", by @chris_noring
𝓦𝓱𝓪𝓽 𝓨𝓸𝓾 𝓦𝓲𝓵𝓵 𝓛𝓮𝓪𝓻𝓷:
🟠Understand the MCP protocol and its core components
🔵Build MCP servers that expose tools and resources to a variety of clients
🟠Test and debug servers using the interactive inspector tools
🔵Consume servers using Claude Desktop and Visual Studio Code Agents
🟠Secure MCP apps, as well as managing and mitigating common threats
🔵Build and deploy MCP apps using cloud-based strategies
Also... Purchase of the print or Kindle book includes a free PDF eBook copy




